“A medida que nos adentramos en el cuarto año calendario de la Serie de blogs sobre el avance de la confiabilidad, empoderar a las organizaciones para ejecutar sus cargas de trabajo de manera confiable en Azure sigue siendo una de nuestras principales prioridades. Invertimos continuamente en la evolución de la plataforma Azure para ayudar a lograr esto todos los días. Su capacidad para monitorear la disponibilidad de máquinas virtuales (VM) de manera sólida y completa es fundamental para garantizar que sus aplicaciones estén disponibles y resistentes. Para la publicación de hoy de la serie, le pedí al Gerente del Programa, Pujitha Desirajude nuestro equipo de ingeniería de conceptos básicos de Azure Core Platform para hablar sobre las últimas mejoras de observabilidad para el monitoreo de disponibilidad de VM, así como las inversiones planificadas para brindar la mejor experiencia de monitoreo.”—Mark Russinovich, CTO, Azure
Esta publicación fue escrita por el Gerente Principal de Ingeniería de Software, Gaurav Jagtiani.
Flash, como se conoce internamente al proyecto, es una colección de esfuerzos en Azure Engineering, que tiene como objetivo hacer evolucionar el ecosistema de monitoreo de disponibilidad de máquinas virtuales (VM) de Azure en una solución centralizada, holística e inteligible en la que los clientes pueden confiar para satisfacer sus necesidades específicas de observabilidad. . Hoy, nos complace anunciar la finalización de los dos primeros hitos del proyecto: la vista previa de los datos de disponibilidad de VM en Azure Resource Graph y la vista previa privada de una métrica de disponibilidad de VM en Azure Monitor.
¿Qué es Proyecto Flash?
Project Flash deriva su nombre de nuestro compromiso de crear formas sólidas y rápidas de monitorear la disponibilidad de máquinas virtuales (VM) de la manera más completa posible, un requisito previo clave para el rendimiento eficiente de las aplicaciones. Nuestra misión es asegurarnos de que pueda:
- Consumir datos precisos y procesables sobre interrupciones en la disponibilidad de la máquina virtual (por ejemplo, reinicios y reinicios de la máquina virtual, bloqueos de aplicaciones debido a actualizaciones de controladores de red y actualizaciones del sistema operativo del host cada 30 segundos), junto con detalles precisos de la falla (por ejemplo, plataforma frente a iniciada por el usuario, reinicio frente a bloqueo, planificación versus no planificado).
- Analice y alerte sobre tendencias en la disponibilidad de VM para una depuración rápida y generación de informes mes a mes.
- Supervise periódicamente los datos a escala y cree paneles personalizados para mantenerse actualizado sobre los últimos estados de disponibilidad de todos los recursos.
- Reciba análisis automatizados de causa raíz (RCA) detallando las máquinas virtuales afectadas, la causa y la duración del tiempo de inactividad, las correcciones consiguientes y similares, todo para permitir investigaciones específicas y análisis post-mortem.
- Recibe notificaciones instantáneas sobre cambios críticos en la disponibilidad de VM para desencadenar rápidamente acciones de remediación y evitar el impacto en el usuario final.
- Personalice y automatice dinámicamente las políticas de recuperación de la plataformabasado en sensibilidades de carga de trabajo en constante cambio y necesidades de conmutación por error.
Con estos objetivos en mente, dividimos nuestra estrategia de ejecución en dos fases: una fase a corto plazo para satisfacer las necesidades críticas actuales y una fase a largo plazo para brindar la mejor experiencia de monitoreo de disponibilidad de máquinas virtuales. Este enfoque de dos fases nos ayuda a cerrar brechas continuamente, iterar sobre la calidad del servicio y aprender de sus comentarios en cada paso del camino.
Anunciando nuevas opciones de monitoreo
Para la primera fase, brindamos diferentes opciones para permitir un acceso conveniente a los datos de disponibilidad de VM para abordar una variedad de necesidades de observación. Nuestro objetivo es mantener la coherencia de los datos con estándares de calidad rigurosos similares en todas estas características y soluciones existentes, como Estado de los recursos o Registro de actividadespara ofrecer una vista coherente e independiente de la solución que elija.
Presentación del análisis a escala para la disponibilidad de máquinas virtuales
Hoy, estamos emocionados de alcanzar nuestro primer hito de Project Flash: con el lanzamiento de vista previa de los estados de disponibilidad de VM en Azure Resource Graph para el consumo programático a escala.
