|
|
En AWS re:Invent 2021, presentamos tres nuevas opciones sin servidor para nuestros servicios de análisis de datos: Amazon EMR Serverless, Amazon Redshift Serverless y Amazon MSK Serverless, que facilitan el análisis de datos a cualquier escala sin tener que configurar, escalar o gestionar la infraestructura subyacente.
Hoy anunciamos la disponibilidad general de Amazon EMR Serverless, una opción de implementación sin servidor para que los clientes ejecuten aplicaciones de análisis de big data utilizando marcos de código abierto como Apache Spark y Hive sin configurar, administrar ni escalar clústeres o servidores.

Con EMR Serverless, puede ejecutar cargas de trabajo de análisis a cualquier escala con escalado automático que cambia el tamaño de los recursos en segundos para cumplir con los requisitos de procesamiento y los volúmenes de datos cambiantes. EMR Serverless escala automáticamente los recursos hacia arriba y hacia abajo para proporcionar la cantidad justa de capacidad para su aplicación, y solo paga por lo que usa.
Durante la vista previa, escuchamos de los clientes que EMR Serverless es rentable porque no incurren en costos por tener que aprovisionar recursos en exceso para hacer frente a los picos de demanda. No tienen que preocuparse por el tamaño correcto de las instancias o la aplicación de actualizaciones del sistema operativo, y pueden concentrarse en llevar los productos al mercado más rápido.
Amazon EMR ofrece varias opciones de implementación para ejecutar aplicaciones que se ajusten a diversas necesidades, como clústeres de EMR en Amazon Elastic Compute Cloud (Amazon EC2), clústeres de Amazon Elastic Kubernetes Service (Amazon EKS), AWS Outposts o EMR Serverless.
- EMR en clústeres de Amazon EC2 es adecuado para clientes que necesitan el máximo control y flexibilidad sobre cómo ejecutar su aplicación. Con los clústeres de EMR, los clientes pueden elegir el tipo de instancia EC2 para mejorar el rendimiento de ciertas aplicaciones, personalizar la imagen de máquina de Amazon (AMI), elegir la configuración de la instancia EC2, personalizar y ampliar los marcos de código abierto e instalar software personalizado adicional en las instancias del clúster.
- EMR en Amazon EKS es adecuado para clientes que desean estandarizar EKS para administrar clústeres entre aplicaciones o usar diferentes versiones de un marco de código abierto en el mismo clúster.
