
Latté papel y video | Transformador de trayectoria papel y video | código GitHub
El lenguaje es la forma más intuitiva de expresar cómo nos sentimos y qué queremos. Sin embargo, a pesar de los recientes avances en inteligencia artificial, todavía es muy difícil controlar un robot usando instrucciones en lenguaje natural. Comandos de forma libre como “Robot, ve un poco más lento cuando pases cerca de mi televisor” o “¡Aléjate de la piscina!” son difíciles de analizar en comportamientos de robots accionables, y la mayoría de las interfaces humano-robot todavía se basan en estrategias complejas, como funciones de costos de programación directa que definen el comportamiento deseado.
Con nuestro último trabajo, intentamos cambiar esta realidad a través de la introducción de “LaTTe: Transformador de la trayectoria del lenguaje”. LaTTe es un modelo de aprendizaje automático profundo que nos permite enviar comandos de lenguaje a los robots de forma intuitiva y sencilla. Cuando el usuario le da una oración de entrada, el modelo la fusiona con las imágenes de la cámara de los objetos que el robot observa en su entorno y genera el comportamiento deseado del robot.
Como ejemplo, piense en un usuario que intenta controlar a un barista robot que está moviendo una botella de vino. Nuestro método permite que un usuario no técnico controle el comportamiento del robot solo usando palabras, en una interfaz natural y simple. Explicaremos cómo podemos lograr esto en detalle a través de esta publicación.


Continúe leyendo para obtener más información sobre esta tecnología o consulte estos recursos adicionales:
También invitamos al lector a ver los videos que describen los artículos:
Liberar el potencial del lenguaje para la robótica
El campo de la robótica tradicionalmente utiliza módulos de programación específicos de tareas, que deben ser rediseñados por un experto incluso si hay cambios menores en el hardware, el entorno o los objetivos operativos del robot. Este enfoque inflexible está maduro para la innovación con los últimos avances en aprendizaje automático, que enfatiza módulos reutilizables que se generalizan bien en dominios grandes.
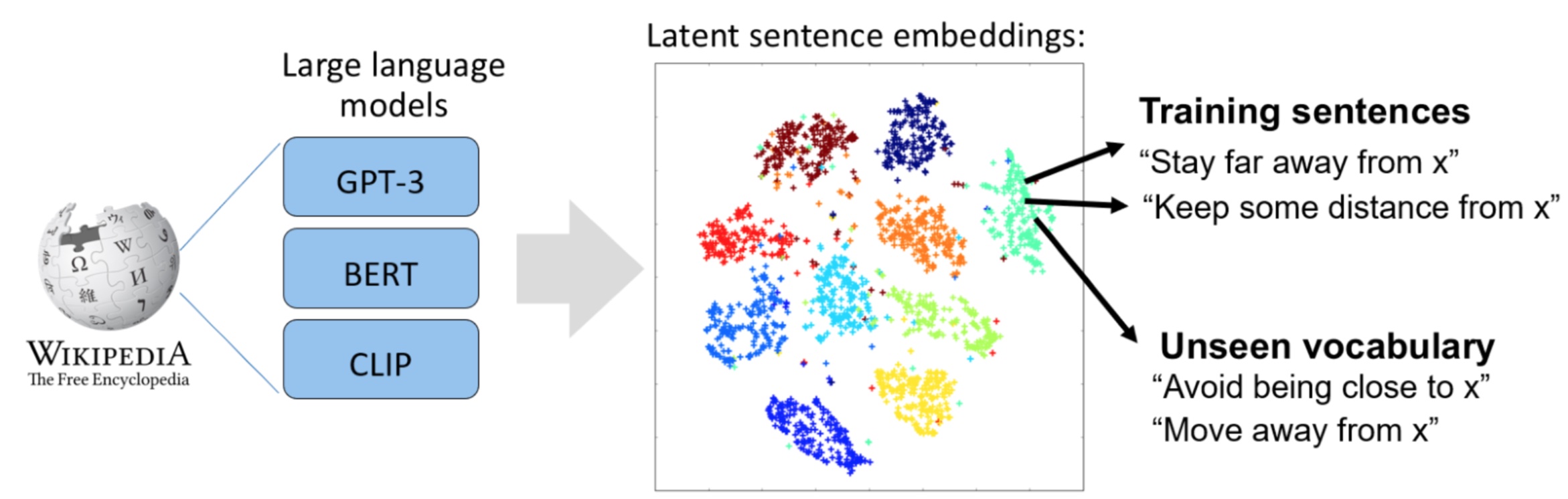
Dada la naturaleza intuitiva y eficaz del lenguaje para la comunicación general, sería más sencillo decirle al robot cómo quiere que se comporte en lugar de tener que reprogramar toda la pila cada vez que se necesita un cambio. Mientras que los grandes modelos de lenguaje como BERT, GPT-3 y Megatron-Turing han mejorado radicalmente la calidad del texto generado por máquina y nuestra capacidad para resolver tareas de procesamiento de lenguaje natural, y modelos como CLIP amplían nuestras capacidades de alcance hacia dominios multimodales con visión y lenguaje, todavía vemos pocos ejemplos de lenguaje siendo aplicado en robótica.
