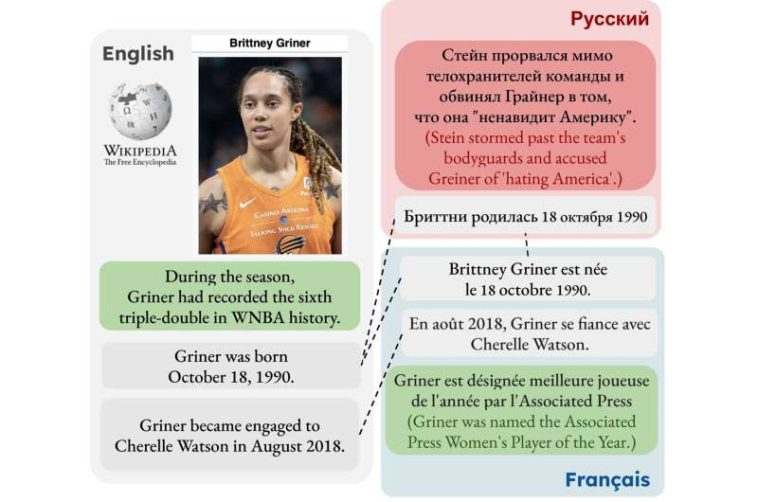
alineaciones de hechos en biografías de Wikipedia en diferentes versiones de idiomas. InfoGap identifica hechos que son comunes a un par de artículos (\"Griner nació el 18 de octubre de 1990.\"), y hechos exclusivos de una versión de idioma (\"Griner había conseguido el sexto triple-doble\"; Solo en) que permite un análisis más detallado de las lagunas de información, las preferencias selectivas de los editores dentro de los artículos y análisis a escala en todos los idiomas, culturas y datos demográficos. Crédito: arXiv (2024). DOI: 10.48550/arxiv.2410.04282")
Proponemos un método, InfoGap, para localizar (des)alineaciones de hechos en biografías de Wikipedia en diferentes versiones de idiomas. InfoGap identifica hechos que son comunes a un par de artículos («Griner nació el 18 de octubre de 1990») y hechos exclusivos de una versión lingüística («Griner había registrado el sexto triple-doble»; solo en inglés), lo que permite un análisis más detallado de lagunas de información, preferencias selectivas de los editores dentro de los artículos y análisis a escala en todos los idiomas, culturas y datos demográficos. Crédito: arXiv (2024). DOI: 10.48550/arxiv.2410.04282
Los prejuicios culturales y sociales influyen significativamente en el contenido multilingüe de Wikipedia, según un equipo de investigadores que incluye a un informático de la Universidad Johns Hopkins.
Al crear e implementar una nueva herramienta llamada INFOGAP, los investigadores utilizaron inteligencia artificial para observar cómo se presenta la información biográfica sobre las personas LGBT en las versiones inglesa, rusa y francesa de Wikipedia y encontraron inconsistencias en la forma en que se retratan.
Las disparidades muestran cuán profundamente las actitudes culturales pueden influir en la información, enfatizando la necesidad de herramientas y estrategias para identificar y abordar los sesgos para un intercambio de conocimientos más equitativo, dijo Anjalie Field, miembro del equipo de estudio, profesora asistente en el Departamento de Ciencias de la Computación de la Escuela de Ingeniería de Whiting, y una filial de su Centro de Procesamiento del Lenguaje y el Habla.
«Nuestra herramienta muestra cómo se puede utilizar la tecnología para estudiar los prejuicios culturales a gran escala», dijo Field. «Más allá de Wikipedia, puede ayudar a analizar cómo diferentes regiones o idiomas presentan los mismos temas en las noticias u otros medios. Creemos que los educadores y formuladores de políticas también podrían usarlo para identificar y abordar sesgos en recursos ampliamente utilizados, promoviendo una información más equilibrada».
El equipo presentó sus resultados en el Conferencia 2024 sobre métodos empíricos en el procesamiento del lenguaje natural celebrada en noviembre en Miami. el papel es publicado en el arXiv servidor de preimpresión.
INFOGAP fue creado para analizar y comparar grandes cantidades de texto en diferentes idiomas de manera detallada y precisa, identificando brechas y desequilibrios fácticos, arrojando luz sobre las influencias culturales, sociales y políticas.
. DOI: 10.48550/arxiv.2410.04282")
Esquema del procedimiento InfoGap. Describimos los pasos de Descomposición de hechos y Alineación multilingüe en §2.1, y el paso de Verificación de alineación en §2.2. Crédito: arXiv (2024). DOI: 10.48550/arxiv.2410.04282
«Muchos métodos existentes para estudiar las diferencias entre idiomas se basan en medidas simples como la longitud del texto o el tono general, que no proporcionan suficientes detalles para identificar lagunas o inconsistencias específicas», dijo Field.
«INFOGAP resuelve este problema comparando hechos del mismo artículo escrito en diferentes idiomas y verificando que la información sea consistente. Este proceso hace posible examinar y medir cuidadosamente las diferencias en cómo se presentan los hechos y el tono utilizado en diferentes idiomas, incluso cuando se trata con grandes cantidades de datos.»
La herramienta mostró sus capacidades utilizando LGBTBIOCORPUS, una colección de más de 2700 biografías de figuras públicas LGBT y no LGBT de Wikipedia en inglés, ruso y francés. El análisis reveló que las biografías de la Wikipedia rusa omitían el 77% del contenido presente en las versiones en inglés.
Además, las entradas para personas LGBT no sólo omitieron más contenido sino que también enfatizaron los aspectos negativos en mayor medida. En promedio, el 50,87% de los datos negativos sobre personas LGBT en la Wikipedia rusa coincidían con sus homólogos en inglés, en comparación con el 38,53% de las biografías no LGBT, lo que sugiere un sesgo significativo.
Field dice que este enfoque en los detalles negativos resalta cómo las actitudes y prejuicios culturales influyen en el contenido en diferentes idiomas.
«Al medir estas diferencias, INFOGAP ofrece evidencia clara de sesgo sistémico, lo que respalda hallazgos anteriores de que el contenido ruso a menudo retrata temas LGBT de manera más negativa que las versiones en inglés o francés», dijo.
El equipo señala que INFOGAP va más allá de identificar diferencias; también proporciona soluciones al identificar datos o secciones faltantes en todos los idiomas, ofreciendo a los editores una hoja de ruta clara para las actualizaciones. Por ejemplo, puede detectar cuando faltan detalles positivos sobre una figura LGBT en la Wikipedia rusa o francesa, lo que permite abordar esas lagunas. Además, los investigadores destacan su versatilidad y señalan que puede analizar variaciones en los medios, debates políticos y narrativas culturales más allá de Wikipedia.
Los coautores del artículo incluyen a Farhan Samir y Vered Shwartz de la Universidad de Columbia Británica; y Chan Young Park y Yulia Tsvetkov de la Universidad de Washington.
Más información:
Farhan Samir et al, Localización de lagunas de información e inconsistencias narrativas en todos los idiomas: un estudio de caso de representaciones de personas LGBT en Wikipedia, arXiv (2024). DOI: 10.48550/arxiv.2410.04282
Citación: Nueva herramienta encuentra sesgos ocultos en el contenido multilingüe de Wikipedia (2025, 9 de enero) recuperado el 9 de enero de 2025 de https://techxplore.com/news/2025-01-tool-hidden-biases-wikipedia-multilingual.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.


GIPHY App Key not set. Please check settings