- EMR en AWS Outposts es para clientes que desean ejecutar EMR más cerca de su centro de datos dentro de Outpost.
- EMR Serverless es adecuado para clientes que desean evitar la administración y operación de clústeres y simplemente desean ejecutar aplicaciones utilizando marcos de código abierto.
Además, cuando crea una aplicación con una versión de EMR (por ejemplo, un trabajo de Spark con la versión 6.4 de EMR), puede optar por ejecutarla en un clúster de EMR, EMR en EKS o EMR sin servidor sin tener que volver a escribir la aplicación. Esto le permite crear aplicaciones para una versión de marco determinada y conservar la flexibilidad para cambiar el modelo de implementación en función de las necesidades operativas futuras.
Introducción a Amazon EMR sin servidor
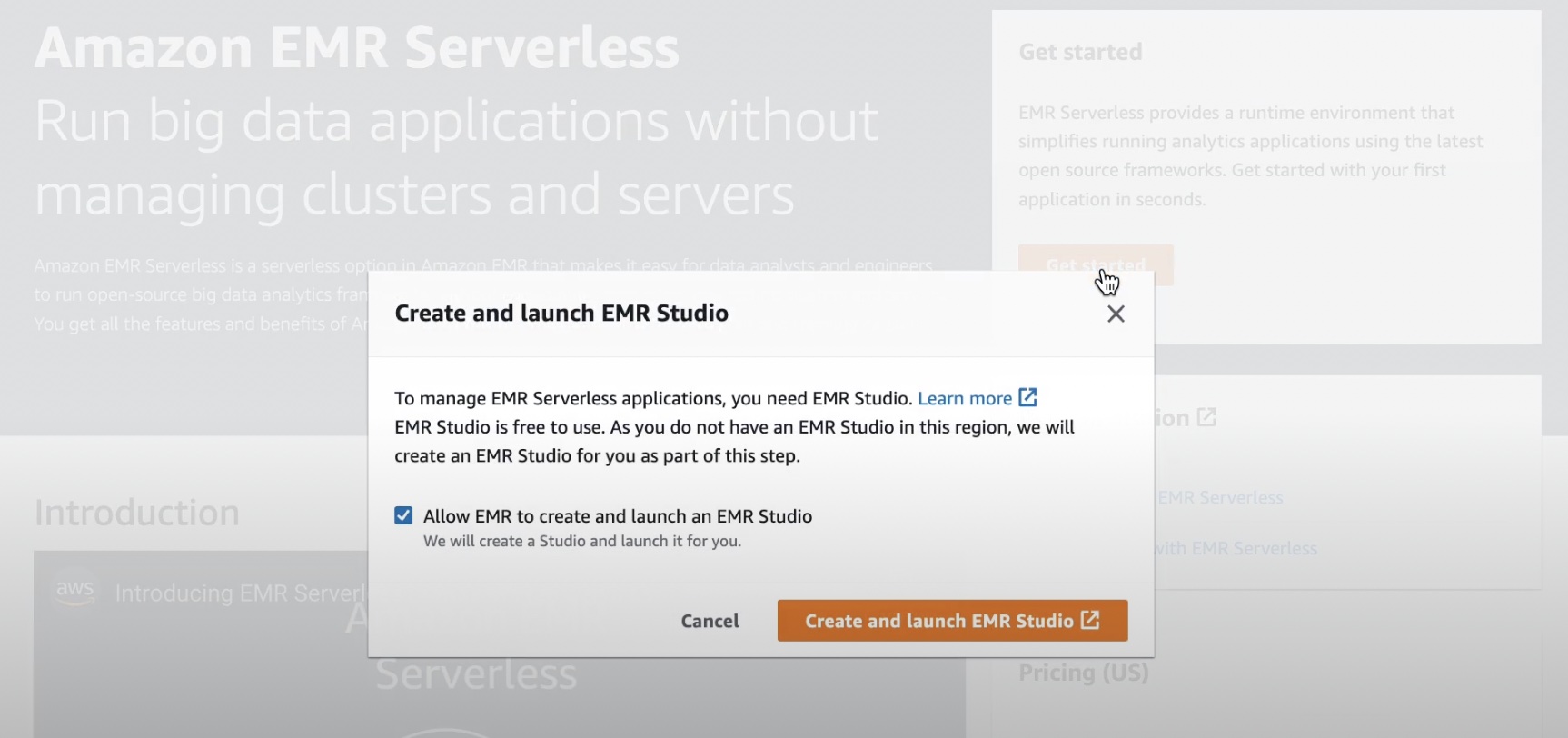
Para comenzar con EMR Serverless, puede usar Amazon EMR Studio, una característica gratuita de EMR que proporciona una experiencia de depuración y desarrollo integral. Con EMR Studio, puede crear aplicaciones EMR sin servidor (Spark o Hive), elegir la versión de software de código abierto para su aplicación, enviar trabajos, verificar el estado de los trabajos en ejecución e invocar Spark UI o Tez UI para diagnósticos de trabajos.
