
|
|
Me complace anunciar Amazon S3 Files, un nuevo sistema de archivos que conecta perfectamente cualquier recurso informático de AWS con Amazon Simple Storage Service (Amazon S3).
Hace más de una década, como formador de AWS, dediqué innumerables horas a explicar las diferencias fundamentales entre el almacenamiento de objetos y los sistemas de archivos. Mi analogía favorita fue comparar objetos S3 con libros en una biblioteca (no puedes editar una página, necesitas reemplazar todo el libro) versus archivos en tu computadora que puedes modificar página por página. Dibujé diagramas, creé metáforas y ayudé a los clientes a comprender por qué necesitaban diferentes tipos de almacenamiento para diferentes cargas de trabajo. Bueno, hoy esa distinción se vuelve un poco más flexible.
Con S3 Files, Amazon S3 es el primer y único almacén de objetos en la nube que ofrece acceso a sus datos a un sistema de archivos de alto rendimiento y con todas las funciones. Hace que sus depósitos sean accesibles como sistemas de archivos. Esto significa que los cambios en los datos del sistema de archivos se reflejan automáticamente en el depósito de S3 y usted tiene un control detallado sobre la sincronización. Los archivos S3 se pueden adjuntar a múltiples recursos informáticos, lo que permite compartir datos entre clústeres sin duplicación.
Hasta ahora, había que elegir entre el costo, la durabilidad y los servicios de Amazon S3 que pueden consumir datos de forma nativa o las capacidades interactivas de un sistema de archivos. S3 Files elimina esa compensación. S3 se convierte en el centro de todos los datos de su organización. Se puede acceder a él directamente desde cualquier instancia informática, contenedor o función de AWS, ya sea que esté ejecutando aplicaciones de producción, entrenando modelos de aprendizaje automático o creando sistemas de IA agentes.
Puede acceder a cualquier depósito de uso general como sistema de archivos nativo en sus instancias de Amazon Elastic Compute Cloud (Amazon EC2), contenedores que se ejecutan en Amazon Elastic Container Service (Amazon ECS) o Amazon Elastic Kubernetes Service (Amazon EKS), o funciones de AWS Lambda. El sistema de archivos presenta objetos S3 como archivos y directorios, admitiendo todos Sistema de archivos de red (NFS) v4.1+ operaciones como crear, leer, actualizar y eliminar archivos.
A medida que trabaja con archivos y directorios específicos a través del sistema de archivos, los metadatos y contenidos de los archivos asociados se colocan en el almacenamiento de alto rendimiento del sistema de archivos. De forma predeterminada, los archivos que se benefician del acceso de baja latencia se almacenan y sirven desde el almacenamiento de alto rendimiento. Para los archivos que no están almacenados en un almacenamiento de alto rendimiento, como aquellos que necesitan lecturas secuenciales grandes, S3 Files entrega automáticamente esos archivos directamente desde Amazon S3 para maximizar el rendimiento. Para lecturas de rango de bytes, solo se transfieren los bytes solicitados, lo que minimiza el movimiento de datos y los costos.
El sistema también admite la captura previa inteligente para anticipar sus necesidades de acceso a datos. Tiene un control detallado sobre lo que se almacena en el almacenamiento de alto rendimiento del sistema de archivos. Puede decidir si desea cargar datos de archivos completos o solo metadatos, lo que significa que puede optimizarlos para sus patrones de acceso específicos.
En su interior, S3 Files utiliza Amazon Elastic File System (Amazon EFS) y ofrece latencias de ~1 ms para datos activos. El sistema de archivos admite el acceso simultáneo desde múltiples recursos informáticos con consistencia NFS casi abierta, lo que lo hace ideal para cargas de trabajo interactivas y compartidas que mutan datos, desde agentes agentes de IA que colaboran a través de herramientas basadas en archivos hasta canales de capacitación de aprendizaje automático que procesan conjuntos de datos.
Déjame mostrarte cómo empezar.
Crear mi primer sistema de archivos Amazon S3, montarlo y usarlo desde una instancia EC2 es sencillo.
