La mezcla de expertos (MoE) es una arquitectura de modelo de aprendizaje profundo en la que el costo computacional es sublineal al número de parámetros, lo que facilita el escalado. Hoy en día, MoE es el único enfoque demostrado para escalar modelos de aprendizaje profundo a más de un billón de parámetros, allanando el camino para modelos capaces de aprender aún más información y potenciar la visión por computadora, el reconocimiento de voz, el procesamiento del lenguaje natural y los sistemas de traducción automática, entre otros. que puede ayudar a personas y organizaciones de nuevas formas.
Hoy, estamos orgullosos de anunciar Tutel, una biblioteca MoE de alto rendimiento facilitar el desarrollo de modelos DNN a gran escala; Tutel está altamente optimizado para la nueva serie Azure NDm A100 v4, ahora disponible de forma general. Con el soporte algorítmico de MoE diverso y flexible de Tutel, los desarrolladores de todos los dominios de IA pueden ejecutar MoE de manera más fácil y eficiente. Para una sola capa de MoE, Tutel logra una aceleración de 8.49x en un nodo NDm A100 v4 con 8 GPU y una aceleración de 2.75x en nodos de 64 NDm A100 v4 con 512 GPU A100 (todos los experimentos en este blog se prueban en nodos Azure NDm A100 v4 con 8 x 80 GB NVIDIA A100 y una red InfiniBand de 8 x 200 gigabits por segundo), respectivamente, en comparación con implementaciones de MoE de última generación como la de Kit de herramientas de secuencia a secuencia de investigación de IA de Facebook de Meta (fairseq) en PyTorch. Para un rendimiento de extremo a extremo, Tutel, beneficiándose de una optimización para la comunicación de todos a todos, logra una aceleración de más del 40 por ciento con 64 nodos NDm A100 v4 para Meta’s (Facebook ahora es Meta) Modelo de lenguaje MoE de 1,1 billones de parámetros . Tutel proporciona una gran compatibilidad con funciones completas para garantizar un gran rendimiento cuando se trabaja en el clúster Azure NDm A100 v4. Tutel es de código abierto y se ha integrado en fairseq.
Optimizaciones de Tutel MoE
Como complemento de otras soluciones de MoE de alto nivel como fairseq y FastMoE, Tutel se centra principalmente en las optimizaciones de la computación específica de MoE y la comunicación de todos a todos, así como en otros soportes algorítmicos de MoE diversos y flexibles. Tutel tiene una interfaz concisa, lo que facilita la integración en otras soluciones de MoE. Alternativamente, los desarrolladores pueden usar la interfaz de Tutel para incorporar capas independientes de MoE en sus propios modelos de DNN desde cero y beneficiarse directamente de las funciones de MoE de última generación altamente optimizadas.
Optimización específica de MoE para cálculo
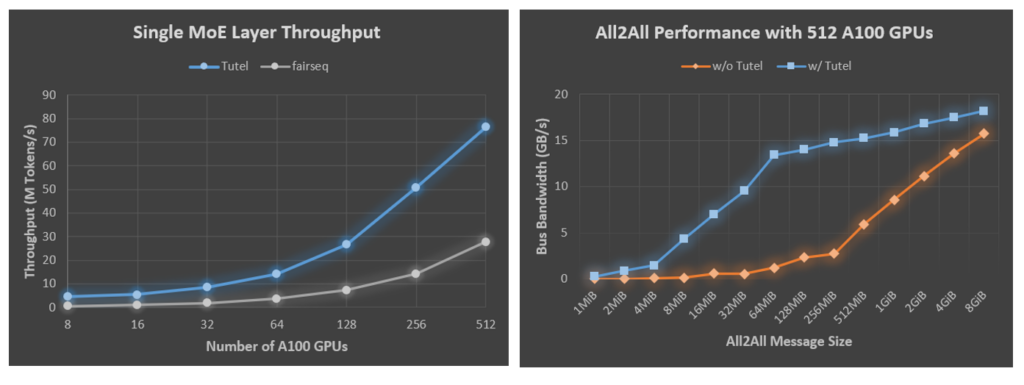
Debido a la falta de implementaciones eficientes, los modelos DNN basados en MoE se basan en una combinación ingenua de múltiples operadores DNN estándar proporcionados por marcos de aprendizaje profundo como PyTorch y TensorFlow para componer el cálculo MoE. Esta práctica genera importantes gastos generales de rendimiento gracias a la computación redundante. Tutel diseña e implementa múltiples núcleos de GPU altamente optimizados para proporcionar operadores para el cálculo específico de MoE. Por ejemplo, Tutel reduce la complejidad del tiempo de despachar «salida de puerta» de O (N ^ 3) a O (N ^ 2), lo que mejora significativamente la eficiencia de despacho de datos. Tutel también implementa un operador rápido cumsum-menos-uno, logrando una aceleración 24x en comparación con la implementación de fairseq. Tutel también aprovecha NVRTC, una biblioteca de compilación en tiempo de ejecución para CUDA C ++, para optimizar aún más el kernel personalizado de MoE justo a tiempo. La Figura 1 muestra los resultados de la comparación de Tutel con fairseq en la plataforma Azure NDm A100 v4, donde, como se mencionó anteriormente, una sola capa de MoE con Tutel logra una aceleración de 8.49x en 8 GPU A100 y una aceleración de 2.75x en 512 GPU A100.
