
|
|
Hoy estamos muy emocionados de anunciar que Amazon Aurora Serverless v2 está generalmente disponible para Aurora PostgreSQL y MySQL. Aurora Serverless es una configuración de escalado automático bajo demanda para Amazon Aurora que permite que su base de datos amplíe o reduzca la capacidad en función de las necesidades de su aplicación.
Amazon Aurora es una base de datos relacional compatible con MySQL y PostgreSQL creada para la nube. Está completamente administrado por Amazon Relational Database Service (RDS), que automatiza las tareas administrativas que consumen mucho tiempo, como el aprovisionamiento de hardware, la configuración de la base de datos, los parches y las copias de seguridad.
Una de las características clave de Amazon Aurora es la separación de computación y almacenamiento. Como resultado, se escalan de forma independiente. El almacenamiento de Amazon Aurora escala automáticamente a medida que aumenta la cantidad de datos en su base de datos. Por ejemplo, puede almacenar muchos datos y, si un día decide eliminar la mayoría de los datos, el almacenamiento aprovisionado se ajusta.
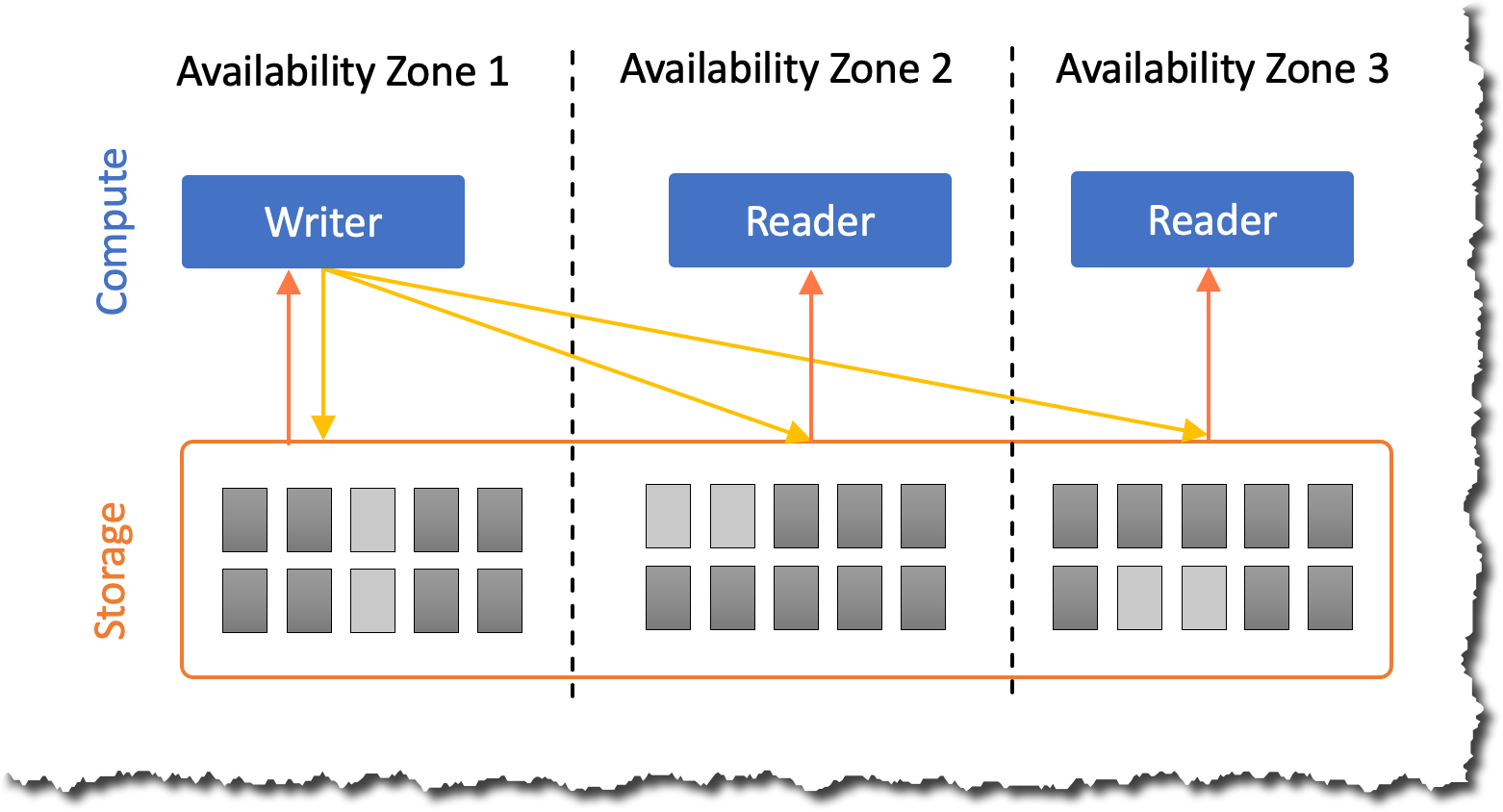
Sin embargo, muchos clientes dijeron que necesitan la misma flexibilidad en la capa de cómputo de Amazon Aurora, ya que la mayoría de las cargas de trabajo de la base de datos no necesitan una cantidad constante de cómputo. Las cargas de trabajo pueden tener picos, ser poco frecuentes o tener picos predecibles durante un período de tiempo.
