|
|
Me complace anunciar hoy la disponibilidad de Amazon File Cache, un nuevo servicio de caché de alta velocidad en AWS diseñado para procesar datos de archivos almacenados en diferentes ubicaciones, incluso en las instalaciones. File Cache acelera y simplifica sus flujos de trabajo híbridos y de explosión en la nube más exigentes al brindar a sus aplicaciones acceso a archivos mediante un método rápido y familiar. POSIX interfaz, sin importar si los archivos originales viven en las instalaciones en cualquier sistema de archivos al que se pueda acceder a través de NFS v3 o en Amazon Simple Storage Service (Amazon S3).
Imagine que tiene un gran conjunto de datos en la infraestructura de almacenamiento local y que los informes de fin de mes suelen tardar entre dos y tres días en ejecutarse. Quiere mover esa carga de trabajo ocasional a la nube para ejecutarla en máquinas más grandes con más CPU y memoria para reducir el tiempo de procesamiento. Pero aún no está listo para mover el conjunto de datos a la nube.
Imagine otro escenario en el que tenga acceso a un gran conjunto de datos en Amazon Simple Storage Service (Amazon S3), distribuido en varias regiones. Su aplicación que quiere explotar este conjunto de datos está codificada para el acceso al sistema de archivos tradicional (POSIX) y utiliza herramientas de línea de comandos como awk, sed, tubería, y así. Su aplicación requiere acceso a archivos con latencias de submilisegundos. No puede actualizar el código fuente para usar la API de S3.
File Cache ayuda a abordar estos casos de uso y muchos otros, piense en la gestión y transformación de archivos de video, conjuntos de datos AI/ML, etc. File Cache crea una caché basada en el sistema de archivos delante de los sistemas de archivos NFS v3 o depósitos S3 en una o más regiones. Carga de forma transparente el contenido del archivo y los metadatos (como el nombre del archivo, el tamaño y los permisos) desde el origen y lo presenta a sus aplicaciones como un sistema de archivos tradicional. File Cache libera automáticamente los archivos en caché utilizados menos recientemente para garantizar que los archivos más activos estén disponibles en el caché para sus aplicaciones.
Puede vincular hasta ocho sistemas de archivos NFS u ocho depósitos S3 a un caché, y se expondrán como un conjunto unificado de archivos y directorios. Puede acceder a la memoria caché desde una variedad de servicios informáticos de AWS, como máquinas virtuales o contenedores. La conexión entre File Cache y su infraestructura local utiliza su conexión de red existente, basada en AWS Direct Connect o Site-to-Site VPN.
Al usar File Cache, sus aplicaciones se benefician de latencias constantes de menos de un milisegundo, hasta cientos de GB/s de rendimiento y hasta millones de operaciones por segundo. Al igual que con otros servicios de almacenamiento, como Amazon Elastic Block Store (Amazon EBS), el rendimiento depende del tamaño de la memoria caché. El tamaño de la memoria caché se puede ampliar a escala de petabytes, con un tamaño mínimo de 1,2 TiB.
Vamos a ver cómo funciona
Para mostrarle cómo funciona, creo una caché de archivos sobre dos sistemas de archivos existentes de Amazon FSx para OpenZFS. En un escenario del mundo real, es probable que cree cachés sobre los sistemas de archivos locales. Elijo FSx para OpenZFS para la demostración porque no tengo un centro de datos local a la mano (tal vez debería invertir en seb-west-1). Se puede acceder a ambos sistemas de archivos OpenZFS de demostración desde una subred privada en mi cuenta de AWS. Finalmente, accedo al caché desde una instancia EC2 Linux.
Abro mi navegador y navego a la consola de administración de AWS. Busco «Amazon FSx» en la barra de búsqueda de la consola y hago clic en cachés en el menú de navegación izquierdo. Alternativamente, voy directamente a la sección Caché de archivos de la consola. Para empezar, selecciono Crear caché.