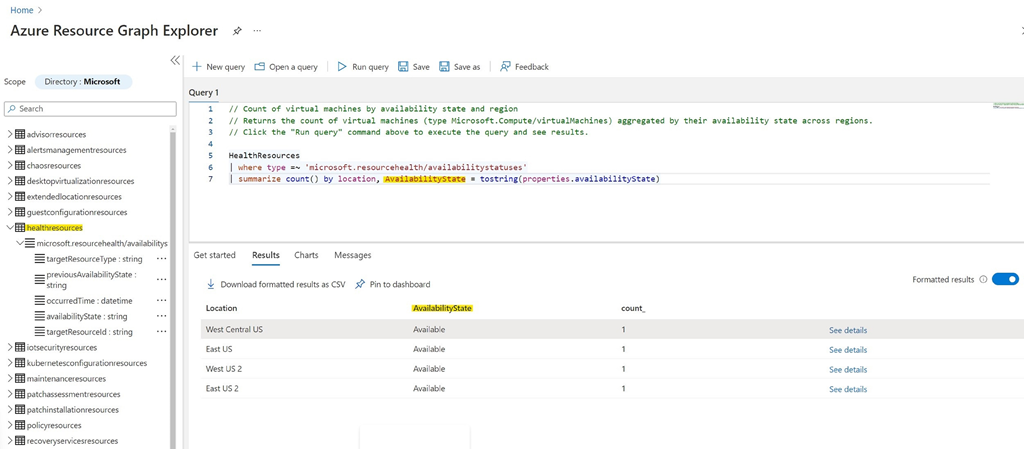
Gráfico de recursos de Azure es un servicio en Azure que se adopta ampliamente por su capacidad eficiente para realizar consultas en muchas suscripciones, todas a la vez y con latencias bajas. Actualmente estamos emitiendo Estados de disponibilidad de máquinas virtuales (Disponible, No disponible y Desconocido) a la tabla de recursos de salud en Azure Resource Graph, para que pueda realizar tareas complejas. Consultas de Kusto Query Language (KQL) para tamizar a través de grandes conjuntos de datos a la vez. Esta funcionalidad es útil para realizar un seguimiento de los cambios históricos en la disponibilidad de las máquinas virtuales, crear paneles personalizados y realizar investigaciones detalladas en numerosas propiedades de recursos repartidas en varias tablas.

Figura 1: Ventana del Explorador de Azure Resource Graph con consulta y resultados, para demostrar la obtención de datos de la tabla HealthResources.
Estamos planeando agregar detalles de fallas y escenarios de VM degradados a la tabla de recursos de salud en Azure Resource Graph, a finales de este año. Estos detalles garantizarán que esté debidamente informado sobre la causa y el impacto de cualquier falla, de modo que pueda realizar una conmutación por error, reiniciar en el lugar o tomar las medidas de mitigación adecuadas para evitar el impacto en el usuario final.
Navegar a Explorador de gráficos de recursos de Azure en Azure Portal para comenzar con cualquiera de las consultas de KQL publicado para la tabla de Recursos de Salud.
Presentación de la métrica de disponibilidad de máquinas virtuales en Azure Monitor
También nos complace anunciar la vista previa privada de una métrica de disponibilidad de máquina virtual lista para usar en Azure Monitor, para una experiencia de supervisión y alertas de métricas seleccionadas.
Métricas en Azure Monitor son excelentes para monitorear y analizar representaciones de series temporales de disponibilidad de VM para una depuración rápida y fácil, recibir alertas de alcance sobre tendencias preocupantes, detectar indicadores tempranos de disponibilidad degradada, correlacionar con otras métricas de plataforma y más.
La métrica le permite realizar un seguimiento del pulso de sus máquinas virtuales: durante el comportamiento esperado, la métrica muestra un valor de 1. En respuesta a cualquier interrupción en la disponibilidad de la máquina virtual, la métrica desciende a 0 durante la duración del impacto. En caso de una interrupción de la infraestructura de Azure, emitiremos valores nulos representados como una línea de puntos en el portal.

Figura 2: Captura de pantalla de la métrica de disponibilidad de VM como se ve en Metrics Explorer en Azure Portal, con caídas ocasionales para reflejar las interrupciones de disponibilidad de VM.
Lanzamos la vista previa privada de la métrica como la primera fase de nuestro plan de implementación y actualmente estamos recopilando comentarios de los clientes para mejorar aún más nuestra oferta. Estamos planeando agregar detalles de fallas, como dimensiones de métricas y registros de plataforma, el próximo año, para permitirle alertar con precisión sobre escenarios de fallas que tienen un impacto.
Próximamente
¡Las dos opciones de monitoreo presentadas anteriormente son solo el comienzo de Project Flash! Continuaremos construyendo sobre nuestras soluciones existentes mejorando la calidad de los datos y la atribución de fallas. Paralelamente, estamos diseñando dos nuevas ofertas de monitoreo para satisfacer sus necesidades de latencia y mitigación, al mismo tiempo que invertimos mucho en la plataforma subyacente para que nuestra detección de fallas sea más resistente y completa.