Para atender este tipo de cargas de trabajo, debe aprovisionar la capacidad máxima que espera que necesite su base de datos. Sin embargo, este enfoque es costoso ya que las cargas de trabajo de la base de datos rara vez se ejecutan al máximo de su capacidad. Para aprovisionar la cantidad correcta de cómputo, debe monitorear continuamente el consumo de capacidad de la base de datos y escalar los recursos si el consumo es alto. Sin embargo, esto requiere experiencia y, a menudo, genera tiempo de inactividad.
Para solucionar este problema, en 2018 lanzamos la primera versión de Amazon Aurora Serverless. Desde su lanzamiento, miles de clientes han utilizado Amazon Aurora Serverless como una opción rentable para cargas de trabajo poco frecuentes, intermitentes e impredecibles.
Hoy, estamos haciendo que la próxima versión de Amazon Aurora Serverless esté disponible para el público en general, lo que permite a los clientes ejecutar incluso la carga de trabajo más exigente sin servidor con escalado instantáneo y sin interrupciones, ajustes de capacidad detallados y funcionalidad adicional, incluidas réplicas de lectura, Multi-AZ implementaciones y la base de datos global de Amazon Aurora.
Aurora Serverless v2 se lanza con las últimas versiones principales disponibles en Amazon Aurora. Versiones compatibles: edición compatible con Aurora PostgreSQL con PostgreSQL 13 y edición compatible con Aurora MySQL con MySQL 8.0.
Características principales de Aurora Serverless v2
Aurora Serverless v2 le permite escalar su base de datos a cientos de miles de transacciones por segundo y administrar de manera rentable las cargas de trabajo más exigentes. Escala la capacidad de la base de datos en incrementos detallados para adaptarse a las necesidades de su carga de trabajo sin interrumpir las conexiones ni las transacciones. Además, solo paga por la capacidad exacta que consume y puede ahorrar hasta un 90 % en comparación con el aprovisionamiento para la carga máxima.
Si tiene un clúster de Amazon Aurora existente, puede crear una instancia de Aurora Serverless v2 dentro del mismo clúster. De esta forma, tendrá un clúster de configuración mixta donde las instancias aprovisionadas y Aurora Serverless v2 pueden coexistir dentro del mismo clúster.
Es compatible con la gama completa de funciones de Amazon Aurora. Por ejemplo, puede crear hasta 15 réplicas de lectura de Amazon Aurora implementadas en varias zonas de disponibilidad. Cualquier cantidad de estas réplicas de lectura pueden ser instancias de Aurora Serverless v2 y se pueden usar como destinos de conmutación por error para alta disponibilidad o para escalar operaciones de lectura.
De manera similar, con Global Database, puede asignar cualquiera de las instancias para que sea Aurora Serverless v2 y solo pague por la capacidad mínima cuando esté inactiva. Estas instancias en regiones secundarias también se pueden escalar de forma independiente para admitir diferentes cargas de trabajo en diferentes regiones. Consulte la guía del usuario de Amazon Aurora para obtener una lista completa de funciones.