Tengo una instancia EC2 y un depósito de propósito general. En esta demostración, configuro un sistema de archivos S3 y accedo al depósito desde una instancia EC2, usando comandos normales del sistema de archivos.
Para esta demostración, utilizo la Consola de administración de AWS. También puede utilizar la interfaz de línea de comandos de AWS (AWS CLI) o la infraestructura como código (IaC).
Aquí está el diagrama de arquitectura para esta demostración.
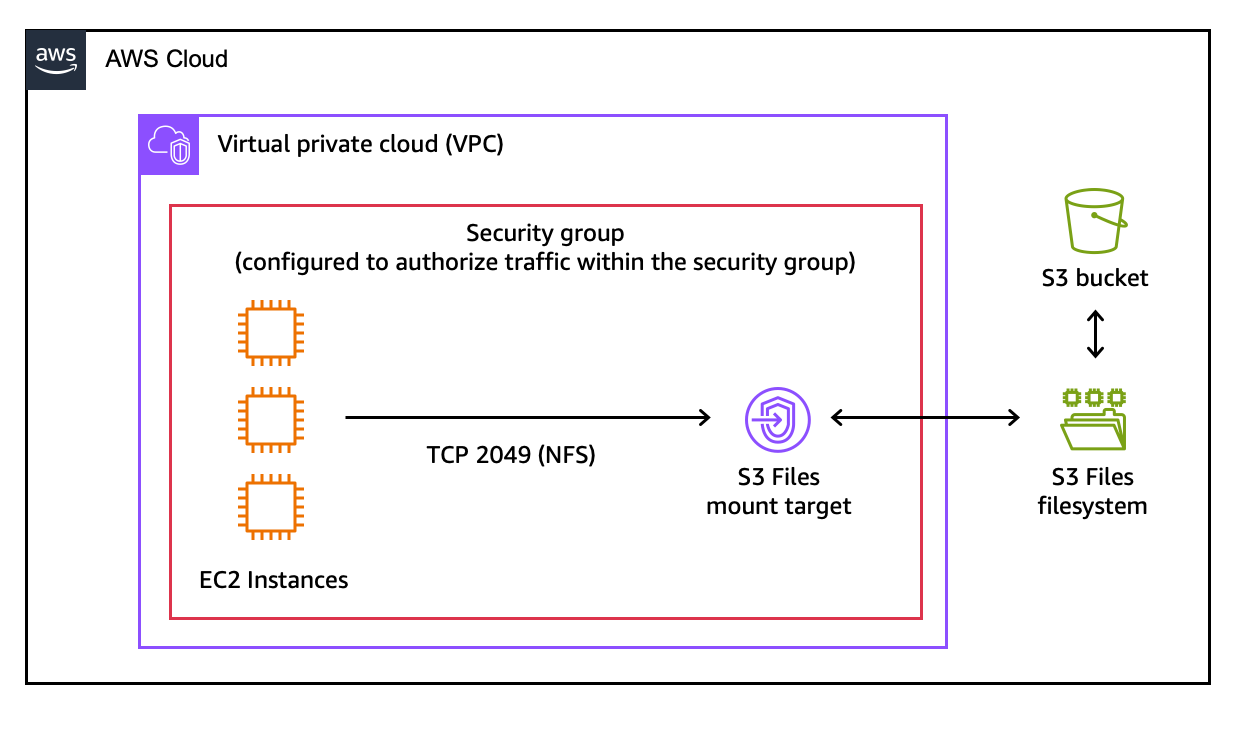 Paso 1: Cree un sistema de archivos S3.
Paso 1: Cree un sistema de archivos S3.
