|
|
Desde 2013, Amazon Redshift ha brindado todo el poder de un almacén de datos en la nube, a una fracción del costo local. Cada generación de arquitectura (desde computación densa hasta instancias de Amazon RA3, desde aprovisionamiento hasta Amazon Redshift Serverless) ha hecho que cada consulta sea más barata, más rápida y más eficiente que la anterior.
Durante más de una década, a medida que los volúmenes de datos han crecido y los requisitos de análisis han evolucionado, las organizaciones aprovechan cada vez más tanto las tablas de almacenamiento de datos para datos estructurados a los que se accede con frecuencia como los lagos de datos para un almacenamiento rentable de diversos conjuntos de datos. Agregue agentes de IA a la combinación y consultarán su almacén de datos a una escala que eclipsa el uso humano típico, lo que genera costos operativos vertiginosos.
Amazon Redshift ha duplicado sus fortalezas principales para satisfacer las demandas de cualquier carga de trabajo, ya sea impulsada por humanos o agentes de IA. Por ejemplo, en marzo de 2026, Amazon Redshift mejoró el rendimiento de los paneles de inteligencia empresarial (BI) y las cargas de trabajo ETL al acelerar las nuevas consultas hasta 7 veces. Esto mejora significativamente los tiempos de respuesta de las consultas SQL de baja latencia, como las que se utilizan en aplicaciones de análisis casi en tiempo real, paneles de BI, canales de ETL y agentes de IA autónomos que buscan objetivos.
Hoy anunciamos las instancias de Amazon Redshift RG, una nueva familia de instancias impulsada por AWS Graviton. Las instancias RG ofrecen un mejor rendimiento y ejecutan cargas de trabajo de almacenamiento de datos hasta 2,2 veces más rápido que las instancias RA3 a un precio un 30 % más bajo por vCPU. Su motor de consulta de lago de datos integrado le permite ejecutar análisis SQL en su almacén de datos y lago de datos desde un único motor con un rendimiento hasta 2,4 veces más rápido que RA3 para Iceberg apache y hasta 1,5 veces más rápido que RA3 para Parquet apache. Esta combinación de velocidad, rentabilidad y un motor de consulta de lago de datos integrado hace que las instancias de Redshift RG sean adecuadas para manejar los altos volúmenes de consultas y los requisitos de baja latencia de las cargas de trabajo de inteligencia artificial y análisis actuales.
Puede comparar nuevas instancias RG y las instancias RA3 actuales:
| Instancia RA3 actual | Instancia RG recomendada | CPU virtual | Memoria (GB) | Caso de uso principal |
ra3.xlplus |
rg.xlarge |
4 | 32 | Análisis departamental de clústeres pequeños |
ra3.4xlarge |
rg.4xlarge |
12 → 16 (1.33:1) | 96 GB → 128 GB (1,33:1) | Cargas de trabajo de producción estándar, volúmenes de datos medios |
Este enfoque reduce los costos totales de análisis para los clientes que ejecutan cargas de trabajo combinadas de almacén de datos y lago de datos, al tiempo que simplifica las operaciones a través de un único sistema para consultar tablas de almacén y lagos de datos de Amazon Simple Storage Service (Amazon S3). Recomendamos utilizar el Calculadora de precios de AWS con sus patrones de carga de trabajo específicos para estimar los ahorros.
Introducción a las instancias de Amazon Redshift RG
Puede lanzar nuevos clústeres o migrar clústeres existentes a través de la consola de administración de AWS, la interfaz de línea de comandos de AWS (AWS CLI) o la API de AWS. El motor de consulta del lago de datos integrado está habilitado de forma predeterminada.
En la consola de Amazon Redshift, puede elegir nuevas instancias de RG cuando crea un clúster.