Cuando seleccionas el Empezar en EMR Serverless Console, puede crear y configurar EMR Studio con aplicaciones EMR Serverless preconfiguradas.
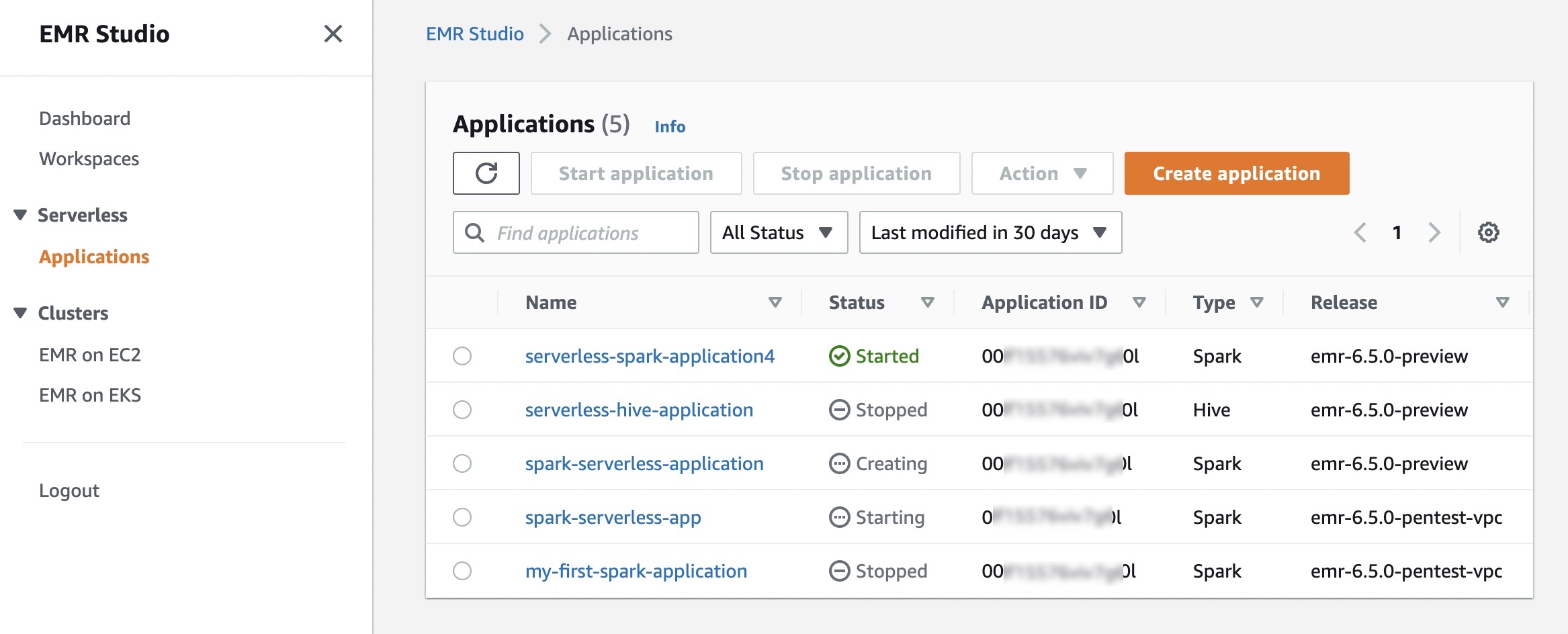
En EMR Studio, cuando elige Aplicaciones en el menú Serverless, puede crear una o más aplicaciones EMR Serverless y elegir el marco de código abierto y la versión para su caso de uso. Si desea entornos lógicos independientes para pruebas y producción o para diferentes casos de uso de línea de negocio, puede crear aplicaciones independientes para cada entorno lógico.
Una aplicación sin servidor de EMR es una combinación de (a) la versión de lanzamiento de EMR para la versión del marco de código abierto que desea usar y (b) el tiempo de ejecución específico que desea que use su aplicación, como Apache Spark o Apache Hive.
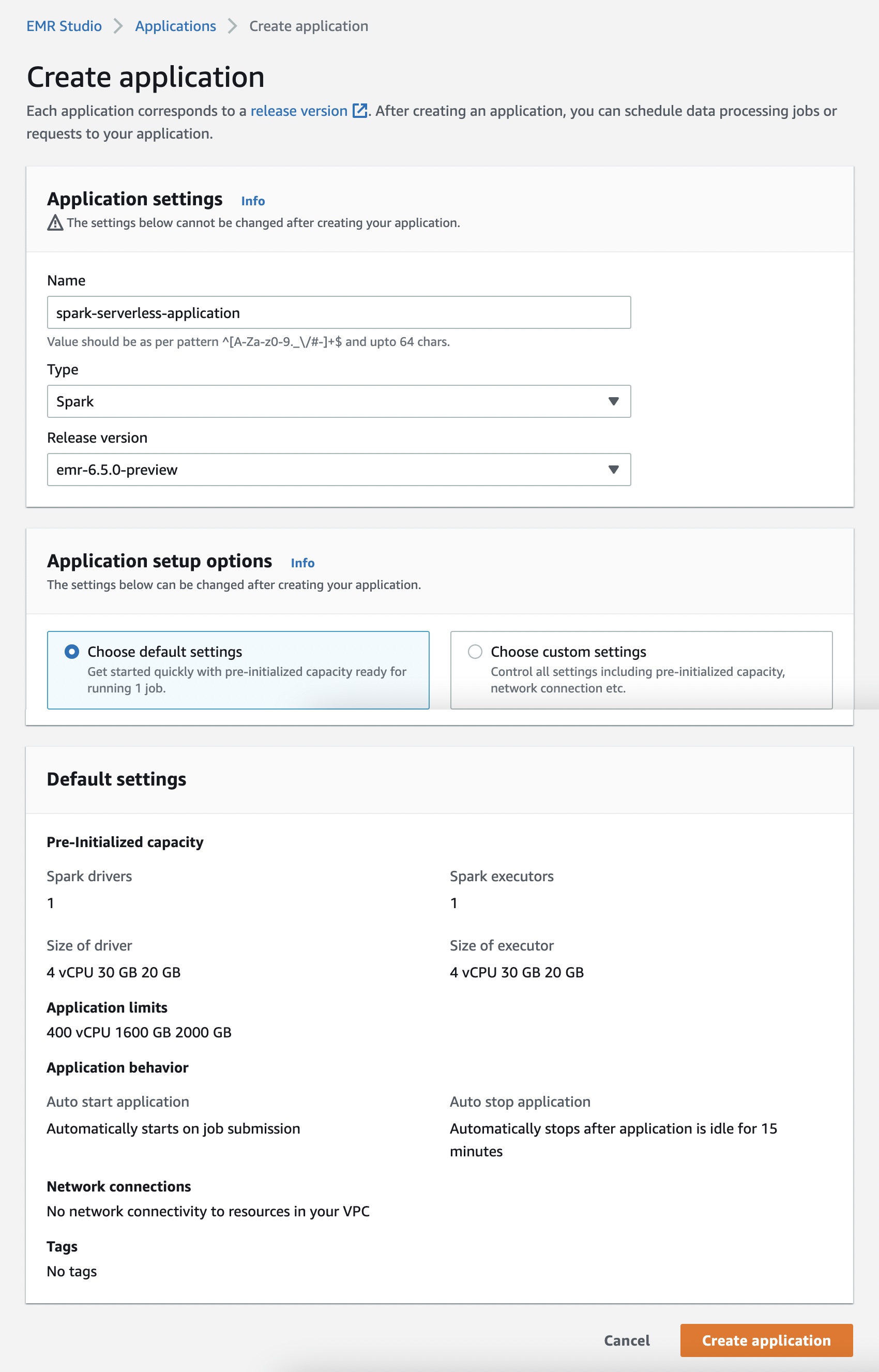
cuando eliges Crear aplicaciónpuede configurar su aplicación Nombre, Escribe de Spark o Hive, y compatible Rpor favor versión. También puede seleccionar la opción de configuración predeterminada o