
Crédito: Shutterstock
La autocorrección, o texto predictivo, es una característica común de muchas herramientas tecnológicas modernas, desde búsquedas en Internet hasta aplicaciones de mensajería y procesadores de texto. La autocorrección puede ser una bendición, pero cuando el algoritmo comete errores, puede cambiar el mensaje de manera dramática y, a veces, divertida.
Nuestra investigación muestra que los errores de autocorrección, particularmente en las hojas de cálculo de Excel, también pueden crear un lío en los nombres de los genes en la investigación genética. Encuestamos más de 10,000 artículos con listas de genes de Excel publicadas entre 2014 y 2020 y encontramos mas de 30% contenía al menos un nombre de gen destrozado por autocorrección.
Esta investigación sigue a nuestro estudio de 2016 que encontró alrededor del 20% de los artículos contenían estos errores, por lo que el problema puede estar empeorando. Creemos que la lección para los investigadores es clara: es hora de dejar de usar Excel y aprender a usar software más poderoso.
Excel hace suposiciones incorrectas
Las hojas de cálculo aplican texto predictivo para adivinar qué tipo de datos desea el usuario. Si escribe un número de teléfono que comienza con cero, lo reconocerá como un valor numérico y eliminará el cero a la izquierda. Si escribe «= 8/2», el resultado aparecerá como «4», pero si escribe «8/2», se reconocerá como una fecha.
Con datos científicos, el simple hecho de abrir un archivo en Excel con la configuración predeterminada puede corromper los datos debido a la autocorrección. Es posible evitar la autocorrección no deseada si las celdas se formatean previamente antes de pegar o importar datos, pero este y otros consejos de higiene de datos no se practican ampliamente.
En genética, fue reconocido en 2004 que es probable que Excel convierta unos 30 genes humanos y nombres de proteínas en fechas. Estos nombres eran cosas como MARZO 1, SEPT1, 4 de octubre, jun, etcétera.
Hace varios años, detectamos este error en archivos de datos complementarios adjuntos a un artículo de revista de alto impacto y nos interesamos en la extensión de estos errores. Nuestro artículo de 2016 indicó que el problema afectó a las revistas de rango medio y alto a tasas aproximadamente iguales. Esto nos sugirió que los investigadores y las revistas desconocían en gran medida el problema de la autocorrección y cómo evitarlo.
Como resultado de nuestro informe de 2016, Human Gene Name Consortium, el organismo oficial responsable de nombrar los genes humanos, cambió el nombre de los genes más problemáticos. MARZO 1 y SEPT1 fueron cambiados a MARZOF1 y SEPTIN1 respectivamente, y otros tuvieron cambios similares.
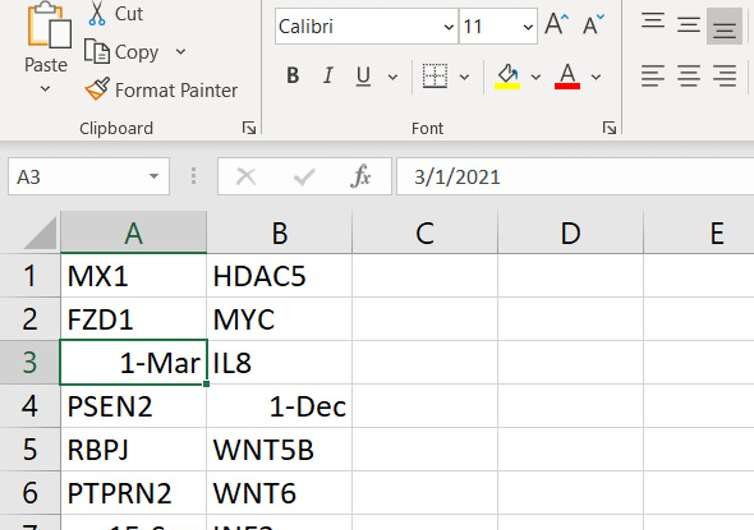
Una lista de ejemplo de nombres de genes en Excel.
Un problema continuo
A principios de este año repetimos nuestro análisis. Esta vez lo ampliamos para cubrir una selección más amplia de revistas de acceso abierto, anticipando que los investigadores y las revistas tomarían medidas para evitar que tales errores aparezcan en sus archivos de datos complementarios.
Nos sorprendió encontrar en el período 2014 a 2020 que 3.436 artículos, alrededor del 31% de nuestra muestra, contenían errores de nombre de gen. Parece que el problema no ha desaparecido y, de hecho, está empeorando.
Los pequeños errores importan
Algunos argumentan que estos errores realmente no importan, porque 30 o más genes son solo una pequeña fracción de los aproximadamente 44,000 en todo el genoma humano, y es poco probable que los errores deriven en conclusiones de cualquier estudio genómico en particular.
Cualquiera que vuelva a utilizar estos archivos de datos complementarios encontrará que este pequeño conjunto de genes falta o está dañado. Esto puede resultar irritante si su proyecto de investigación examina el SEPT familia de genes, pero es solo una de las muchas familias de genes que existen.
Creemos que los errores son importantes porque plantean preguntas sobre cómo estos errores pueden colarse en las publicaciones científicas. Si los errores de autocorrección de nombres de genes pueden pasar la revisión por pares sin ser detectados en archivos de datos publicados, ¿qué otros errores también podrían estar al acecho entre los miles de puntos de datos?