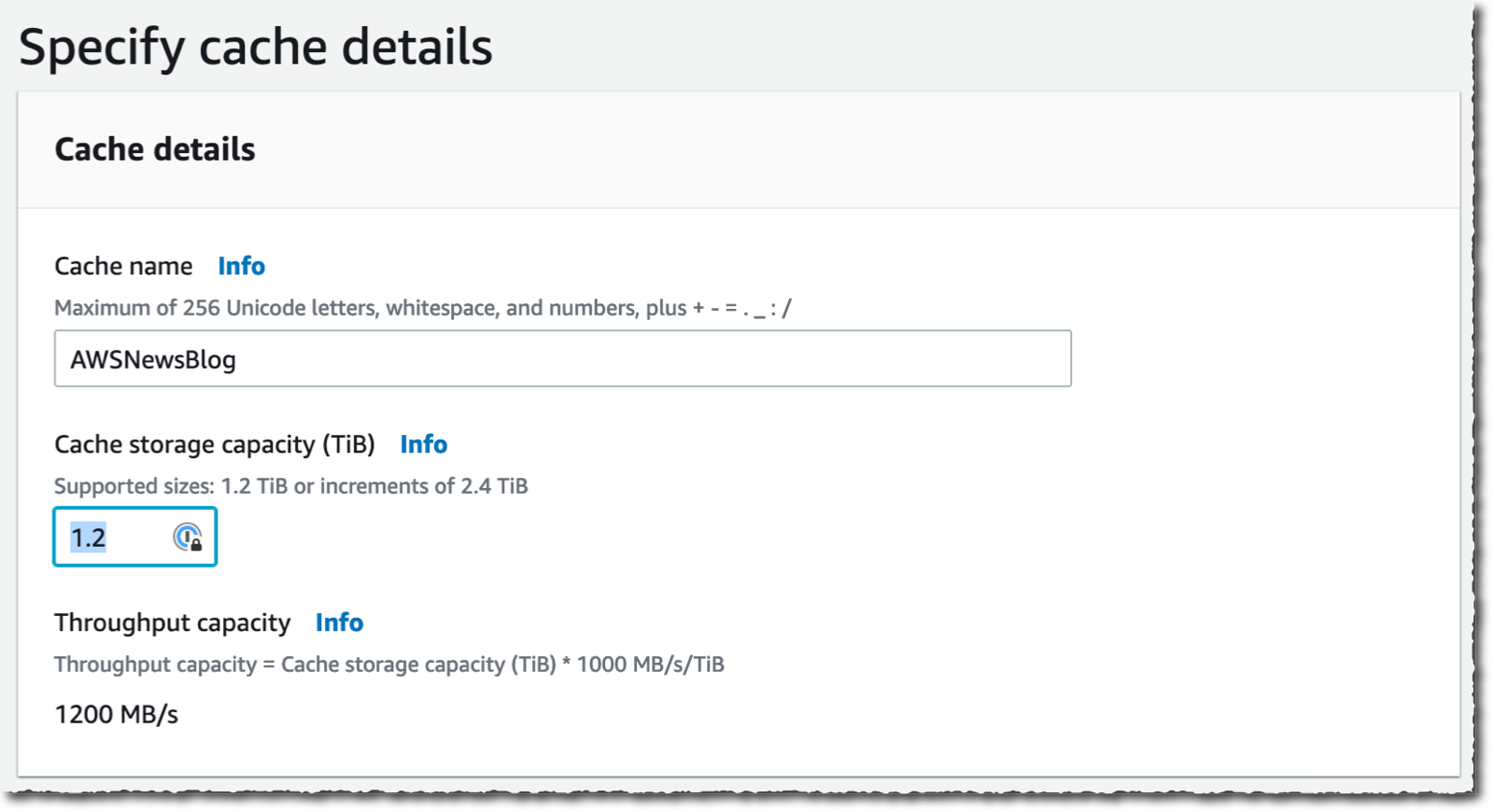
 entro en un Nombre de caché para mi caché (AWSNewsBlog para esta demostración) y un Capacidad de almacenamiento en caché. La capacidad de almacenamiento se expresa en tebibytes. El valor mínimo es 1,2 TiB o incrementos de 2,4 TiB. Note que el Capacidad de rendimiento aumenta a medida que elige tamaños de caché grandes.
