
|
Las innovaciones en el aprendizaje profundo (DL), especialmente el rápido crecimiento de los modelos de lenguaje extenso (LLM), han conquistado la industria. Los modelos DL han crecido de millones a miles de millones de parámetros y están demostrando nuevas y emocionantes capacidades. Están impulsando nuevas aplicaciones como la IA generativa o la investigación avanzada en el cuidado de la salud y las ciencias de la vida. AWS ha estado innovando en chips, servidores, conectividad de centros de datos y software para acelerar tales cargas de trabajo de DL a escala.
En AWS re:Invent 2022, anunciamos la versión preliminar de las instancias Inf2 de Amazon EC2 con tecnología de AWS Inferentia2, el último chip de aprendizaje automático diseñado por AWS. Las instancias Inf2 están diseñadas para ejecutar aplicaciones de inferencia DL de alto rendimiento a escala global. Son la opción más rentable y energéticamente eficiente en Amazon EC2 para implementar las últimas innovaciones en IA generativa, como GPT-J o Transformador preentrenado abierto (OPT) modelos de lenguaje.
Hoy, me complace anunciar que las instancias Inf2 de Amazon EC2 ya están disponibles para el público en general.
Las instancias Inf2 son las primeras instancias optimizadas para inferencia en Amazon EC2 que admiten la inferencia distribuida de escalamiento horizontal con conectividad de ultra alta velocidad entre aceleradores. Ahora puede implementar modelos de manera eficiente con cientos de miles de millones de parámetros en múltiples aceleradores en instancias Inf2. En comparación con las instancias Inf1 de Amazon EC2, las instancias Inf2 ofrecen un rendimiento hasta 4 veces mayor y una latencia hasta 10 veces menor. Aquí hay una infografía que destaca las mejoras de rendimiento clave que hemos puesto a disposición con las nuevas instancias de Inf2:
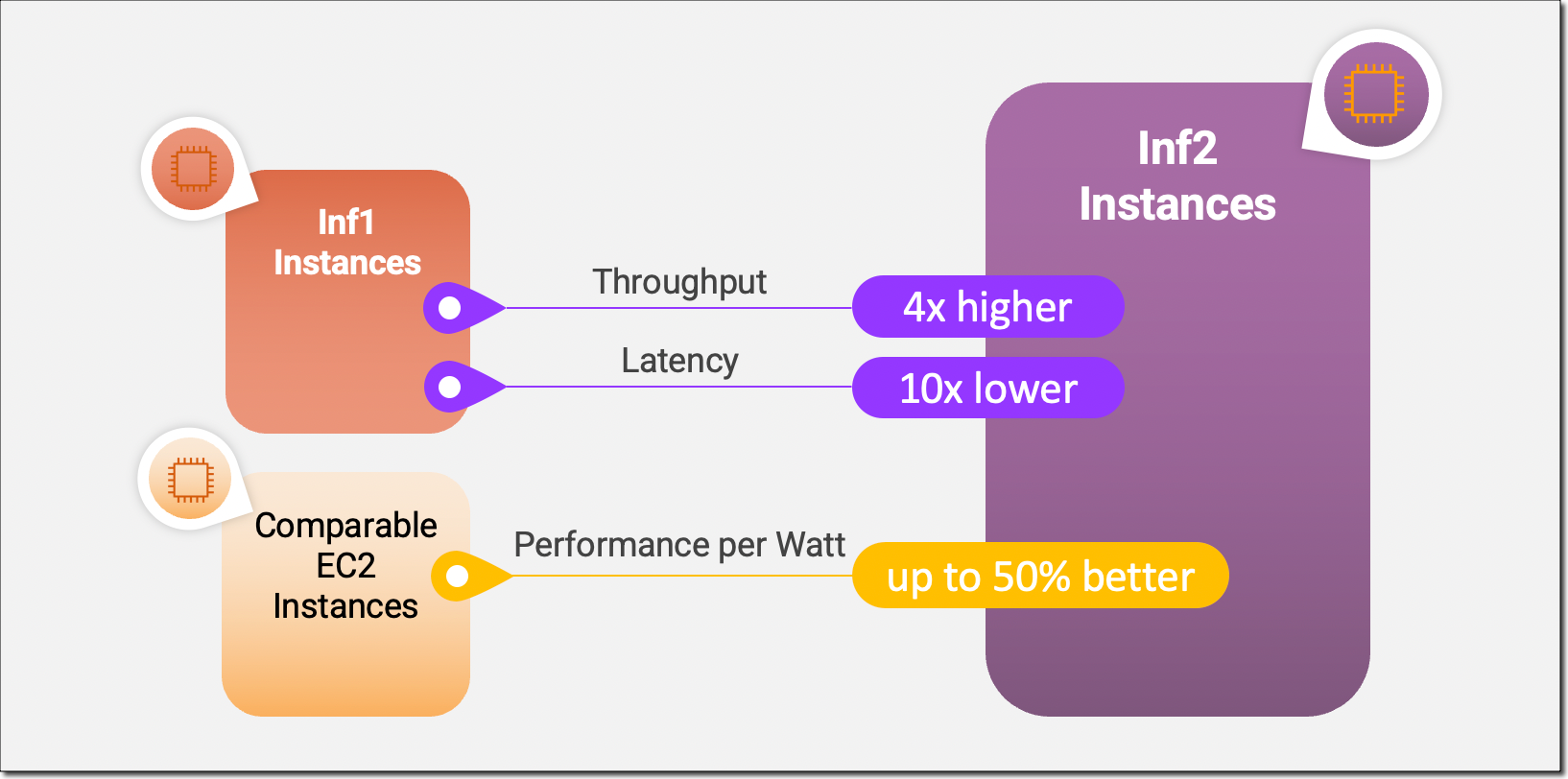
Aspectos destacados de la nueva instancia Inf2