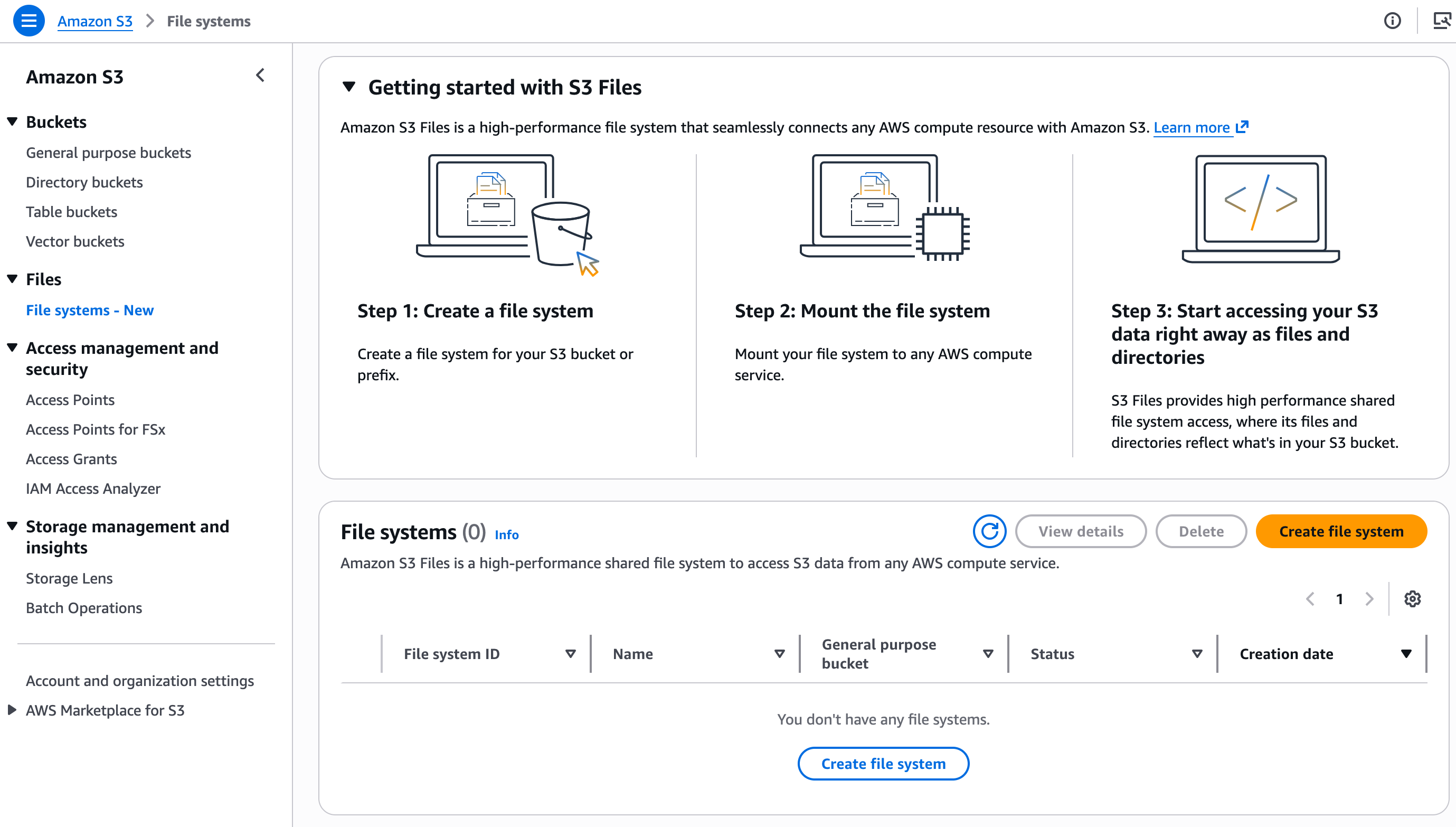
En la sección Amazon S3 de la consola, elijo Sistemas de archivos y luego Crear sistema de archivos.