entro en un Nombre de caché para mi caché (AWSNewsBlog para esta demostración) y un Capacidad de almacenamiento en caché. La capacidad de almacenamiento se expresa en tebibytes. El valor mínimo es 1,2 TiB o incrementos de 2,4 TiB. Note que el Capacidad de rendimiento aumenta a medida que elige tamaños de caché grandes.
 Verifico y acepto los valores predeterminados proporcionados para Redes y Cifrado. Para las redes, podría seleccionar una VPC, una subred y un grupo de seguridad para asociar con mi interfaz de red de caché. Se recomienda implementar la memoria caché en la misma subred que su servicio informático para minimizar la latencia al acceder a los archivos. Para el cifrado, podría usar una clave administrada por AWS KMS (la predeterminada) o seleccionar la mía.
Verifico y acepto los valores predeterminados proporcionados para Redes y Cifrado. Para las redes, podría seleccionar una VPC, una subred y un grupo de seguridad para asociar con mi interfaz de red de caché. Se recomienda implementar la memoria caché en la misma subred que su servicio informático para minimizar la latencia al acceder a los archivos. Para el cifrado, podría usar una clave administrada por AWS KMS (la predeterminada) o seleccionar la mía.
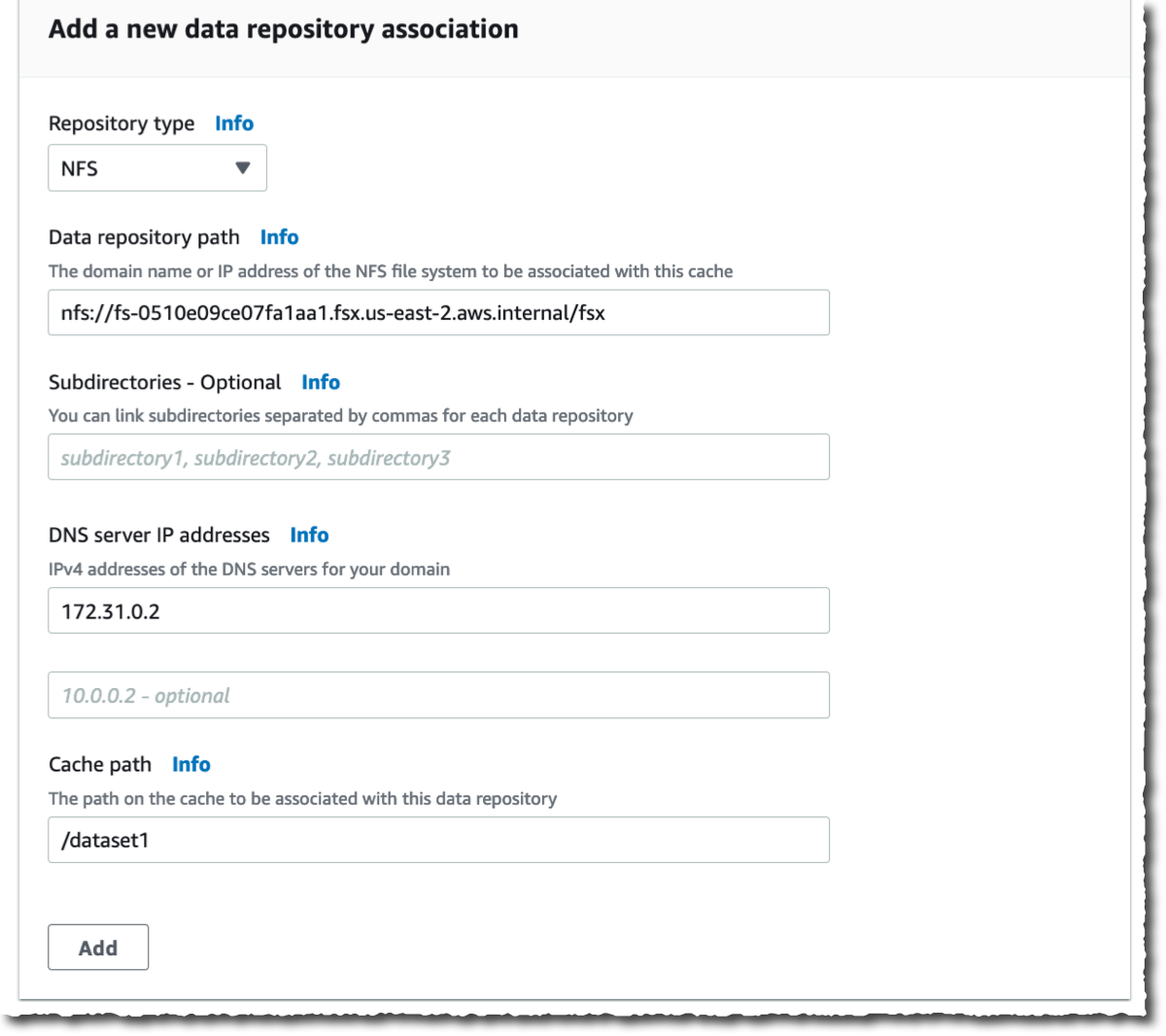
Entonces, creo Asociación de repositorios de datos. Este es el enlace entre el caché y una fuente de datos. Una fuente de datos puede ser un sistema de archivos NFS o un depósito o prefijo de S3. Podría crear hasta ocho asociaciones de repositorios de datos para un caché. Todas las asociaciones de repositorios de datos para un caché tienen el mismo tipo: todas son NFS v3 o todas S3. Si necesita ambos, puede crear dos cachés.
En esta demostración, elijo vincular dos sistemas de archivos OpenZFS en mi cuenta de AWS. Puede vincular a cualquier servidor NFS v3, incluidos los que ya tiene en las instalaciones. Ruta de caché le permite elegir dónde se montará el sistema de archivos de origen en la memoria caché. los Ruta del repositorio de datos es la URL de su repositorio de datos NFS v3 o S3. el formato es nfs://hostname/path o s3://bucketname/path.