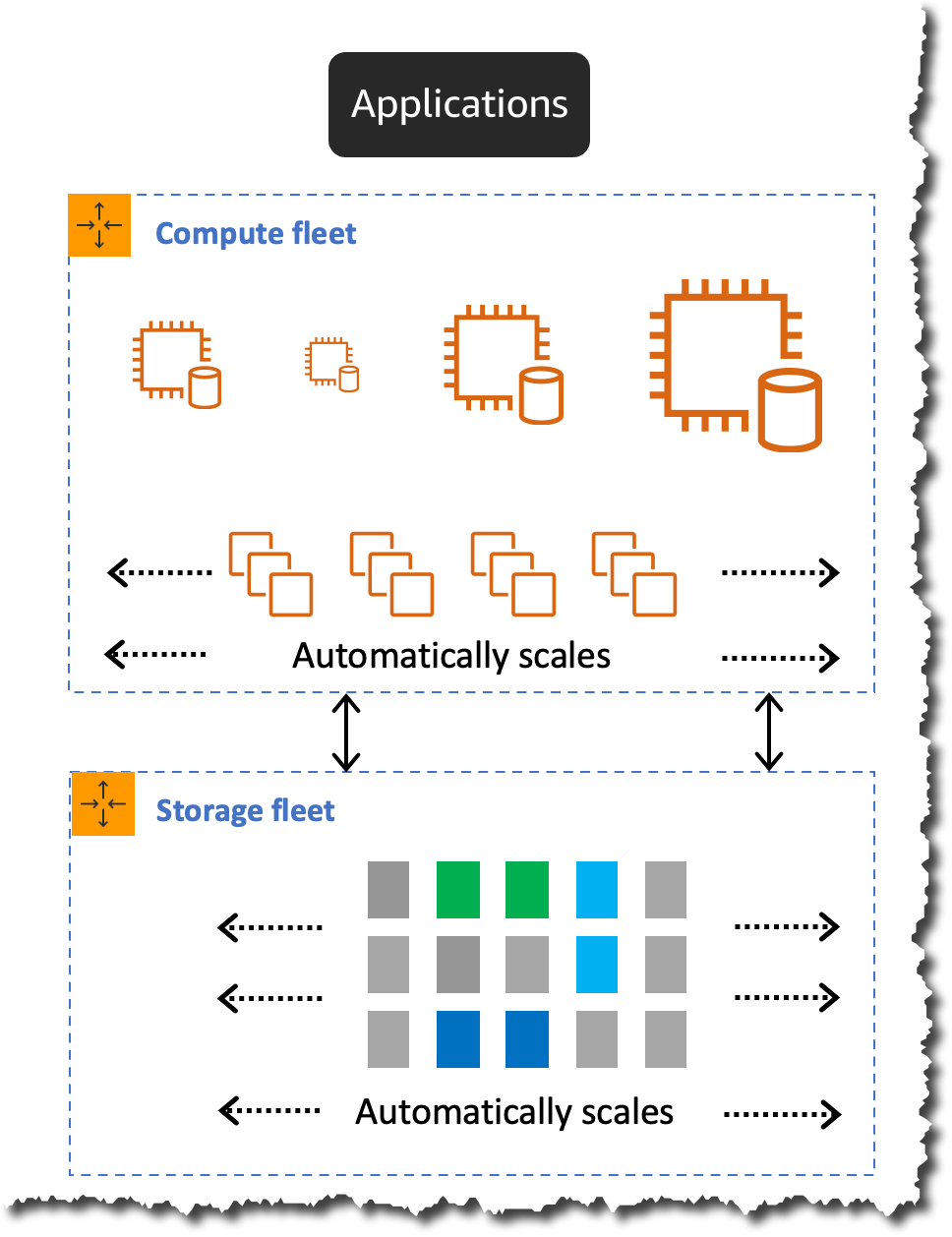
Cómo funciona el escalado de Aurora Serverless v2
Aurora Serverless v2 se escala al instante y sin interrupciones al aumentar la capacidad de la instancia subyacente agregando más recursos de memoria y CPU. Esta técnica permite que la instancia subyacente aumente y disminuya la capacidad en el lugar sin pasar por error a una nueva instancia para escalar.
Para escalar hacia abajo, Aurora Serverless v2 adopta un enfoque más conservador. Se reduce gradualmente hasta que alcanza la capacidad necesaria para la carga de trabajo. Reducir la escala demasiado rápido puede desalojar prematuramente las páginas almacenadas en caché y disminuir el grupo de búfer, lo que puede afectar el rendimiento.
La capacidad de Aurora Serverless se mide en unidades de capacidad de Aurora (ACU). Cada ACU es una combinación de aproximadamente 2 gibibytes (GiB) de memoria, CPU correspondiente y red. Con Aurora Serverless v2, su capacidad inicial puede ser tan pequeña como 0,5 ACU y la capacidad máxima admitida es de 128 ACU. Además, admite incrementos detallados tan pequeños como 0,5 ACU, lo que permite que la capacidad de su base de datos coincida con las necesidades de la carga de trabajo.