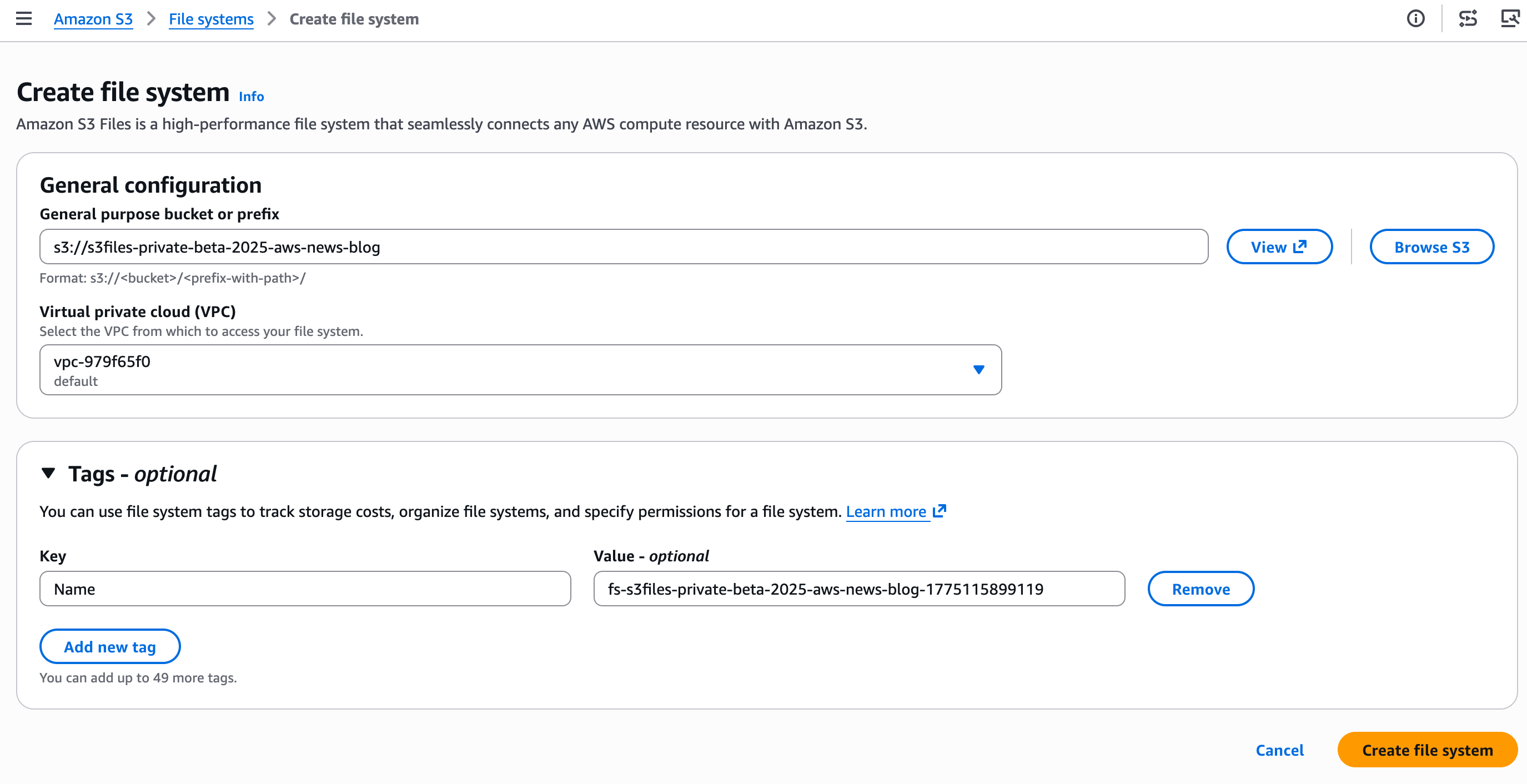
Ingreso el nombre del depósito que quiero exponer como sistema de archivos y elijo Crear sistema de archivos.