Las instancias Inf2 están disponibles hoy en día en cuatro tamaños y funcionan con hasta 12 chips AWS Inferentia2 con 192 vCPU. Ofrecen una potencia informática combinada de 2,3 petaFLOPS en tipos de datos BF16 o FP16 y cuentan con una interconexión NeuronLink de ultra alta velocidad entre chips. NeuronLink escala modelos grandes en múltiples chips Inferentia2, evita cuellos de botella en la comunicación y permite una inferencia de mayor rendimiento.
Las instancias Inf2 ofrecen hasta 384 GB de memoria aceleradora compartida, con 32 GB de memoria de alto ancho de banda (HBM) en cada chip Inferentia2 y 9,8 TB/s de ancho de banda de memoria total. Este tipo de ancho de banda es particularmente importante para admitir la inferencia de modelos de lenguaje grandes que están limitados por la memoria.
Dado que los chips subyacentes de AWS Inferentia2 están diseñados específicamente para cargas de trabajo DL, las instancias Inf2 ofrecen hasta un 50 % más de rendimiento por vatio que otras instancias Amazon EC2 comparables. Cubriré las innovaciones de silicio de AWS Inferentia2 con más detalle más adelante en esta publicación de blog.
La siguiente tabla enumera los tamaños y especificaciones de las instancias de Inf2 en detalle.
| Nombre de instancia |
vCPU | Chips AWS Inferentia2 | Memoria del acelerador | NeuronLink | Memoria de instancia | Redes de instancias |
| inf2.xgrande | 4 | 1 | 32GB | N / A | 16 GB | Hasta 15 Gb/s |
| inf2.8xgrande | 32 | 1 | 32GB | N / A | 128GB | Hasta 25 Gb/s |
| inf2.24xgrande | 96 | 6 | 192GB | Sí | 384 GB | 50 Gb/s |
| inf2.48xgrande | 192 | 12 | 384 GB | Sí | 768 GB | 100 Gb/s |
Innovación de AWS Inferencea2
Al igual que los chips Trainium de AWS, cada chip Inferentia2 de AWS tiene dos NeuronCore-v2 motores, pilas de HBM y motores de computación colectivos dedicados para paralelizar las operaciones de computación y comunicación al realizar inferencias de múltiples aceleradores.