los Direcciones IP del servidor DNS permite que File Cache resuelva el nombre DNS de su servidor NFS. Esto es útil cuando la resolución de DNS es privada, como en mi ejemplo. Cuando asocia servidores NFS v3 implementados en una VPC y cuando utiliza el servidor DNS proporcionado por AWS, la dirección IP del servidor DNS de su VPC es el rango de VPC + dos. En mi ejemplo, mi VPC CIDR el rango es 172.31.0.0por lo tanto, la dirección IP del servidor DNS es 172.31.0.2.
No olvides hacer clic en el Agregar ¡botón! De lo contrario, su entrada es ignorada. Puede repetir la operación para agregar más repositorios de datos.
 |
 |
Una vez que he ingresado a mis dos repositorios de datos, selecciono próximo, y reviso mis opciones. Cuando estoy listo, selecciono Crear caché.

Después de unos minutos, el estado del caché pasa a ser ✅ Disponible.

La última parte es montar el caché en la máquina donde se implementa mi carga de trabajo. File Cache usa Lustre detrás de escena. Primero tengo que instalar el cliente Lustre para Linux, como se explica en nuestra documentación. Una vez hecho esto, selecciono el Adjuntar en la consola para recibir las instrucciones para descargar e instalar el cliente Lustre y para montar el sistema de archivos de caché. Para hacerlo, me conecto a una instancia EC2 que se ejecuta en la misma VPC. Luego escribo:
Para hacerlo, me conecto a una instancia EC2 que se ejecuta en la misma VPC. Luego escribo:
sudo mount -t lustre -o relatime,flock file_cache_dns_name@tcp:/mountname /mntEste comando monta mi caché con dos opciones:
relatime– Mantieneatime(tiempos de acceso al inodo), pero no por cada vez que se accede a un archivo. Con esta opción habilitada,atimelos datos se escriben en el disco solo si el archivo ha sido modificado desde laatimelos datos se actualizaron por última vez (mtime) o si se accedió al archivo por última vez hace más de una cierta cantidad de tiempo (un día de forma predeterminada).relatimees necesario para que el desalojo automático de caché funcione correctamente.flock– Habilita el bloqueo de archivos para su caché. Si no desea habilitar el bloqueo de archivos, use el comando de montaje sin rebaño.
