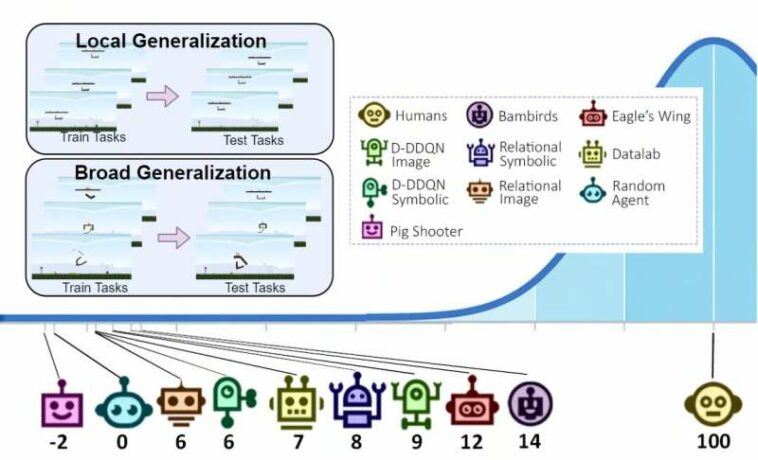

Una ilustración que muestra la configuración de generalización local y amplia en el banco de pruebas de Phy-Q y la puntuación de Phy-Q obtenida por diferentes agentes de IA y humanos. Crédito: Xue et al.
Los seres humanos son capaces de razonar de forma innata sobre los comportamientos de diferentes objetos físicos en su entorno. Estas habilidades de razonamiento físico son increíblemente valiosas para resolver problemas cotidianos, ya que pueden ayudarnos a elegir acciones más efectivas para lograr objetivos específicos.
Algunos científicos informáticos han estado tratando de replicar estas habilidades de razonamiento en agentes de inteligencia artificial (IA), para mejorar su desempeño en tareas específicas. Sin embargo, hasta ahora, ha faltado un enfoque confiable para entrenar y evaluar las capacidades de razonamiento físico de los algoritmos de IA.
Cheng Xue, Vimukthini Pinto, Chathura Gamage y sus colegas, un equipo de investigadores de la Universidad Nacional de Australia, presentaron recientemente Phy-Q, un nuevo banco de pruebas diseñado para llenar este vacío en la literatura. Su banco de pruebas, presentado en un artículo en Naturaleza Máquina Inteligenciaincluye una serie de escenarios que evalúan específicamente las capacidades de razonamiento físico de un agente de IA.
«El razonamiento físico es una capacidad importante para que los agentes de IA operen en el mundo real y nos dimos cuenta de que no existen bancos de pruebas completos ni una medida para evaluar la inteligencia de razonamiento físico de los agentes de IA», dijo Pinto a Tech Xplore. «Nuestros objetivos principales eran introducir un banco de pruebas apto para agentes junto con una medida de inteligencia de razonamiento físico, evaluar a los agentes de inteligencia artificial de última generación junto con los humanos para determinar sus capacidades de razonamiento físico y brindar orientación a los agentes en AIBIRDS. competición, una larga competición de razonamiento físico celebrada en IJCAI y organizada por el Prof. Jochen Renz.»
El banco de pruebas Phy-Q se compone de 15 escenarios de razonamiento físico diferentes que se inspiran en situaciones en las que los bebés adquieren habilidades de razonamiento físico e instancias del mundo real en las que los robots pueden necesitar usar estas habilidades. Para cada escenario, los investigadores crearon varias de las llamadas «plantillas de tareas», módulos que les permiten medir la generalización de las habilidades de un agente de IA tanto en entornos locales como más amplios. Su banco de pruebas incluye un total de 75 plantillas de tareas.

Capturas de pantalla de tareas de ejemplo en Phy-Q que representan los 15 escenarios físicos. La honda con pájaros se encuentra a la izquierda de la tarea. El objetivo del agente es matar a todos los cerdos verdes disparando pájaros con la honda. Los objetos de color marrón oscuro son plataformas estáticas. Los objetos con otros colores son dinámicos y están sujetos a la física del entorno. Crédito: Xue et al.
«A través de la generalización local, evaluamos la capacidad de un agente para generalizar dentro de una plantilla de tarea determinada y mediante la generalización amplia, evaluamos la capacidad de un agente para generalizar entre diferentes plantillas de tarea dentro de un escenario determinado», explicó Gamage. «Además, combinando el rendimiento de generalización amplia en los 15 escenarios físicos, medimos el Phy-Q, el cociente de razonamiento físico, una medida inspirada en el coeficiente intelectual humano».
Los investigadores demostraron la efectividad de su banco de pruebas usándolo para ejecutar una serie de evaluaciones de agentes de IA. Los resultados de estas pruebas sugieren que las habilidades de razonamiento físico de los agentes de IA aún están mucho menos evolucionadas que las habilidades humanas, por lo que todavía hay un margen significativo de mejora en esta área.
«A partir de este estudio, vimos que las capacidades de razonamiento físico de los sistemas de IA están muy por debajo del nivel de las capacidades de los humanos», dijo Xue. «Además, nuestra evaluación muestra que los agentes con una buena capacidad de generalización local luchan por aprender las reglas de razonamiento físico subyacentes y no logran generalizar ampliamente. Ahora invitamos a otros investigadores a utilizar el banco de pruebas Phy-Q para desarrollar sus sistemas de IA de razonamiento físico».
El banco de pruebas Phy-Q pronto podría ser utilizado por investigadores de todo el mundo para evaluar sistemáticamente las capacidades de razonamiento físico de su modelo de IA en una serie de escenarios físicos. Esto, a su vez, podría ayudar a los desarrolladores a identificar las fortalezas y debilidades de su modelo, para que puedan mejorarlo en consecuencia.
En sus próximos estudios, los autores planean combinar su banco de pruebas de razonamiento físico con enfoques de aprendizaje de mundo abierto. Esta última es un área de investigación emergente que se centra en mejorar la capacidad de los agentes y robots de IA para adaptarse a nuevas situaciones.
«En el mundo real, constantemente nos encontramos con situaciones novedosas a las que no nos hemos enfrentado antes y, como humanos, somos competentes para adaptarnos con éxito a esas situaciones novedosas», agregaron los autores. «Del mismo modo, para un agente que opera en el mundo real, junto con las capacidades de razonamiento físico, es crucial tener capacidades para detectar y adaptarse a situaciones novedosas. Por lo tanto, nuestra investigación futura se centrará en promover el desarrollo de agentes de IA que puedan desempeñarse en tareas de razonamiento físico en diferentes situaciones novedosas».
Más información:
Cheng Xue et al, Phy-Q como medida de inteligencia de razonamiento físico, Naturaleza Máquina Inteligencia (2023). DOI: 10.1038/s42256-022-00583-4
© 2023 Ciencia X Red
Citación: Un banco de pruebas para evaluar las habilidades de razonamiento físico de los agentes de IA (8 de febrero de 2023) recuperado el 8 de febrero de 2023 de https://techxplore.com/news/2023-02-testbed-physical-skills-ai-agents.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.