personalizada para la capacidad preiniciada, los límites de la aplicación y las opciones de conectividad de Amazon Virtual Private Cloud (Amazon VPC). Cada aplicación EMR Serverless está aislada de otras aplicaciones y se ejecuta dentro de una VPC segura.
Utilice la opción predeterminada si desea que los trabajos comiencen inmediatamente. Pero se aplican cargos por cada trabajador cuando se inicia la aplicación. Para obtener más información sobre la capacidad inicializada previamente, consulte Configuración y administración de la capacidad inicializada previamente.
cuando seleccionas Iniciar aplicación, su aplicación está configurada para comenzar con una capacidad preiniciada de 1 controlador Spark y 1 ejecutor Spark. Su aplicación está configurada de forma predeterminada para iniciarse cuando se envían trabajos y detenerse cuando la aplicación está inactiva durante más de 15 minutos.
Puede personalizar esta configuración y configurar diferentes límites de aplicación seleccionando Elija configuraciones personalizadas.
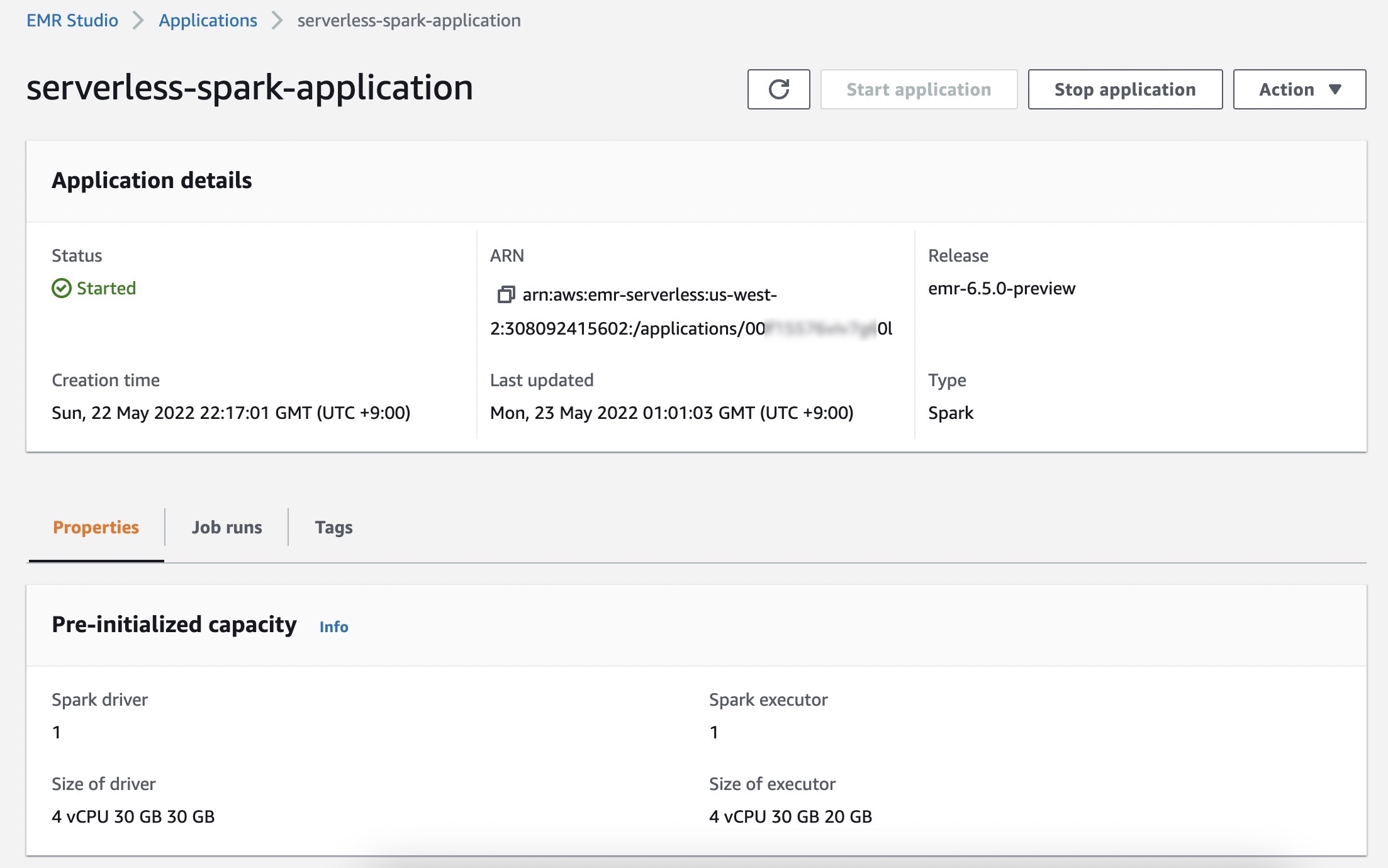
En el Ejecuciones de trabajo menú, puede ver una lista de trabajos ejecutados para su aplicación.