Cada NeuronCore-v2 tiene motores escalares, vectoriales y tensoriales dedicados que están diseñados específicamente para algoritmos DL. El motor de tensor está optimizado para operaciones matriciales. El motor escalar está optimizado para operaciones elementales como ReLU (unidad lineal rectificada) funciones. El motor vectorial está optimizado para operaciones vectoriales no basadas en elementos, incluidas normalización por lotes o puesta en común.
Aquí hay un breve resumen de las innovaciones adicionales de hardware de servidores y chips de AWS Inferentia2:
- Tipos de datos – AWS Inferentia2 admite una amplia gama de tipos de datos, incluidos FP32, TF32, BF16, FP16 y UINT8, por lo que puede elegir el tipo de datos más adecuado para sus cargas de trabajo. También es compatible con el nuevo tipo de datos configurable FP8 (cFP8), que es especialmente relevante para modelos grandes porque reduce la huella de memoria y los requisitos de E/S del modelo. La siguiente imagen compara los tipos de datos admitidos.

- Ejecución dinámica, formas de entrada dinámicas – AWS Inferentia2 tiene procesadores de señales digitales (DSP) integrados de uso general que permiten la ejecución dinámica, por lo que no es necesario desplegar o ejecutar operadores de flujo de control en el host. AWS Inferentia2 también admite formas de entrada dinámicas que son clave para modelos con tamaños de tensor de entrada desconocidos, como modelos que procesan texto.
- Operadores personalizados – Admite AWS Inferencea2 operadores personalizados escrito en C++. Los operadores personalizados de C++ de Neuron le permiten escribir operadores personalizados de C++ que se ejecutan de forma nativa en NeuronCores. Puede utilizar las interfaces de programación de operadores personalizados estándar de PyTorch para migrar operadores personalizados de CPU a Neuron e implementar nuevos operadores experimentales, todo sin ningún conocimiento profundo del hardware de NeuronCore.
- NeuronLink v2 – Las instancias Inf2 son la primera instancia optimizada para inferencia en Amazon EC2 que admite la inferencia distribuida con conectividad directa de ultra alta velocidad (NeuronLink v2) entre chips. NeuronLink v2 utiliza operadores de comunicaciones colectivas (CC) como all-reduce para ejecutar canalizaciones de inferencia de alto rendimiento en todos los chips.
Los siguientes puntos de referencia de inferencia distribuida Inf2 muestran mejoras de rendimiento y costo para OPT-30B y OPT-66B modelos sobre instancias de Amazon EC2 optimizadas por inferencia comparables.

Ahora, permítame mostrarle cómo comenzar con las instancias Amazon EC2 Inf2.
Comience con las instancias Inf2
El SDK de AWS Neuron® integra AWS Inferentia2 en marcos populares de aprendizaje automático (ML) como PyTorch. Neuron SDK incluye un compilador, tiempo de ejecución y herramientas de creación de perfiles, y se actualiza constantemente con nuevas funciones y optimizaciones de rendimiento.
En este ejemplo, voy a compilar y desplegar un pre-entrenado modelo BERT de cara de abrazo en una instancia EC2 Inf2 utilizando los paquetes PyTorch Neuron disponibles. PyTorch Neuron se basa en el PyTorch XLA paquete de software y permite la conversión de operaciones de PyTorch a instrucciones de AWS Inferentia2.