Optimización de la comunicación integral subyacente en clústeres de Azure NDm A100 v4
Tutel también optimiza la comunicación colectiva integral para el entrenamiento MoE a gran escala en clústeres Azure NDm A100 v4, incluido el enlace CPU-GPU y el ajuste de enrutamiento adaptativo (AR). Un enlace CPU-GPU adecuado en un sistema de acceso a memoria no uniforme (NUMA), especialmente en los nodos NDm A100 v4, es muy crítico para el rendimiento integral. Desafortunadamente, los marcos de aprendizaje automático existentes no han proporcionado una biblioteca de comunicación integral eficiente, lo que resulta en una regresión del rendimiento para la capacitación distribuida a gran escala. Tutel optimiza la encuadernación automáticamente y proporciona una interfaz elegante para el ajuste fino del usuario. Además, Tutel aprovecha la tecnología multitrayecto, concretamente AR, en clústeres NDm A100 v4. Para la comunicación de todos a todos en MoE, el tamaño total del tráfico de datos de la comunicación para cada GPU no cambia, pero el tamaño de los datos entre cada par de GPU se vuelve más pequeño con el número creciente de GPU. El tamaño de datos más pequeño incurre en una mayor sobrecarga en la comunicación de todos a todos, lo que lleva a un rendimiento de entrenamiento de MoE más deficiente. Al aprovechar la tecnología AR disponible en los clústeres NDm A100 v4, Tutel mejora la eficiencia de la comunicación para grupos de mensajes pequeños y proporciona una comunicación integral de alto rendimiento en los sistemas NDm A100 v4. Al beneficiarse de la vinculación CPU-GPU y el ajuste de AR, Tutel logra una aceleración total de 2.56x a 5.93x con 512 GPU A100 para tamaños de mensaje de cientos de MiB grandes, que generalmente se usan en el entrenamiento de MoE, como se ilustra en la Figura 2.
Compatibilidad con algoritmos de MoE diversos y flexibles
Tutel proporciona soporte diverso y flexible para algoritmos MoE de última generación, incluido el soporte para:
- la configuración arbitraria de K para el algoritmo de activación de Top-K (la mayoría de las implementaciones solo admiten Top-1 y Top-2).
- diferentes estrategias de exploración, incluido el enrutamiento priorizado por lotes, la pérdida de entrada y la fluctuación de entrada
- diferentes niveles de precisión, incluida la precisión media (FP16), precisión total (FP32) y precisión mixta (admitiremos BF16 en nuestra próxima versión)
- diferentes tipos de dispositivos, incluidos los dispositivos NVIDIA CUDA y AMD ROCm
Tutel integrará activamente varios algoritmos emergentes de MoE de la comunidad de código abierto.