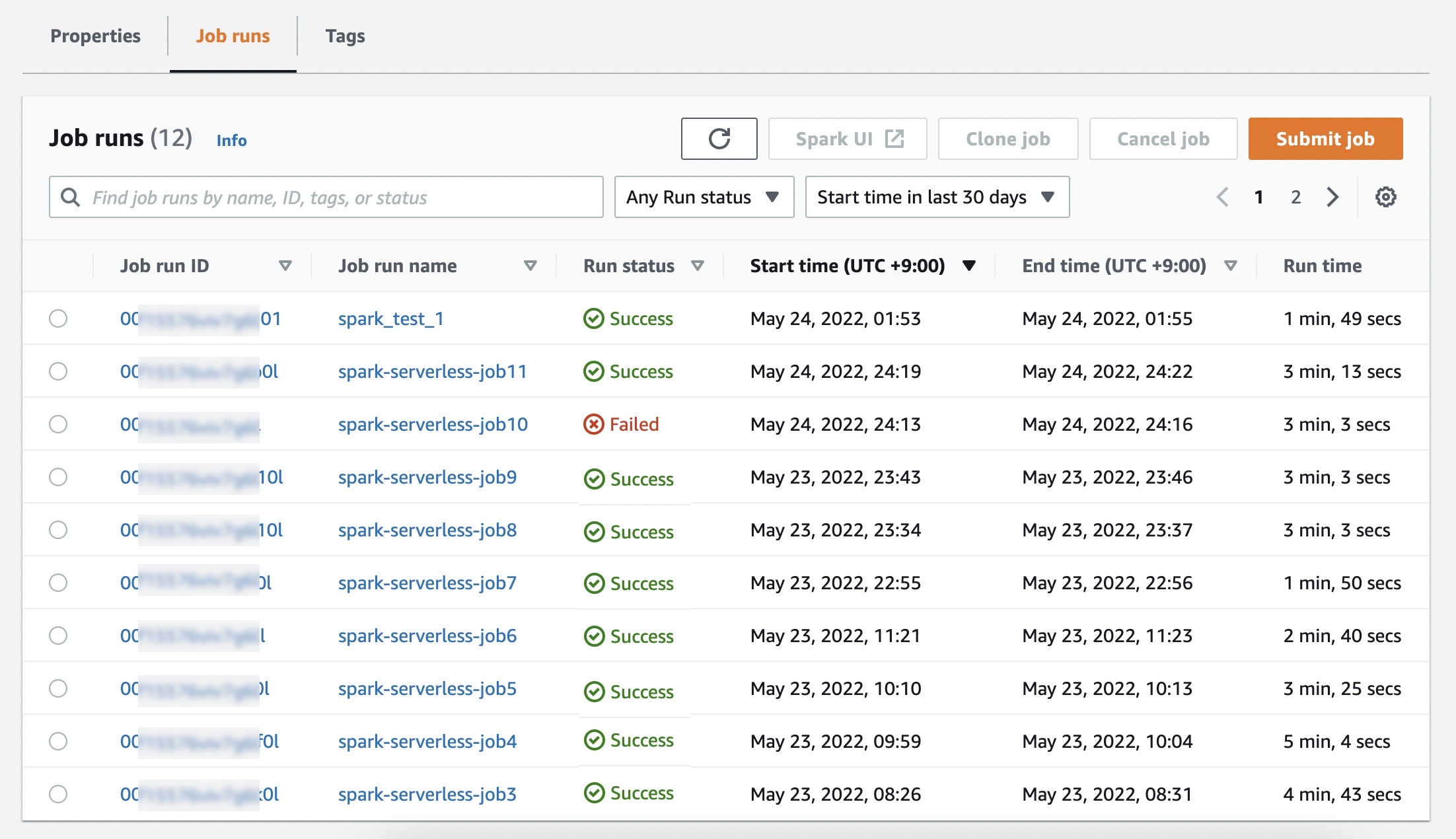
Elegir Enviar trabajo y configure los detalles del trabajo, como el nombre, el rol de AWS Identity and Access Management (IAM) utilizado por el trabajo, la ubicación del script y los argumentos del script JAR o Python en el depósito de Amazon Simple Storage Service (Amazon S3) que desea correr.
Si desea que los registros de sus trabajos de Spark o Hive se envíen a su depósito de S3, deberá configurar el depósito de S3 en la misma región en la que está ejecutando trabajos sin servidor de EMR.
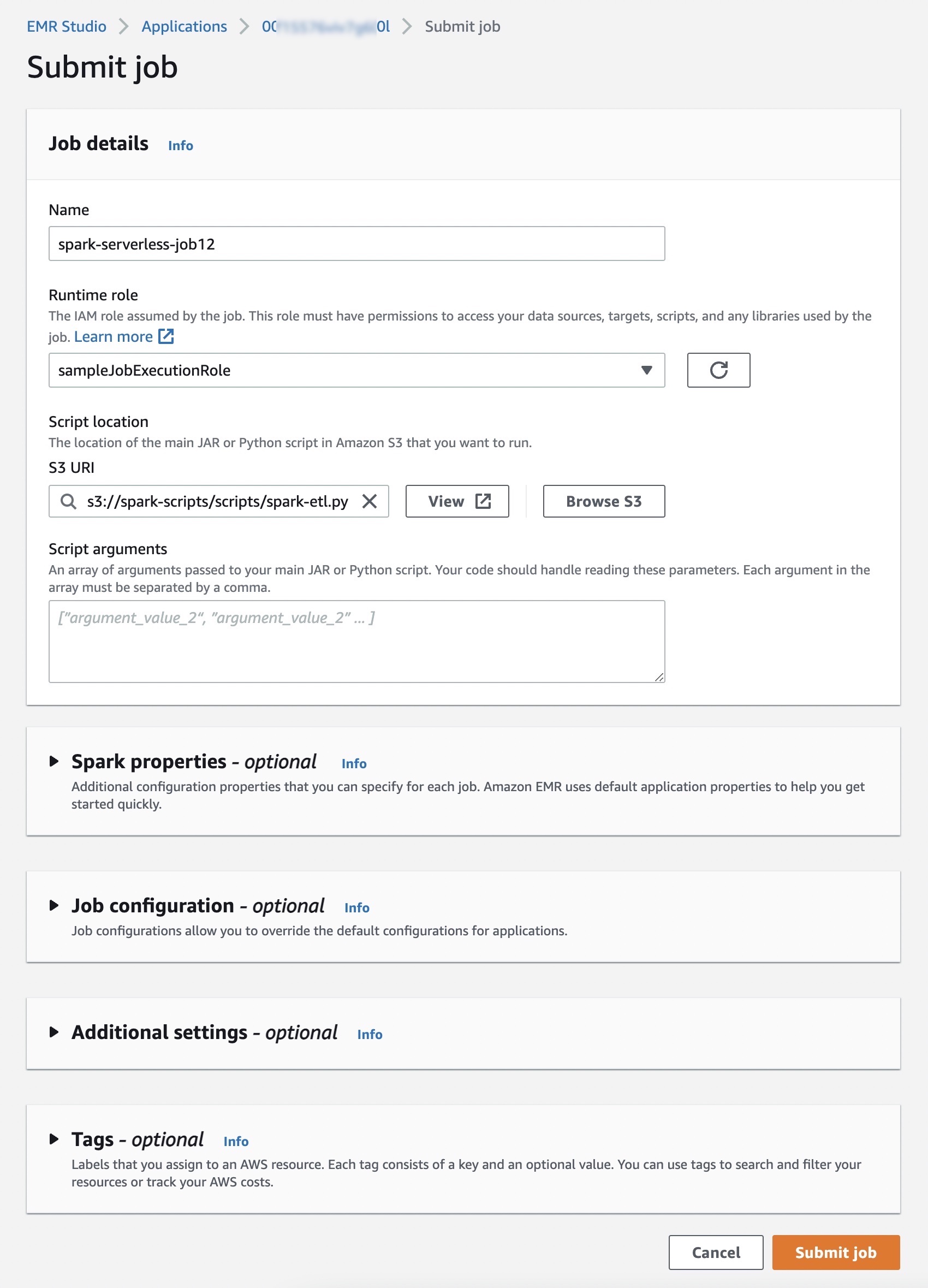
Opcionalmente, puede establecer propiedades de configuración adicionales que puede especificar para cada trabajo, como propiedades de Spark, configuraciones de trabajo para anular las configuraciones predeterminadas para las aplicaciones (como el uso de AWS Glue Data Catalog como metaalmacén), almacenamiento de registros en Amazon S3, y conservar los registros durante 30 días.
El siguiente es un ejemplo de cómo ejecutar un script de Python usando el StartJobRun API.
$ aws emr-serverless start-job-run \
--application-id <application_id> \
--execution-role-arn <iam_role_arn> \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://spark-scripts/scripts/spark-etl.py",