Escalado de Aurora Serverless v2 en acción
Para mostrar Aurora Serverless v2 en acción, vamos a simular una venta relámpago. Imagina que tienes un sitio de comercio electrónico. Ejecuta una campaña de marketing en la que los clientes pueden comprar artículos con un 50 por ciento de descuento durante un período de tiempo limitado. Está esperando un aumento en el tráfico en su sitio durante la duración de la venta.
Cuando usa una base de datos tradicional, si ejecuta esas campañas de marketing con regularidad, debe aprovisionarse para la carga máxima que espera. O, si los ejecuta de vez en cuando, necesita reconfigurar su base de datos para el pico de tráfico esperado durante la venta. En ambos casos, está limitado a su suposición de la capacidad que necesita. ¿Qué pasa si tienes más ventas de las que esperabas? Si su base de datos no puede mantenerse al día con la demanda, puede provocar la degradación del servicio. ¿O cuando su campaña de marketing no produce las ventas que esperaba? Está pagando innecesariamente por capacidad que no necesita.
Para esta demostración, usamos Aurora Serverless v2 como base de datos transaccional. Se utiliza una función de AWS Lambda para llamar a la base de datos y procesar los pedidos durante el evento de venta del sitio de comercio electrónico. La función Lambda y la base de datos están en la misma Amazon Virtual Private Cloud (VPC), y la función se conecta directamente a la base de datos para realizar todas las operaciones.
Para simular el tráfico de una venta flash, utilizaremos un marco de prueba de carga de código abierto llamado Artillería. Nos permitirá generar una carga variable al invocar múltiples funciones de Lambda. Por ejemplo, podemos comenzar con una carga pequeña y luego aumentarla rápidamente para observar cómo se ajusta la capacidad de la base de datos según la carga de trabajo. Esta prueba de carga de Artillery se ejecuta en una instancia de Amazon Elastic Compute Cloud (Amazon EC2) dentro de la misma VPC.
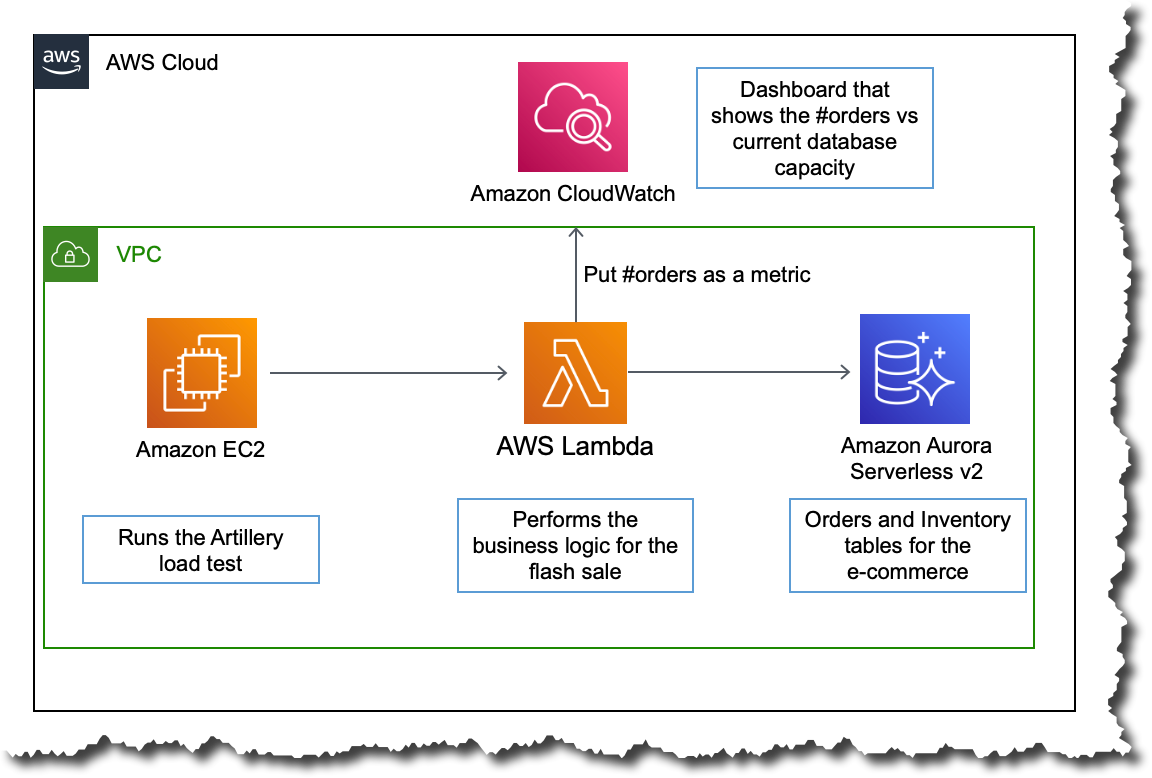
El siguiente panel de control de Amazon CloudWatch muestra cómo se comporta la capacidad de la base de datos cuando aumenta el recuento de pedidos. El tablero muestra los pedidos realizados en azul y la capacidad actual de la base de datos en naranja.