SSH en su instancia de Inf2 y active un entorno virtual de Python que incluye los paquetes de PyTorch Neuron. Si utiliza una AMI proporcionada por Neuron, puede activar el entorno preinstalado ejecutando el siguiente comando:
source aws_neuron_venv_pytorch_p37/bin/activateAhora, con solo unos pocos cambios en su código, puede compilar su modelo PyTorch en un TorchScript optimizado para AWS Neuron. Comencemos con la importación torchel paquete PyTorch Neuron torch_neuronxy la cara que abraza transformers biblioteca.
import torch
import torch_neuronx from transformers import AutoTokenizer, AutoModelForSequenceClassification
import transformers
...A continuación, construyamos el tokenizador y el modelo.
name = "bert-base-cased-finetuned-mrpc"
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForSequenceClassification.from_pretrained(name, torchscript=True)Podemos probar el modelo con entradas de ejemplo. El modelo espera dos oraciones como entrada, y su salida es si esas oraciones son o no una paráfrasis entre sí.
def encode(tokenizer, *inputs, max_length=128, batch_size=1):
tokens = tokenizer.encode_plus(
*inputs,
max_length=max_length,
padding='max_length',
truncation=True,
return_tensors="pt"
)
return (
torch.repeat_interleave(tokens['input_ids'], batch_size, 0),
torch.repeat_interleave(tokens['attention_mask'], batch_size, 0),
torch.repeat_interleave(tokens['token_type_ids'], batch_size, 0),
)
# Example inputs
sequence_0 = "The company Hugging Face is based in New York City"
sequence_1 = "Apples are especially bad for your health"
sequence_2 = "Hugging Face's headquarters are situated in Manhattan"
paraphrase = encode(tokenizer, sequence_0, sequence_2)
not_paraphrase = encode(tokenizer, sequence_0, sequence_1)
# Run the original PyTorch model on examples
paraphrase_reference_logits = model(*paraphrase)[0]
not_paraphrase_reference_logits = model(*not_paraphrase)[0]
print('Paraphrase Reference Logits: ', paraphrase_reference_logits.detach().numpy())
print('Not-Paraphrase Reference Logits:', not_paraphrase_reference_logits.detach().numpy())La salida debería ser similar a esto:
Paraphrase Reference Logits: [[-0.34945598 1.9003887 ]]
Not-Paraphrase Reference Logits: [[ 0.5386365 -2.2197142]]Ahora el torch_neuronx.trace() El método envía operaciones a Neuron Compiler (neuron-cc) para su compilación e incrusta los artefactos compilados en un gráfico de TorchScript. El método espera el modelo y una tupla de entradas de ejemplo como argumentos.
neuron_model = torch_neuronx.trace(model, paraphrase)Probemos el modelo compilado por Neuron con nuestras entradas de ejemplo:
paraphrase_neuron_logits = neuron_model(*paraphrase)[0]
not_paraphrase_neuron_logits = neuron_model(*not_paraphrase)[0]
print('Paraphrase Neuron Logits: ', paraphrase_neuron_logits.detach().numpy())
print('Not-Paraphrase Neuron Logits: ', not_paraphrase_neuron_logits.detach().numpy())La salida debería ser similar a esto:
Paraphrase Neuron Logits: [[-0.34915772 1.8981738 ]]
Not-Paraphrase Neuron Logits: [[ 0.5374032 -2.2180378]]Eso es todo. Con solo unas pocas líneas de cambios en el código, compilamos y ejecutamos un modelo PyTorch en una instancia Amazon EC2 Inf2. Para obtener más información sobre qué arquitecturas de modelo DL son adecuadas para AWS Inferentia2 y la matriz de soporte de modelo actual, visite la documentación de AWS Neuron.
Disponible ahora
Puede lanzar instancias Inf2 hoy en las regiones de AWS EE. UU. Este (Ohio) y EE. UU. Este (Norte de Virginia) como instancias bajo demanda, reservadas y puntuales o como parte de un plan de ahorro. Como es habitual con Amazon EC2, solo paga por lo que usa. Para obtener más información, consulte Precios de Amazon EC2.
Las instancias de Inf2 se pueden implementar mediante AMI de aprendizaje profundo de AWS y las imágenes de contenedores están disponibles a través de servicios administrados como Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS) y AWS ParallelCluster.
Para obtener más información, visite nuestra página de instancias Amazon EC2 Inf2 y envíe sus comentarios a AWS re: publicar para EC2 o a través de sus contactos habituales de AWS Support.
— Antje