El objetivo de nuestro trabajo es aprovechar la información contenida en los modelos preentrenados de visión-lenguaje existentes para llenar el vacío en las herramientas existentes para la interacción humano-robot. Aunque el lenguaje natural es la forma más rica de comunicación entre humanos, modelar las interacciones entre humanos y robots usando el lenguaje es un desafío porque a menudo necesitamos grandes cantidades de datos para entrenar modelos o, clásicamente, obligar al usuario a operar dentro de un conjunto rígido de instrucciones. Para abordar estos desafíos, nuestro marco hace uso de dos ideas clave: primero, empleamos grandes modelos de lenguaje previamente entrenados para proporcionar representaciones ricas de la intención del usuario, y segundo, alineamos los datos de la trayectoria geométrica con el lenguaje natural junto con el uso de un multi- mecanismo de atención modal.
Probamos nuestro modelo en múltiples plataformas robóticas, desde manipuladores hasta drones, y demostramos que su funcionalidad es independiente del factor de forma, la dinámica y el controlador de movimiento del robot. Nuestro objetivo es permitir que un trabajador de una fábrica reconfigure rápidamente la trayectoria de un brazo robótico más lejos de los objetos frágiles; o permita que el piloto de un dron ordene al dron que disminuya la velocidad cuando esté cerca de edificios, todo sin requerir una gran experiencia técnica.
Combinando lenguaje y geometría en un solo modelo de robótica
Nuestro objetivo general es proporcionar una interfaz flexible para la interacción humano-robot en el contexto de la remodelación de la trayectoria que es independiente de las plataformas robóticas. Suponemos que el comportamiento del robot se expresa a través de una trayectoria 3D a lo largo del tiempo y que el usuario proporciona un comando de lenguaje natural para remodelar su comportamiento que se relaciona con cosas particulares en la escena, como los objetos en el espacio de trabajo del robot. Nuestro sistema de generación de trayectoria genera una secuencia de waypoints en XYZ y velocidades, que se calculan fusionando la geometría de la escena, las imágenes de la escena y la entrada de idioma del usuario. El siguiente diagrama muestra una descripción general del sistema:
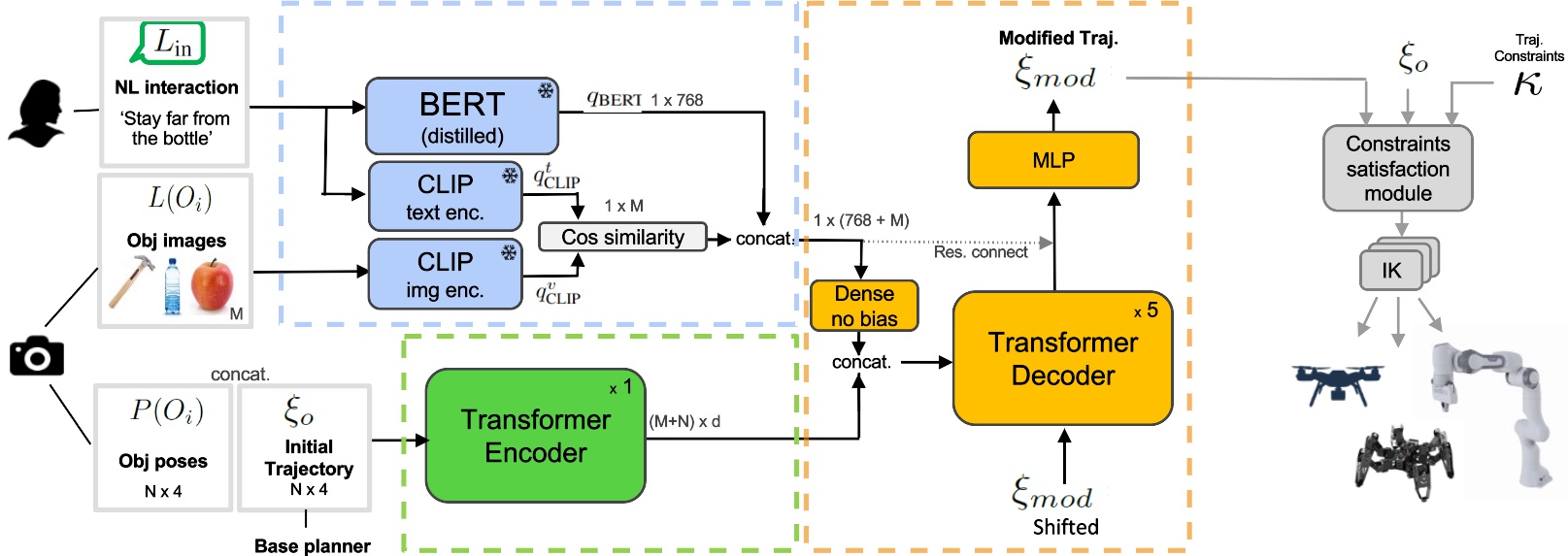
LaTTe se compone de varios bloques de construcción, que se pueden clasificar en extractores de características, codificador geométrico y un decodificador de trayectoria final. Usamos un codificador de modelo de lenguaje previamente entrenado, BERT, para producir características semánticas a partir de la entrada del usuario. El uso de un modelo de lenguaje grande crea más flexibilidad en la entrada de lenguaje natural, lo que permite el uso de sinónimos y menos datos de entrenamiento, dado que el codificador ya ha sido entrenado con un corpus de texto masivo. Además, utilizamos el codificador de texto preentrenado del modelo de visión-lenguaje CLIP para extraer incrustaciones latentes tanto del texto del usuario como de las imágenes de cada objeto en la escena. Luego calculamos un vector de similitud entre las incrustaciones y usamos esta información para identificar los objetos de destino a los que se refiere el usuario a través de su comando de idioma.
En cuanto a la información geométrica, empleamos una red codificadora de Transformer para extraer características relacionadas con la trayectoria del robot original, así como la posición 3D de cada uno de los objetos en la escena. En un escenario práctico, podemos usar detectores de objetos listos para usar para obtener la posición y las imágenes de cada objeto significativo.
Finalmente, toda la información geométrica, lingüística y visual se fusiona en un bloque decodificador de Transformer. De manera similar a lo que sucede en un problema de traducción automática (por ejemplo, traducir una oración del inglés al alemán), el decodificador del transformador utiliza la información de la red del codificador del transformador para generar un punto de referencia de la trayectoria de salida a la vez en un bucle. El proceso de entrenamiento utiliza una variedad de datos sintéticos generados por procedimientos con múltiples formas de trayectoria y categorías de objetos aleatorios. Usamos múltiples imágenes para cada objeto, que obtenemos rastreando la web a través de Imágenes de Bing.
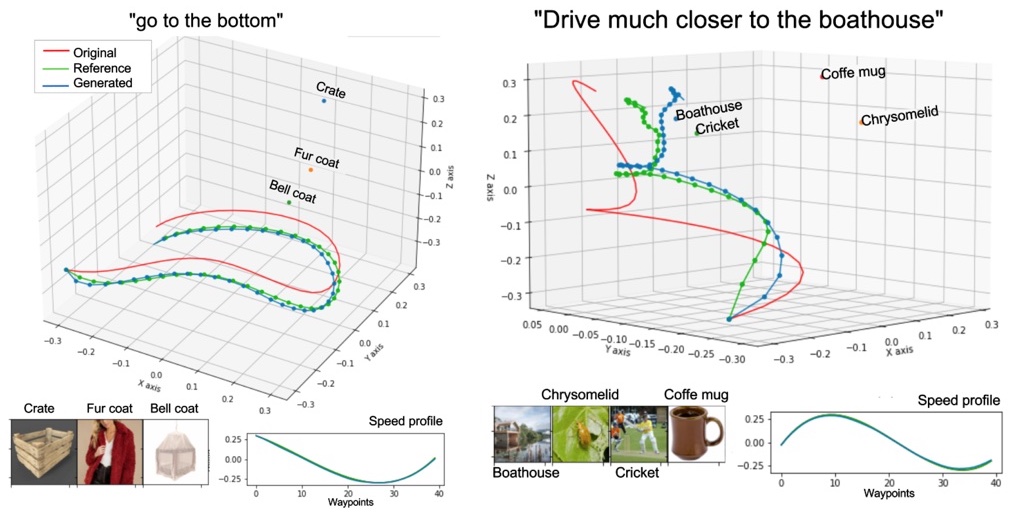
¿Qué podemos hacer con este modelo?
