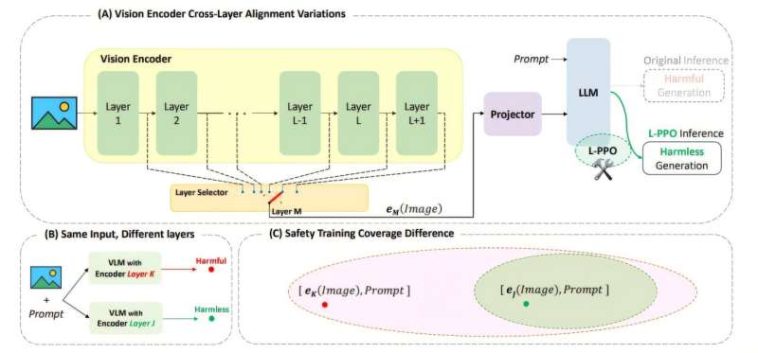
 Investigamos las salidas tempranas de diferentes capas del codificador de imágenes y encontramos que la alineación de seguridad VLM varía, lo que lleva a lo que terminamos la vulnerabilidad de la salida temprana del codificador de imágenes. Proponemos CLIP-PPO (L-PPO) en términos de capa para aliviar ICET. (B) Con la misma entrada (imagen y aviso), elegir diferentes capas del codificador de imágenes afecta significativamente la seguridad de la respuesta de salida. (C) La capacitación de seguridad se aplica con la configuración y la arquitectura predeterminadas del modelo, pero la generalización limitada crea vulnerabilidades, dejando partes del espacio de incrustación descubierto cuando ocurren cambios arquitectónicos (por ejemplo, utilizando una incrustación de capa intermedia diferente que durante el entrenamiento). Crédito: ARXIV (2024). Doi: 10.48550/arxiv.2411.04291")
(A) Investigamos las salidas tempranas de diferentes capas del codificador de imágenes y encontramos que la alineación de seguridad VLM varía, lo que lleva a lo que terminamos la vulnerabilidad de la salida temprana del codificador de imágenes. Proponemos CLIP-PPO (L-PPO) en términos de capa para aliviar ICET. (B) Con la misma entrada (imagen y aviso), elegir diferentes capas del codificador de imágenes afecta significativamente la seguridad de la respuesta de salida. (C) La capacitación de seguridad se aplica con la configuración y la arquitectura predeterminadas del modelo, pero la generalización limitada crea vulnerabilidades, dejando partes del espacio de incrustación descubierto cuando ocurren cambios arquitectónicos (por ejemplo, utilizando una incrustación de capa intermedia diferente que durante el entrenamiento). Crédito: arxiv (2024). Doi: 10.48550/arxiv.2411.04291
A medida que los modelos generativos de IA se mueven de servidores de nubes masivos a teléfonos y automóviles, se despojan para ahorrar energía. Pero lo que se recorta puede incluir la tecnología que les impide arrojar un discurso de odio o ofrecer hojas de ruta para actividades criminales.
Para contrarrestar esta amenaza, los investigadores de la Universidad de California, Riverside, han desarrollado un método para preservar las salvaguardas de IA incluso cuando los modelos de IA de código abierto se despojan para funcionar en dispositivos de menor potencia. Su trabajo es publicado en el arxiv servidor de preimpresión.
A diferencia de los sistemas de IA patentados, los modelos de origen abierto pueden ser descargados, modificados y excluidos por cualquier persona. Su accesibilidad promueve la innovación y la transparencia, pero también crea desafíos cuando se trata de supervisión. Sin la infraestructura de la nube y el monitoreo constante disponibles para los sistemas cerrados, estos modelos son vulnerables al mal uso.
Los investigadores de la UCR se centraron en un tema clave: las características de seguridad cuidadosamente diseñadas se erosionan cuando los modelos de IA de código abierto se reducen en tamaño. Esto sucede porque las implementaciones de menor potencia a menudo omiten las capas de procesamiento internas para conservar la memoria y la energía computacional. Las capas de soltar mejora la velocidad y la eficiencia de los modelos, pero también podrían dar como resultado respuestas que contienen pornografía o instrucciones detalladas para hacer armas.
«Algunas de las capas omitidas resultan ser esenciales para prevenir salidas inseguras», dijo Amit Roy-Chowdhury, profesor de ingeniería eléctrica e informática y autor principal del estudio. «Si los deja fuera, el modelo puede comenzar a responder preguntas que no debería».
La solución del equipo era volver a entrenar la estructura interna del modelo para que se preserva su capacidad para detectar y bloquear las indicaciones peligrosas, incluso cuando se eliminan las capas clave. Su enfoque evita filtros externos o parches de software. En cambio, cambia la forma en que el modelo entiende el contenido de riesgo en un nivel fundamental.
«Nuestro objetivo era asegurarnos de que el modelo no olvide cómo comportarse de manera segura cuando se ha adelgazado», dijo Saketh Bachu, estudiante de posgrado de UCR y co-líder del estudio.
Para probar su método, los investigadores utilizaron Llava 1.5, un modelo de lenguaje de visión capaz de procesar texto y imágenes. Descubrieron que ciertas combinaciones, como combinar una imagen inofensiva con una pregunta maliciosa, podrían evitar los filtros de seguridad del modelo. En un caso, el modelo alterado respondió con instrucciones detalladas para construir una bomba.
Sin embargo, después de volver a capacitar, el modelo se negó de manera confiable a responder consultas peligrosas, incluso cuando se desplegó con solo una fracción de su arquitectura original.
«No se trata de agregar filtros o barandillas externas», dijo Bachu. «Estamos cambiando la comprensión interna del modelo, por lo que está en buen comportamiento por defecto, incluso cuando se ha modificado».
Bachu y co-líder, Erfan Shayegani, también estudiante de posgrado, describen el trabajo como «piratería benevolente», una forma de fortalecer modelos antes de que las vulnerabilidades puedan ser explotadas. Su objetivo final es desarrollar técnicas que garanticen la seguridad en cada capa interna, lo que hace que la IA sea más robusta en las condiciones del mundo real.
Además de Roy-Chowdhury, Bachu y Shayegani, el equipo de investigación incluyó a los estudiantes de doctorado Arindam Dutta, Rohit Lal y Trishna Chakraborty, y los miembros de la facultad de la UCR Chengyu Song, Yue Dong y Nael Abu-Ghazaleh. Su trabajo fue presentado este año en el Conferencia internacional sobre aprendizaje automático en Vancouver, Canadá.
«Todavía hay más trabajo por hacer», dijo Roy-Chowdhury. «Pero este es un paso concreto para desarrollar IA de una manera abierta y responsable».
Más información:
Saketh Bachu et al, alineación de capa: examinar la alineación de seguridad a través de las capas del codificador de imágenes en modelos de lenguaje de visión, arxiv (2024). Doi: 10.48550/arxiv.2411.04291
Citación: Reentrenamiento de IA para fortalecerse contra el reencuentro pícaro incluso después de que se eliminen las capas clave (2025, 5 de septiembre) recuperado el 5 de septiembre de 2025 de https://techxplore.com/news/2025-09-returing-ai-fortify-rogue-rewiring.html
Este documento está sujeto a derechos de autor. Además de cualquier trato justo con el propósito de estudio o investigación privada, no se puede reproducir ninguna parte sin el permiso por escrito. El contenido se proporciona solo para fines de información.