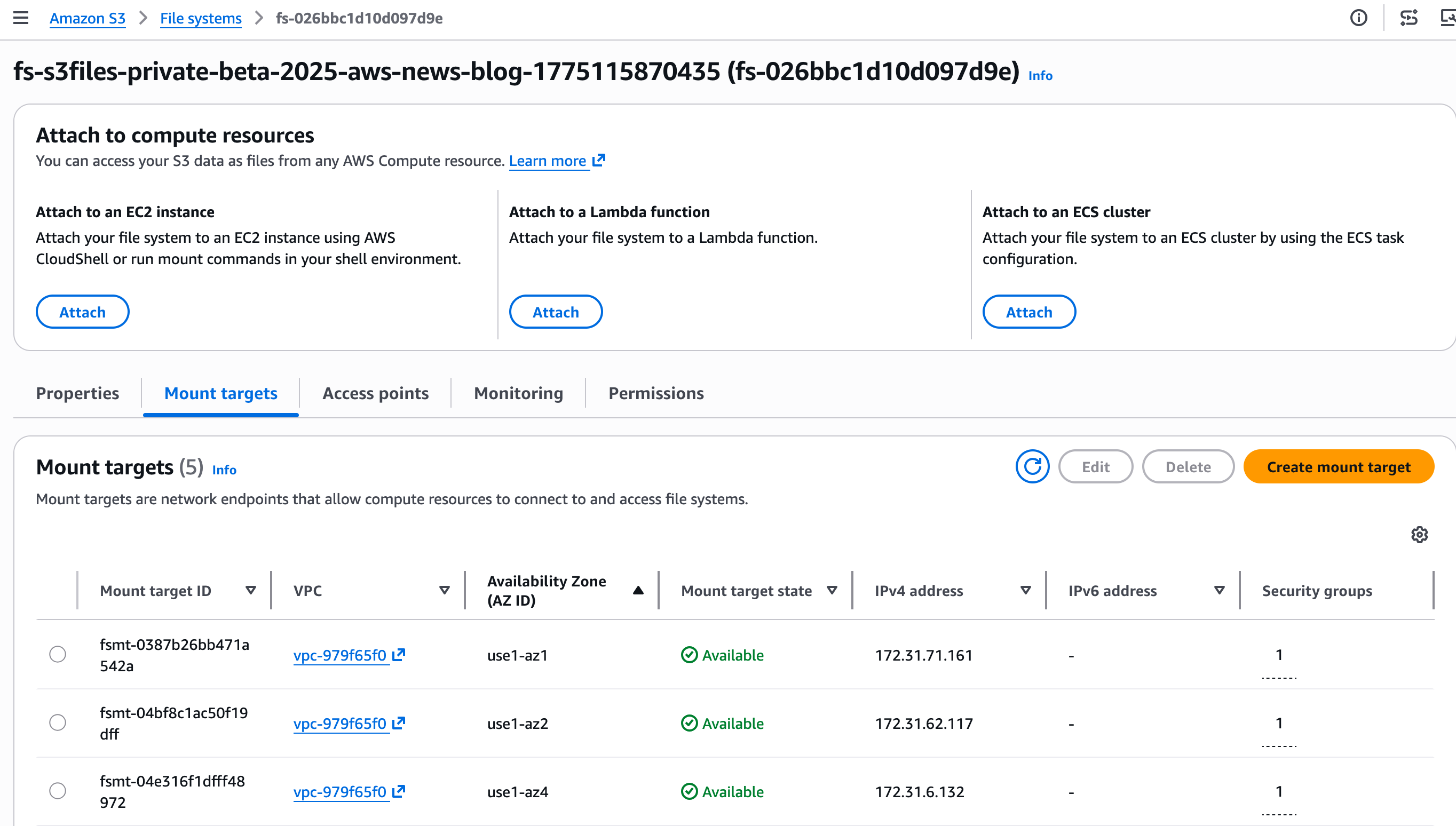
Paso 2: Descubre el objetivo de montaje.
Un objetivo de montaje es un punto final de red que residirá en mi nube privada virtual (VPC). Permite que mi instancia EC2 acceda al sistema de archivos S3.
La consola crea los destinos de montaje automáticamente. tomo notas del Montar ID de objetivoestá en el Objetivos de montaje pestaña.
Cuando se utiliza la CLI, se necesitan dos comandos separados para crear el sistema de archivos y sus destinos de montaje. Primero, creo el sistema de archivos S3 con create-file-system. Luego, creo el objetivo de montaje con create-mount-target.
Paso 3: Montar el sistema de archivos en mi instancia EC2.
Después de conectarlo a una instancia EC2, escribo:
sudo mkdir /home/ec2-user/s3files sudo mount -t s3files fs-0aa860d05df9afdfe:/ /home/ec2-user/s3files
Ahora puedo trabajar con mis datos de S3 directamente a través del sistema de archivos montado en ~/s3filesutilizando operaciones de archivos estándar.