"entryPointArguments": "s3://spark-scripts/output",
"sparkSubmitParameters": "--conf spark.executor.cores=1 --conf spark.executor.memory=4g --conf spark.driver.cores=1 --conf spark.driver.memory=4g --conf spark.executor.instances=1"
}
}' \
--configuration-overrides '{
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://spark-scripts/logs/"
}
}
}'Puede verificar los resultados del trabajo en su depósito S3. Para obtener más información, puede utilizar la interfaz de usuario de Spark para la aplicación Spark y la interfaz de usuario de Hive/Tez en el Ejecuciones de trabajo para comprender cómo se ejecutó el trabajo o para depurarlo si falla.
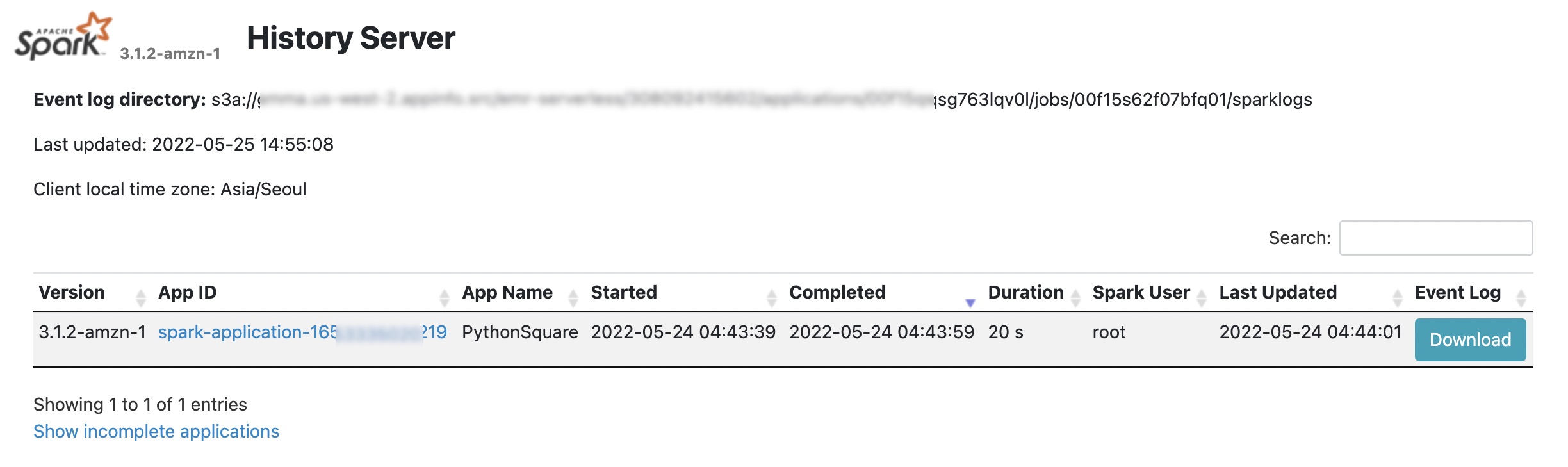
Para más depuración, EMR Serverless enviará registros de eventos al sparklogs carpeta en su destino de registro S3 para aplicaciones Spark. En el caso de las aplicaciones de Hive, EMR Serverless cargará continuamente el controlador de Hive y los registros de tareas de Tez en el HIVE_DRIVER o TEZ_TASK carpetas de su destino de registro S3. Para obtener más información, consulte Inicio de sesión en la documentación de AWS.