Al comienzo de la venta, la base de datos Aurora Serverless v2 comienza con una capacidad de 5 ACU, que era la capacidad mínima de base de datos configurada. Durante los primeros minutos, los pedidos aumentan, pero la capacidad de la base de datos no aumenta de inmediato. La base de datos puede manejar la carga con la capacidad aprovisionada inicial.
Sin embargo, alrededor de las 15:55, el número de pedidos aumenta a 12.000. Como resultado, la base de datos aumenta la capacidad a 14 ACU. La capacidad de la base de datos aumenta en milisegundos, ajustándose exactamente a la carga.
El número de pedidos realizados se mantiene durante unos segundos y luego se reduce drásticamente a las 15:58. Sin embargo, la capacidad de la base de datos no se ajusta exactamente a la caída del tráfico. En cambio, disminuye en pasos hasta llegar a 5 ACU. La reducción se realiza de manera más conservadora para evitar expulsar prematuramente las páginas almacenadas en caché y afectar el rendimiento. Esto se hace para evitar cualquier latencia innecesaria en las cargas de trabajo con picos y también para que las memorias caché y los grupos de búfer no se purguen agresivamente.

Comience con Aurora Serverless v2 con un clúster de Amazon Aurora existente
Si ya tiene un clúster de Amazon Aurora y desea probar Aurora Serverless v2, la forma más rápida de comenzar es usar clústeres de configuración mixta que contengan instancias sin servidor y aprovisionadas. Comience agregando un nuevo lector al clúster existente. Configure la instancia del lector para que sea del tipo Sin servidor v2.
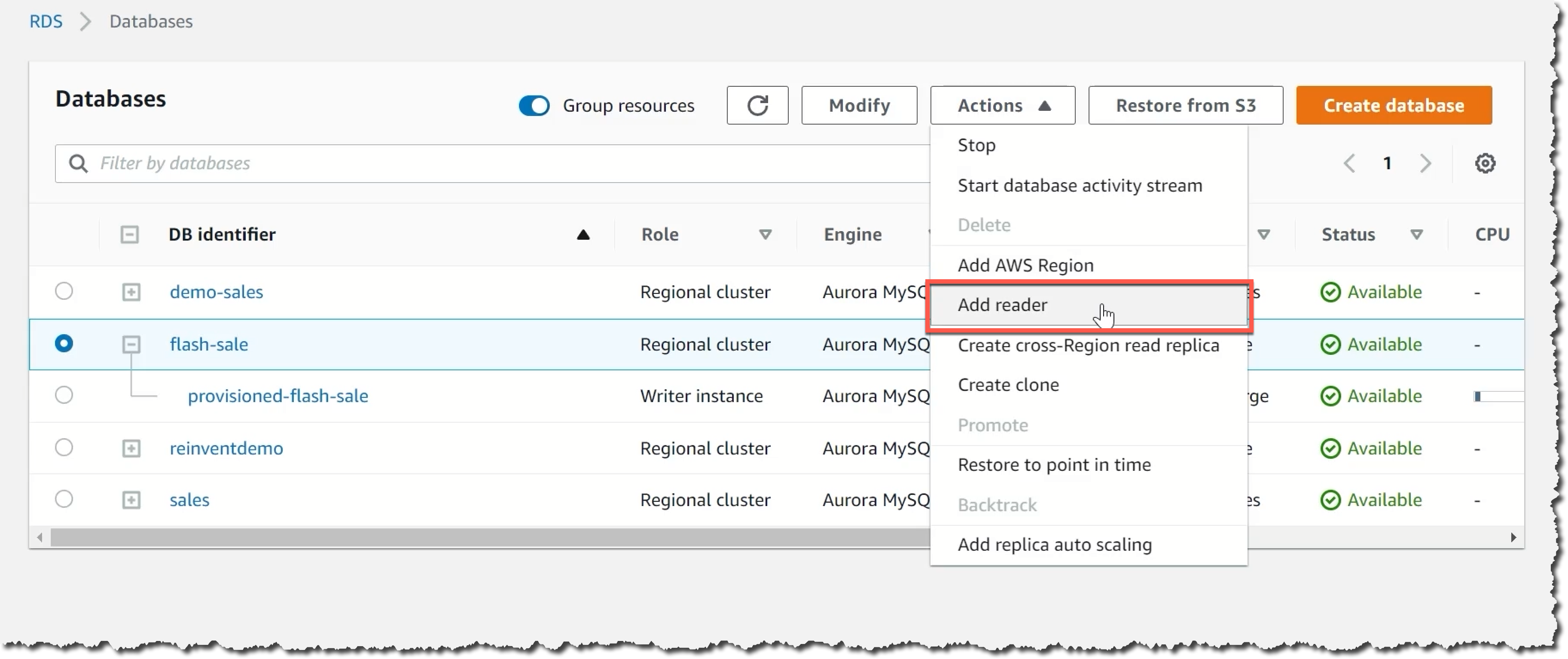
Pruebe la nueva instancia sin servidor con su carga de trabajo. Una vez que tenga la confirmación de que funciona como se esperaba, puede iniciar una conmutación por error a la instancia sin servidor, que tardará menos de 30 segundos en finalizar. Esta opción proporciona una experiencia de tiempo de inactividad mínimo para comenzar con Aurora Serverless v2.

Cómo crear una nueva base de datos de Aurora Serverless v2