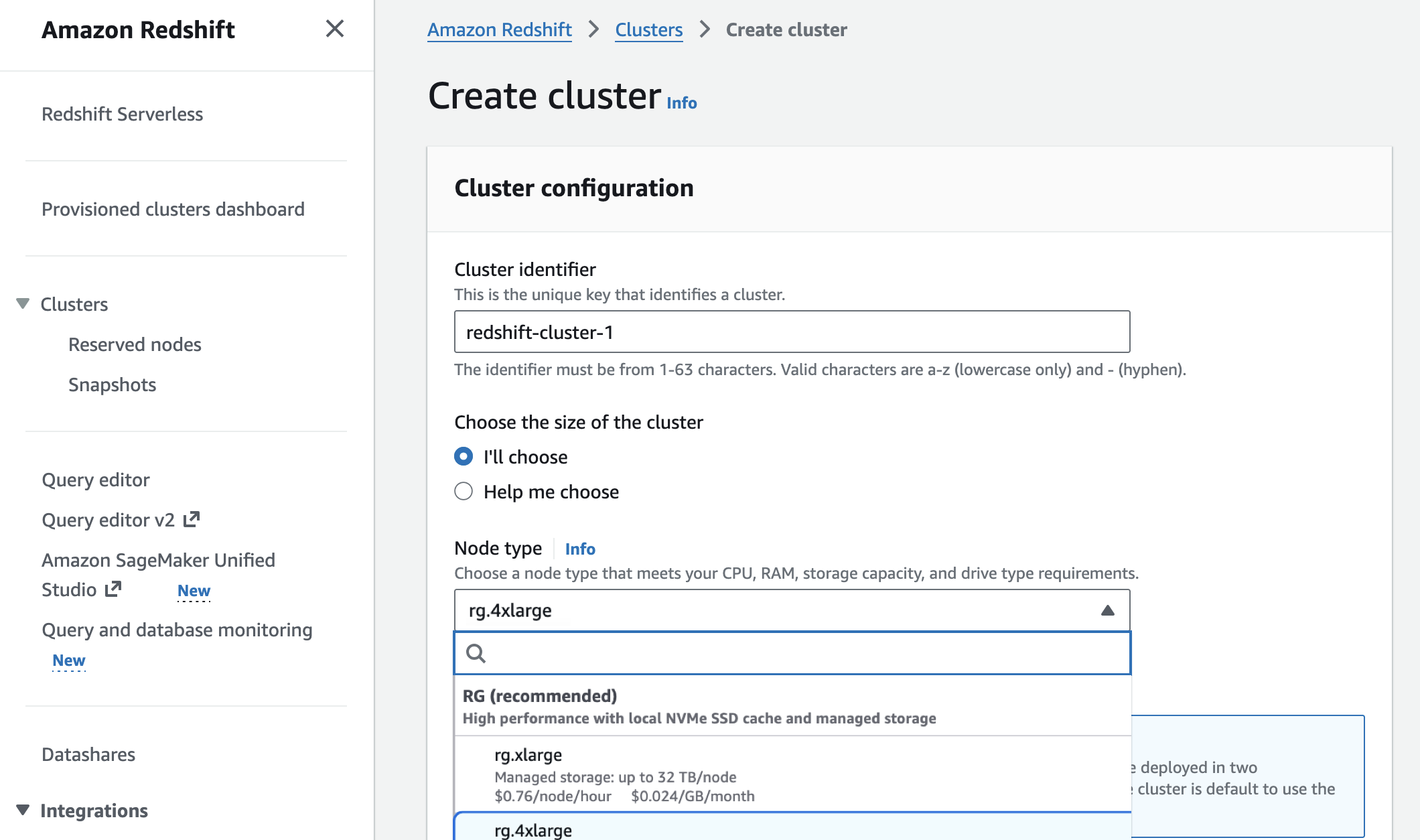
Puede migrar instancias de generación anterior a instancias RG con rutas óptimas según la configuración de su clúster para estimar costos, validar la compatibilidad y automatizar la ejecución.
- Cambio de tamaño elástico—Migración in situ con un tiempo de inactividad de 10 a 15 minutos para configuraciones compatibles
- Instantánea y restauración: crea un clúster RG a partir de una instantánea RA3. Esto es mejor para los clientes que desean realizar cambios de configuración durante la migración.
Sus tablas externas, esquemas y sintaxis de consultas (incluidas las consultas de Spectrum existentes) permanecen sin cambios. No es necesario volver a crear tablas externas ni modificar el código de la aplicación. Para obtener más información, visite la Guía de gestión de Redshift.
Amazon Redshift ahora ejecuta consultas del lago de datos en los nodos del clúster: el mismo proceso que procesa las cargas de trabajo del almacén de datos. Como resultado, ya no se requiere Amazon Redshift Spectrum. Las consultas del lago de datos permanecen dentro de los límites de su VPC, utilizan funciones de IAM existentes y no generan cargos de escaneo por terabyte. Esto elimina las tarifas de escaneo de Spectrum de $5/TB que anteriormente se sumaban a los costos totales de Redshift.
Ahora disponible
Las instancias de Amazon Redshift RG ahora están disponibles en las siguientes regiones de AWS: EE. UU. Este (Norte de Virginia, Ohio), EE. UU. Oeste (Norte de California, Oregón), Asia Pacífico (Hong Kong, Hyderabad, Yakarta, Malasia, Melbourne, Mumbai, Osaka, Seúl, Singapur, Sydney, Taiwán, Tokio), Canadá (Central), Europa (Frankfurt, Irlanda, Milán, Londres, París, España, Estocolmo) y América del Sur (São Paulo). Para conocer la disponibilidad regional y una hoja de ruta futura, visite el Capacidades de AWS por región. Para Redshift Provisioned, puede seleccionar Instancias bajo demanda con facturación por horas y sin compromisos o elegir Instancias reservadas para ahorrar costos. Para obtener más información, visite la página de precios de Amazon Redshift.
Pruebe las instancias de RG en la consola de Redshift y envíe comentarios a AWS re: Publicación para Amazon Redshift o a través de sus contactos habituales de AWS Support.
— chany
Actualizado el 12/05/26: Medio Oriente (EAU) eliminado de las regiones disponibles.