Una vez montados, los procesos que se ejecutan en mi instancia EC2 pueden acceder a los archivos en el caché como de costumbre. Como definí en el momento de la creación del caché, el primer sistema de archivos ZFS está disponible dentro del caché en /dataset1y el segundo sistema de archivos ZFS está disponible como /dataset2.
$ echo "Hello File Cache World" > /mnt/zsf1/greetings
$ sudo mount -t lustre -o relatime,flock fc-0280000000001.fsx.us-east-2.aws.internal@tcp:/r3xxxxxx /mnt/cache
$ ls -al /mnt/cache
total 98
drwxr-xr-x 5 root root 33280 Sep 21 14:37 .
drwxr-xr-x 2 root root 33280 Sep 21 14:33 dataset1
drwxr-xr-x 2 root root 33280 Sep 21 14:37 dataset2
$ cat /mnt/cache/dataset1/greetings
Hello File Cache World
Puedo observar y medir la actividad y el estado de mis cachés utilizando las métricas de Amazon CloudWatch y el monitoreo de registros de AWS CloudTrail.
Las métricas de CloudWatch para un recurso de caché de archivos se organizan en tres categorías:
- Métricas de E/S front-end
- Métricas de E/S de back-end
- Métricas de uso de front-end de caché
Como de costumbre, puedo crear paneles o definir alarmas para recibir información cuando las métricas alcancen los umbrales que definí.
Cosas a tener en cuenta
Hay un par de puntos clave a tener en cuenta al usar o planear usar File Cache.
En primer lugar, File Cache cifra los datos en reposo y admite el cifrado de datos en tránsito. Sus datos siempre se cifran en reposo mediante claves administradas en AWS Key Management Service (AWS KMS). Puede usar claves de propiedad del servicio o sus propias claves (CMK administradas por el cliente).
En segundo lugar, File Cache ofrece dos opciones para importar datos desde sus repositorios de datos al caché: carga diferida y precarga. La carga diferida importa datos a pedido si aún no están almacenados en caché, y la carga previa importa datos a pedido del usuario antes de comenzar su carga de trabajo. La carga diferida es la predeterminada. Tiene sentido para la mayoría de las cargas de trabajo, ya que permite que su carga de trabajo comience sin esperar a que los metadatos y los datos se importen a la memoria caché. La carga previa es útil cuando su patrón de acceso es sensible a las latencias del primer byte.
Precios y disponibilidad
No hay costos por adelantado o de precio fijo cuando se usa File Cache. Se le factura por la capacidad de almacenamiento en caché aprovisionada y la capacidad de almacenamiento de metadatos. La página de precios tiene los detalles. Además de File Cache en sí, usted paga los costos de solicitud de S3, los cargos de AWS Direct Connect y los cargos habituales de transferencia de datos para el tráfico entre zonas de disponibilidad, entre regiones y de salida de Internet entre File Cache y las fuentes de datos.
File Cache está disponible en EE. UU. Este (Ohio), EE. UU. Este (Norte de Virginia), EE. UU. Oeste (Oregón), Asia Pacífico (Singapur), Asia Pacífico (Sídney), Asia Pacífico (Tokio), Canadá (Central), Europa ( Frankfurt), Europa (Irlanda) y Europa (Londres).
¡Ahora vaya a construir y cree su primer caché de archivos hoy!