Catástrofes de hojas de cálculo
En los negocios y las finanzas, hay muchos ejemplos en los que los errores de la hoja de cálculo pérdidas costosas y vergonzosas.
En 2012, JP Morgan declaró una pérdida de más de US $ 6 mil millones gracias a una serie de errores comerciales que fueron posibles gracias a errores de fórmula en sus hojas de cálculo de modelado. El análisis de miles de hojas de cálculo en Enron Corporation, desde antes de su espectacular caída en 2001, muestra casi una cuarta parte contenía errores.
Se utilizó un artículo ahora infame de los economistas de Harvard Carmen Reinhart y Kenneth Rogoff para justificar los recortes de austeridad después de la crisis financiera mundial, pero el análisis contenía un error crítico de Excel que llevó a omitir cinco de los 20 países en su modelo.
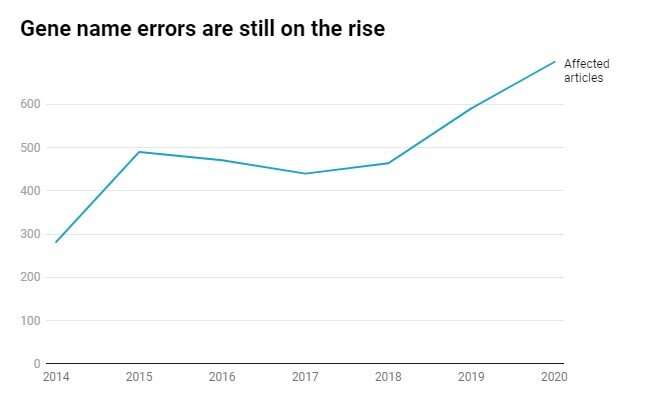
Crédito: Gráfico: Mark Ziemann / The Conversation
El año pasado, un error de hoja de cálculo en Public Health England condujo a la pérdida de datos correspondientes a alrededor de 15.000 casos positivos de COVID-19. Esto comprometió los esfuerzos de rastreo de contactos durante ocho días mientras el número de casos crecía rápidamente. En el ámbito de la atención de la salud, errores de entrada de datos clínicos en hojas de cálculo puede llegar al 5%, mientras que una estudio de hojas de cálculo de administración hospitalaria mostró que 11 de 12 contenían fallas críticas.
En la investigación biomédica, un error al preparar una hoja de muestra resultó en un conjunto completo de etiquetas de muestra que se desplazaron en una posición y cambiar por completo los resultados del análisis genómico. Estos resultados fueron significativos porque se estaban utilizando para justificar los medicamentos que los pacientes iban a recibir en un ensayo clínico posterior. Este puede ser un caso aislado, pero realmente no sabemos qué tan comunes son estos errores en la investigación debido a la falta de estudios sistemáticos de detección de errores.
Hay mejores herramientas disponibles
Las hojas de cálculo son versátiles y útiles, pero tienen sus limitaciones. Las empresas se han movido de las hojas de cálculo a un software de contabilidad especializado, y nadie en TI usaría una hoja de cálculo para manejar datos cuando los sistemas de bases de datos como SQL son mucho más robustos y capaces.
Sin embargo, todavía es común que los científicos usen archivos de Excel para compartir sus datos complementarios en línea. Pero a medida que la ciencia se vuelve más intensiva en datos y las limitaciones de Excel se vuelven más evidentes, puede ser el momento de que los investigadores den inicio a las hojas de cálculo.
En genómica y otras ciencias con gran cantidad de datos, los lenguajes informáticos con secuencias de comandos como Python y R son claramente superiores a las hojas de cálculo. Ofrecen beneficios que incluyen técnicas analíticas mejoradas, reproducibilidad, auditabilidad y una mejor gestión de las versiones de código y las contribuciones de diferentes personas. Puede que sean más difíciles de aprender inicialmente, pero los beneficios de una mejor ciencia valen la pena a largo plazo.
Excel es adecuado para la entrada de datos a pequeña escala y el análisis ligero. Microsoft dice La configuración predeterminada de Excel está diseñada para satisfacer las necesidades de la mayoría de los usuarios, la mayor parte del tiempo.
Claramente, la ciencia genómica no representa un caso de uso común. Cualquier conjunto de datos de más de 100 filas simplemente no es adecuado para una hoja de cálculo.
Los investigadores en campos intensivos en datos (particularmente en las ciencias de la vida) necesitan mejores habilidades informáticas. Iniciativas como Carpintería de software ofrecer talleres a investigadores, pero las universidades también deberían centrarse más en dar a los estudiantes universitarios las habilidades analíticas avanzadas que necesitarán.
Este artículo se vuelve a publicar desde La conversación bajo una licencia Creative Commons. Leer el artículo original.![]()
Citación: Los errores de autocorrección de Excel siguen afectando la investigación genética, lo que genera preocupaciones sobre el rigor científico (27 de agosto de 2021), consultado el 27 de agosto de 2021 en https://techxplore.com/news/2021-08-excel-autocorrect-errors-plague-genetic.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, no se puede reproducir ninguna parte sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.

GIPHY App Key not set. Please check settings