Azure Event Grid para notificaciones instantáneas
La ejecución exitosa de aplicaciones críticas para el negocio requiere un hiperconocimiento de cualquier evento que afecte la disponibilidad de la VM, por lo que las acciones de remediación pueden activarse instantáneamente para evitar el impacto en el usuario final. Para apoyarlo en sus operaciones diarias, planeamos diseñar un mecanismo de notificación que aproveche la tecnología de baja latencia de Cuadrícula de eventos de Azure. Esto le permitirá simplemente suscribirse a un Tema del sistema Event Gridy enrutar eventos de ámbito a través de controladores de eventos a cualquier herramienta aguas abajo, instantáneamente.
Automatice y adapte las políticas de recuperación de la plataforma
Teniendo en cuenta las numerosas inversiones en curso para mejorar su experiencia de monitoreo de disponibilidad de VM, Project Flash tiene la intención de empoderarlo aún más al proporcionarle perillas para personalizar las políticas de recuperación activadas por la plataforma, en respuesta a casos de interrupciones en la disponibilidad de VM.
Una de esas perillas que estamos diseñando es la capacidad de excluirse de Service Healing para máquinas virtuales de instancia única, en respuesta a un conjunto específico de interrupciones de disponibilidad imprevistas. Esta perilla estará disponible a través del portal o en el momento de la implementación de la VM y se puede actualizar dinámicamente. Tenga en cuenta que aprovechar esta característica hará que los acuerdos de nivel de servicio de disponibilidad habituales de Azure Virtual Machine sean ineficaces.
En el futuro, exploraremos la introducción de perillas para optar por no participar en otras políticas de recuperación aplicables (por ejemplo, Migración en vivo o Tardigrade), para garantizar que pueda adaptarse fácilmente a sus necesidades de mitigación en constante cambio.
Inversiones continuas en calidad de la plataforma
Si bien la primera fase está diseñada para satisfacer sus necesidades actuales de observabilidad, seguimos enfocados en nuestro objetivo a largo plazo de brindar una experiencia de observabilidad de clase mundial en torno a la disponibilidad de máquinas virtuales. Estamos muy emocionados por todo el enriquecimiento de datos y los avances tecnológicos que contribuirán a esta experiencia, así que aquí hay un vistazo preliminar a nuestra hoja de ruta de inversiones planificadas:
- Detección y atribución de fallas: Evolucionamos continuamente nuestra infraestructura subyacente para detectar y atribuir fallas de manera precisa e instantánea, de modo que podamos reducir los informes de estado de salud desconocidos o faltantes, emitir detalles de falla procesables y manejar las personalizaciones de recuperación de la plataforma. Esta sigue siendo nuestra principal área de inversión en la que continuamos iterando cada ciclo.
- Automatización del análisis de causa raíz (RCA): Estamos planeando implementar mecanismos de seguimiento sencillos para cada tiempo de inactividad de máquina virtual único, junto con la construcción y emisión automáticas de declaraciones RCA detalladas de tiempo de inactividad para reducir el seguimiento manual y la rotación de su parte.
- Integración AIOps: Buscamos aprovechar los tremendos avances que se están realizando en AIOps en todo Microsoft, para permitir conocimientos inteligentes y detección y diagnóstico de anomalías en la multitud de puntos de datos sobre la disponibilidad de VM.
- Experiencia de usuario centralizada y cohesiva: Reconocemos que una consecuencia de nuestro enfoque a corto plazo es que en nuestros diferentes servicios tenemos múltiples herramientas de monitoreo, alerta y recuperación que pueden generarle una experiencia confusa y dispar. Este es un problema que pretendemos resolver con nuestra fase final. Nuestro objetivo principal es proporcionar a los usuarios finales acceso a representaciones distintas y necesarias de la disponibilidad de máquinas virtuales, consolidadas dentro de Azure Monitor y clasificadas según patrones de uso comunes para la detección, la facilidad de uso y la incorporación intuitiva.
Aprende más
Esta lista ciertamente no es exhaustiva, ya que tenemos planeados múltiples enriquecimientos como parte de nuestra estrategia a largo plazo. Para reiterar, nuestra intención con Project Flash es hacer que el monitoreo de la disponibilidad de las máquinas virtuales sea extremadamente intuitivo, completo y fluido, para que siempre esté preparado e informado sobre cualquier cambio en el estado de sus cargas de trabajo, en última instancia, para mantener sus propios SLA y promesas comerciales.
Continuaremos compartiendo actualizaciones sobre Project Flash a través de blogs como este, para garantizar que se mantenga actualizado sobre las últimas novedades. ¡Manténganse al tanto!