Integrando Tutel con el modelo de lenguaje MoE de Meta
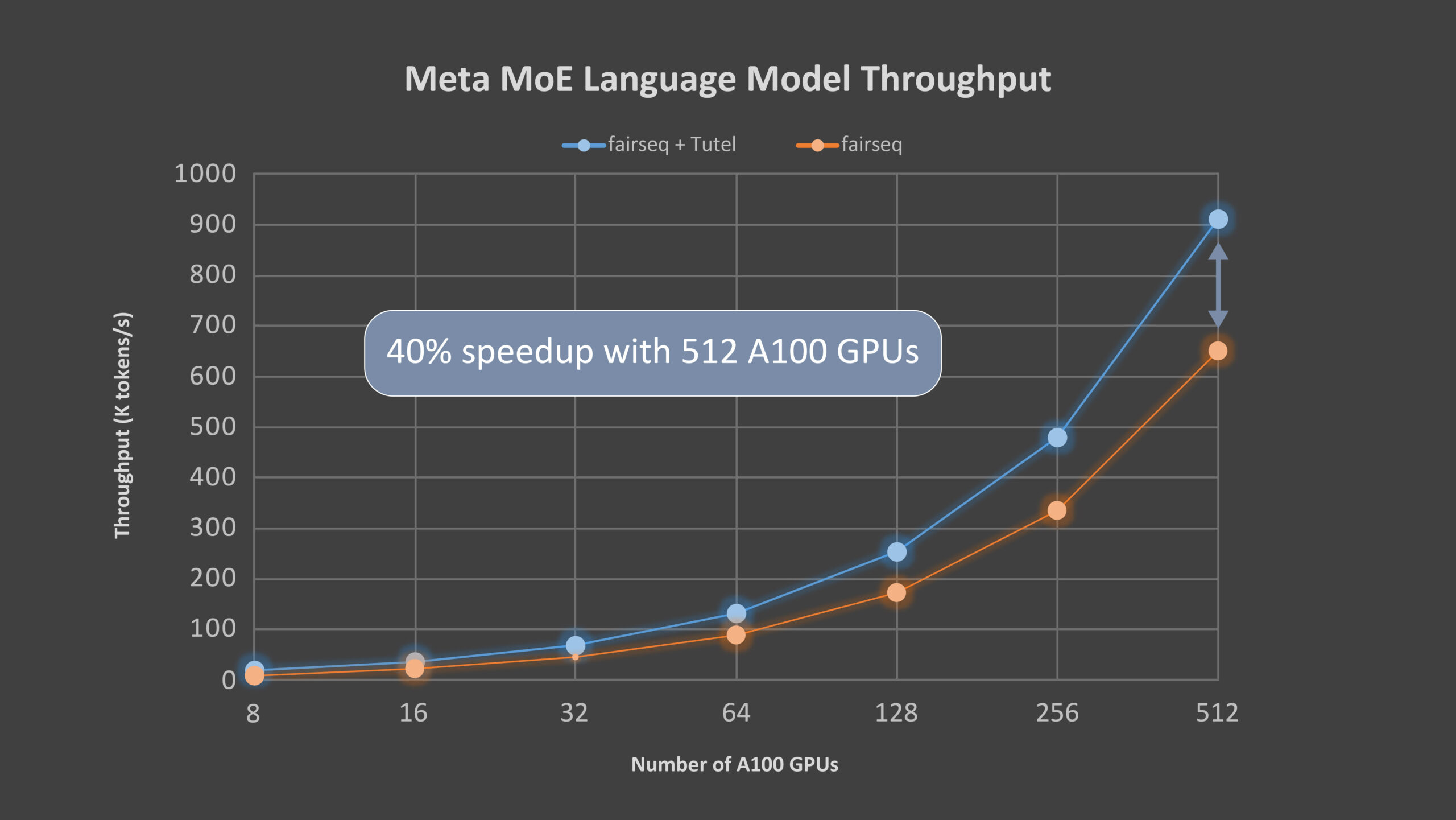
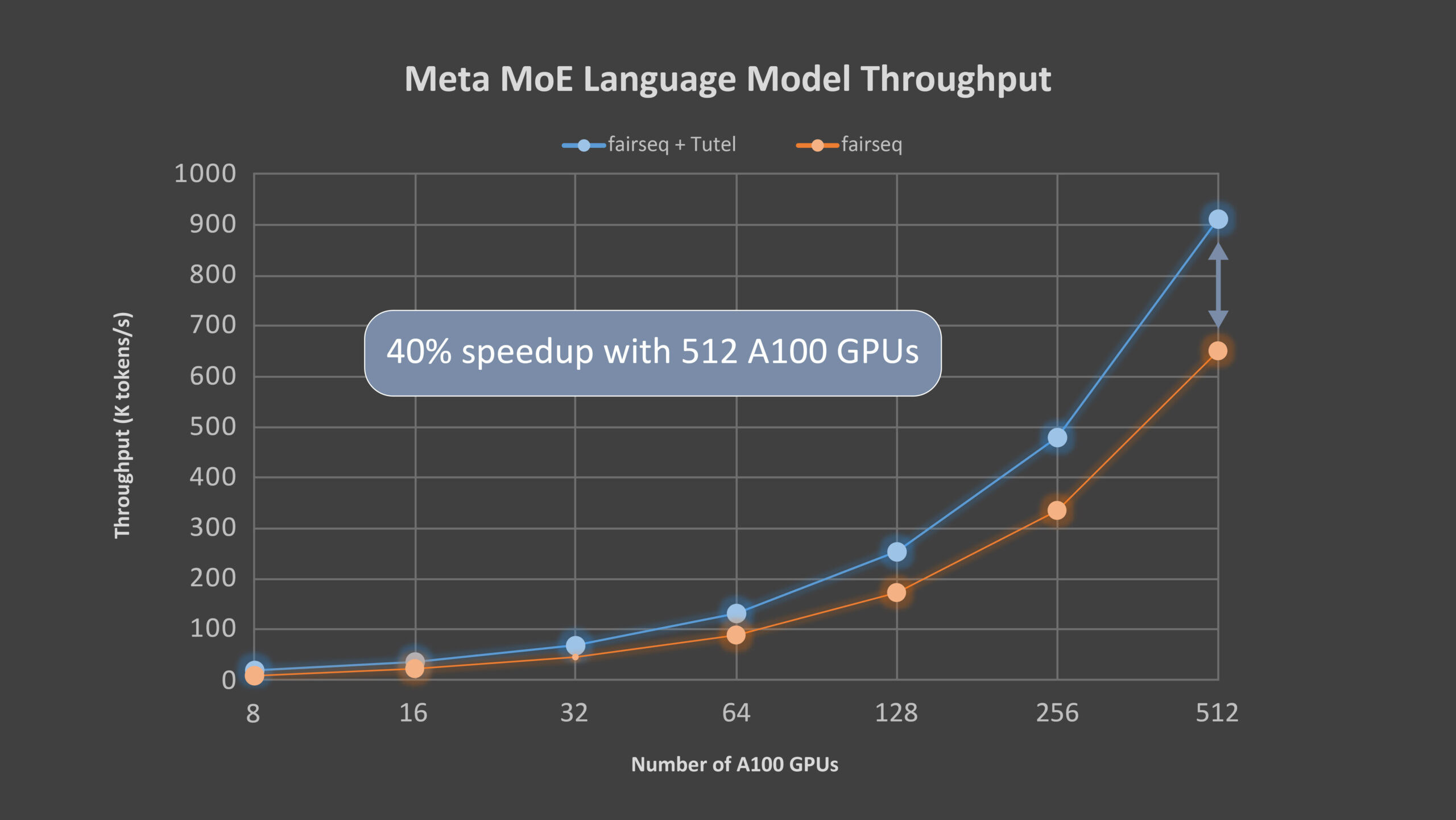
Meta hizo su modelo de lenguaje MoE de código abierto y utiliza fairseq para su implementación MoE. Trabajamos con Meta para integrar Tutel en el kit de herramientas de fairseq. Meta ha estado usando Tutel para entrenar su modelo de lenguaje grande, que tiene una arquitectura neuronal basada en la atención similar a GPT-3, en Azure NDm A100 v4. Usamos el modelo de lenguaje de Meta para evaluar el desempeño de un extremo a otro de Tutel. El modelo tiene 32 capas de atención, cada una con cabezas de 32 x 128 dimensiones. Cada dos capas contiene una capa de MoE y cada GPU tiene un experto. La Tabla 1 resume la configuración detallada de los parámetros del modelo, y la Figura 3 muestra la aceleración del 40 por ciento que logra Tutel. Con el creciente número de GPU, la ganancia de Tutel es del 131 por ciento con 8 GPU A100 al 40 por ciento con 512 GPU A100 porque la comunicación de todos a todos se convierte en el cuello de botella. Haremos una mayor optimización en la próxima versión.
| Configuración | Configuración | Configuración | Configuración |
| rama de código | moe-benchmark | ID de confirmación de Git | 1ef1612 |
| capas decorativas | 32 | Arco | transformer_lm_gpt |
| decodificador-cabezas-de-atención | 32 | Criterio | moe_cross_entropy |