Cosas que saber
Con EMR Serverless, puede obtener todos los beneficios de ejecutar Amazon EMR. Quiero citar algunas cosas que debe saber sobre EMR Serverless de una publicación del blog de Big Data de AWS de anuncios de vista previa:
- Escalado automático y de grano fino – EMR Serverless escala automáticamente a los trabajadores en cada etapa del procesamiento de su trabajo y los reduce cuando no son necesarios. Se le cobra por los recursos agregados de vCPU, memoria y almacenamiento utilizados desde el momento en que un trabajador comienza a ejecutarse hasta que se detiene, redondeado al segundo más cercano con un mínimo de 1 minuto. Por ejemplo, su trabajo puede requerir 10 trabajadores durante los primeros 10 minutos de procesamiento del trabajo y 50 trabajadores durante los próximos 5 minutos. Con el escalado automático detallado, solo incurre en costos para 10 trabajadores por 10 minutos y 50 trabajadores por 5 minutos. Como resultado, no tiene que pagar por recursos infrautilizados.
- Resistencia a los errores de la zona de disponibilidad – EMR Serverless es un servicio regional. Cuando envía trabajos a una aplicación sin servidor de EMR, puede ejecutarse en cualquier zona de disponibilidad de la región. En caso de que una zona de disponibilidad esté dañada, un trabajo enviado a su aplicación EMR Serverless se ejecuta automáticamente en una zona de disponibilidad diferente (en buen estado). Al usar recursos en una VPC privada, EMR Serverless recomienda que especifique la configuración de VPC privada para varias zonas de disponibilidad para que EMR Serverless pueda seleccionar automáticamente una zona de disponibilidad saludable.
- Habilitar aplicaciones compartidas – Cuando envía trabajos a una aplicación sin servidor de EMR, puede especificar el rol de IAM que debe usar el trabajo para acceder a los recursos de AWS, como los objetos de S3. Como resultado, diferentes entidades principales de IAM pueden ejecutar trabajos en una sola aplicación sin servidor de EMR, y cada trabajo solo puede acceder a los recursos de AWS a los que la entidad principal de IAM puede acceder. Esto le permite configurar escenarios en los que una sola aplicación con un grupo de trabajadores preinicializado se pone a disposición de varios inquilinos en los que cada inquilino puede enviar trabajos con un rol de IAM diferente pero usar el grupo común de trabajadores preinicializados para procesar solicitudes de inmediato. .
Ya disponible
Amazon EMR Serverless está disponible en las regiones de EE. UU. Este (Norte de Virginia), EE. UU. Oeste (Oregón), Europa (Irlanda) y Asia Pacífico (Tokio). Con EMR Serverless, no hay costos iniciales y solo paga por los recursos que utiliza. Usted paga por la cantidad de vCPU, memoria y recursos de almacenamiento consumidos por sus aplicaciones. Para obtener detalles sobre los precios, consulte la página de precios de EMR Serverless.
Para obtener más información, visite la Guía del usuario sin servidor de Amazon EMR y códigos de muestra con Apache Spark y Apache Hive. Envíe sus comentarios a AWS re:Post para Amazon EMR sin servidor o a través de sus contactos habituales de soporte de AWS.
Conozca todos los detalles sobre Amazon EMR Serverless y comience hoy mismo.
– channy