Para comenzar con Aurora Serverless v2, cree una nueva base de datos desde la consola de RDS. El primer paso es elegir el tipo de motor: Amazona Aurora. Luego, elija con qué motor de base de datos desea que sea compatible: MySQL o PostgreSQL. Abra los filtros en Versión del motor y seleccione el filtro Mostrar versiones compatibles con Serverless v2. Entonces, ves que el Versiones disponibles La lista desplegable solo muestra las opciones compatibles con Aurora Serverless v2.

A continuación, debe configurar la base de datos. Especifique la configuración de credenciales con un nombre de usuario y una contraseña para el administrador de la base de datos.

Luego, configure la instancia para la base de datos. Debe seleccionar qué tipo de clase de instancia desea. Esto asigna la capacidad computacional, de red y de memoria para la instancia de la base de datos. Seleccione sin servidor.
Luego, debe definir el rango de capacidad. La capacidad de Aurora Serverless v2 aumenta y disminuye dentro de la configuración mínima y máxima. Aquí puede especificar la capacidad mínima y máxima de la base de datos para su carga de trabajo. La capacidad mínima que puede especificar es de 0,5 ACU y la máxima es de 128 ACU. Para obtener más información sobre las unidades de capacidad de Aurora Serverless v2, consulte la Documentación de escalado automático instantáneo.

A continuación, configure la conectividad creando una nueva VPC y un grupo de seguridad o use el valor predeterminado. Finalmente, seleccione Crear base de datos.

La creación de la base de datos lleva un par de minutos. Sabe que su base de datos está lista cuando el estado cambia a Disponible.
Encontrará los detalles de conexión para la base de datos en la página de la base de datos. El punto final y el puerto, combinados con el nombre de usuario y la contraseña del administrador, es todo lo que necesita para conectarse a su nueva base de datos de Aurora Serverless v2.

¡Disponible ahora!
Aurora Serverless v2 ya está disponible en EE. UU. Este (Ohio), EE. UU. Este (Norte de Virginia), EE. UU. Oeste (Norte de California), EE. UU. Oeste (Oregón), Asia Pacífico (Hong Kong), Asia Pacífico (Mumbai), Asia Pacífico (Seúl), Asia Pacífico (Singapur), Asia Pacífico (Sídney), Asia Pacífico (Tokio), Canadá (Central), Europa (Fráncfort), Europa (Irlanda), Europa (Londres), Europa (París), Europa (Estocolmo ), y América del Sur (São Paulo).
Visite la página de Amazon Aurora Serverless v2 para obtener más información sobre este lanzamiento.
– Marcia