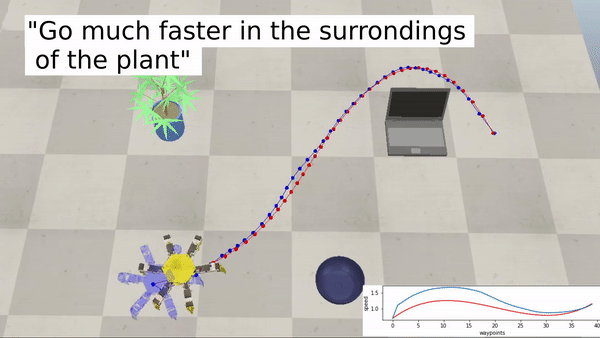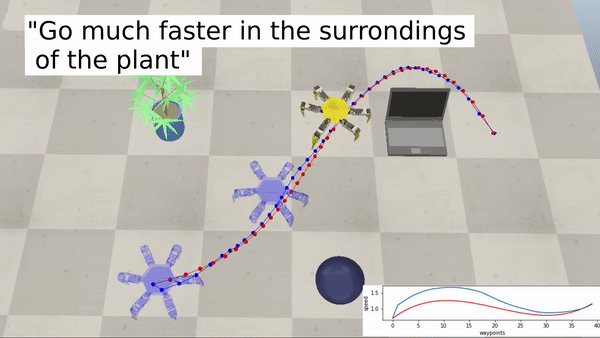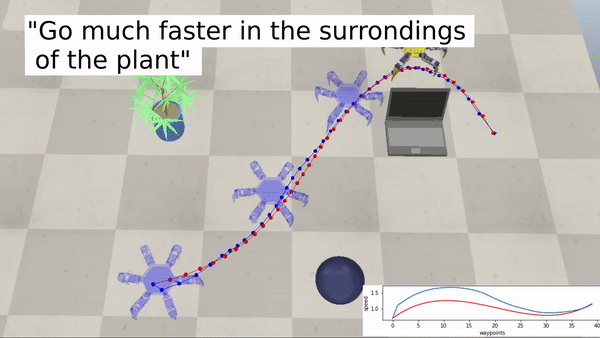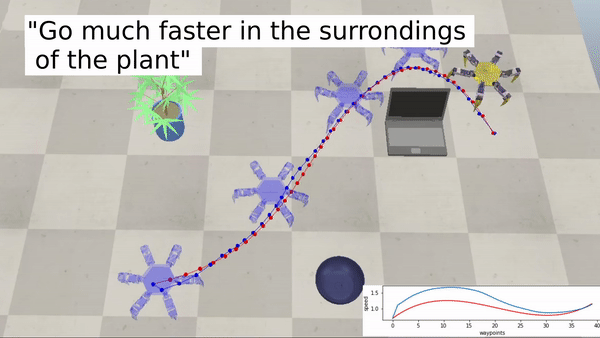
Realizamos varios experimentos en entornos simulados y de la vida real para probar la eficacia de LaTTe. También probamos diferentes factores de forma (manipuladores, drones y un robot hexápodo) en una multitud de escenarios para mostrar la capacidad de LaTTe para adaptarse a varias plataformas de robots.
Ejemplos con manipuladores:


Ejemplos con vehículos aéreos:


Ejemplos con un robot hexápodo:

Acercar la robótica a un público más amplio
Estamos emocionados de lanzar estas tecnologías con el objetivo de llevar la robótica al alcance de un público más amplio. Dadas las crecientes aplicaciones de los robots en varios dominios, es imperativo diseñar interfaces humano-robot que sean intuitivas y fáciles de usar. Nuestro objetivo al diseñar tales interfaces es brindar flexibilidad y precisión de acción, al mismo tiempo que aseguramos que se requiera poca o ninguna capacitación técnica para los usuarios noveles. Nuestro marco de Transformador de trayectoria de lenguaje (LaTTe) da un gran paso adelante en esta dirección.
Este trabajo está siendo realizado por un equipo multidisciplinario de Investigación de sistemas autónomos de Microsoft junto con el Instituto de Robótica e Inteligencia Artificial de Múnich (MIRMI) en la Universidad Técnica de Múnich. Los investigadores incluidos en este proyecto son: Arthur Bucker, Luis Figueredo, Sami Haddadín, Ashish Kapoor, Shuang Ma, Sai Vemprala y Rogelio Bonatti.