| decodificador-incrustado-tenue | 4096 | moe-freq | 2 |
| decorder-ffn-embed-dim | 16384 | recuento-experto-moe | 512 |
| tokens por muestra | 1024 | moe-gating-use-fp32 | Cierto |
| Tamaño del lote | 24 | Optimizador | Adán |
| tamaño del vocabulario | 51200 | fp16-adam-stats | Cierto |
La promesa del MoE
MoE es una tecnología prometedora. Permite un entrenamiento holístico basado en técnicas de muchas áreas, como el enrutamiento sistemático y el equilibrio de la red con nodos masivos, e incluso puede beneficiarse de la aceleración basada en GPU. Demostramos una implementación eficiente de MoE, Tutel, que resultó en una ganancia significativa sobre el marco de fairseq. Tutel también se ha integrado en el marco de DeepSpeed, y creemos que Tutel y las integraciones relacionadas beneficiarán a los servicios de Azure, especialmente para aquellos que desean escalar sus grandes modelos de manera eficiente. Como el Ministerio de Educación de hoy aún se encuentra en sus primeras etapas y se necesitan más esfuerzos para desarrollar todo su potencial, Tutel continuará evolucionando y nos brindará resultados más emocionantes.
Reconocimiento
La investigación detrás de Tutel fue realizada por un equipo de investigadores de todo Microsoft, incluidos Wei Cui, Zilong Wang, Yifan Xiong, Guoshuai Zhao, Fan Yang, Peng Cheng, Yongqiang Xiong, Mao Yang, Lidong Zhou, Rafael Salas, Jithin Jose, Kushal Datta, Prabhat Ram y Joe Chau.