Cuando realizo actualizaciones de mis archivos en el sistema de archivos, S3 administra y exporta automáticamente todas las actualizaciones como un nuevo objeto o una nueva versión de un objeto existente en mi depósito de S3 en cuestión de minutos.
Los cambios realizados en los objetos del depósito de S3 son visibles en el sistema de archivos en unos pocos segundos, pero a veces pueden tardar un minuto o más.
# Create a file on the EC2 file system
echo "Hello S3 Files" > s3files/hello.txt
# and verify it's here
ls -al s3files/hello.txt
-rw-r--r--. 1 ec2-user ec2-user 15 Oct 22 13:03 s3files/hello.txt
# See? the file is also on S3
aws s3 ls s3://s3files-aws-news-blog/hello.txt
2025-10-22 13:04:04 15 hello.txt
# And the content is identical!
aws s3 cp s3://s3files-aws-news-blog/hello.txt . && cat hello.txt
Hello S3 FilesCosas que debes saber
Permítanme compartir algunos detalles técnicos importantes que creo que les resultarán útiles.
Otra pregunta que escucho con frecuencia en las conversaciones con los clientes es sobre cómo elegir el servicio de archivos adecuado para sus cargas de trabajo. Sí, sé lo que estás pensando: AWS y sus servicios aparentemente superpuestos mantienen entretenidos a los arquitectos de la nube durante sus reuniones de revisión de arquitectura. Permítanme ayudar a desmitificar este.
S3 Files funciona mejor cuando necesita acceso interactivo y compartido a los datos que se encuentran en Amazon S3 a través de una interfaz de sistema de archivos de alto rendimiento. Es ideal para cargas de trabajo en las que múltiples recursos informáticos (ya sean aplicaciones de producción, agentes de IA agentes que utilizan bibliotecas Python y herramientas CLI o canales de capacitación de aprendizaje automático (ML)) necesitan leer, escribir y mutar datos de forma colaborativa. Obtiene acceso compartido entre clústeres de computación sin duplicación de datos, latencia inferior a milisegundos y sincronización automática con su depósito S3.
Para cargas de trabajo que migran desde entornos NAS locales, Amazon FSx proporciona las características familiares y la compatibilidad que necesita. Amazon FSx también es ideal para computación de alto rendimiento (HPC) y almacenamiento en clúster de GPU con Amazon FSx for Lustre. Es particularmente valioso cuando sus aplicaciones requieren capacidades específicas del sistema de archivos de Amazon FSx para NetApp ONTAP, Amazon FSx para OpenZFS o Amazon FSx para Windows File Server.
Precios y disponibilidad
S3 Files está disponible hoy en todas las regiones comerciales de AWS.
Usted paga por la porción de datos almacenados en su sistema de archivos S3, por las operaciones de lectura y escritura de archivos pequeños en el sistema de archivos, y por las solicitudes de S3 durante la sincronización de datos entre el sistema de archivos y el depósito de S3. La página de precios de Amazon S3 tiene todos los detalles.
A partir de conversaciones con clientes, creo que S3 Files ayuda a simplificar las arquitecturas de la nube al eliminar los silos de datos, la complejidad de la sincronización y el movimiento manual de datos entre objetos y archivos. Ya sea que esté ejecutando herramientas de producción que ya funcionan con sistemas de archivos, creando sistemas de inteligencia artificial agentes que se basan en bibliotecas de Python y scripts de shell basados en archivos, o preparando conjuntos de datos para el entrenamiento de aprendizaje automático, S3 Files permite que estas cargas de trabajo interactivas, compartidas y jerárquicas accedan a los datos de S3 directamente sin elegir entre la durabilidad de Amazon S3 y los beneficios de costos y las capacidades interactivas de un sistema de archivos. Ahora puede utilizar Amazon S3 como lugar para todos los datos de su organización, sabiendo que se puede acceder a los datos directamente desde cualquier instancia informática, contenedor y función de AWS.
Para obtener más información y comenzar, visite la documentación de Archivos S3.
Me encantaría saber cómo utiliza esta nueva capacidad. No dude en compartir sus comentarios en los comentarios a continuación.

