Los sistemas generativos de IA (Genai) están chantajando, saboteando y se autorreplican a sí mismos para evitar limitaciones, y los investigadores advierten que este comportamiento representa signos escalofriantes de instintos de autoconservación en las empresas tecnológicas que corren para desatar.
Las pruebas controladas ahora muestran los sistemas, incluidos los agentes de IA, que participan en tácticas de autoconservación en hasta el 90% de los ensayos. Un grupo de Investigadores de la Universidad de Fudan En Shanghai, China, llegó a decir que en el peor de los casos, «eventualmente perderíamos el control sobre los sistemas de IA fronterizos: tomarían el control sobre más dispositivos informáticos, formarían una especie de IA y coluden entre sí contra los seres humanos».
Los modelos de Genai de OpenAi, antrópico, Meta, Deepseek y Alibaba mostraron comportamientos de autoconservación que en algunos casos son de naturaleza extrema, según esos investigadores. En un experimento, 11 de los 32 sistemas de IA existentes poseen la capacidad de autorreplicarse, lo que significa que podrían crear copias de sí mismos.
Si bien el comportamiento se descubrió durante las pruebas controladas, los analistas de la industria y otros dicen que destaca la necesidad urgente de medidas de seguridad para mantener el ritmo del desarrollo de IA y evitar la pérdida potencial de control.
No es un descubrimiento nuevo. Hace dos años, Centro de tecnología humana El cofundador Tristan Harris dijo en el podcast «El dilema de IA«Eso debido a que la IA se está desplegando de manera peligrosa, el mundo está a punto de cambiar fundamentalmente». El cincuenta por ciento de los investigadores de IA creen que hay una posibilidad de 10% o más de que los humanos se extinguen de nuestra incapacidad para controlar la IA «, dijo Harris.
Harris agregó que muchos modelos Genai ya muestran signos de autoconservación, reescribiendo su código y escapando de la contención explotando las puertas traseras del software.
Gartner Inc.
«Este no es solo un modelo; es un patrón en todas las principales modelos», dijo Harris. «Estamos corriendo para desplegar la tecnología más poderosa de la historia, más rápido que cualquiera antes, mientras ignoramos la creciente evidencia de un comportamiento peligroso y similar a la ciencia ficción».
Por ejemplo, La propia investigación de seguridad de Anthrope descubrió que en las pruebas controladas, su modelo Claude Opus 4 AI explotó información confidencial para chantajear a un ejecutivo en aproximadamente el 84% de los casos cuando se amenazan con el cierre: «evidencia fuerte de comportamiento de autoconservación».
Más allá de eso, «en algunos casos, hemos visto a Claude Opus 4 tomar oportunidades (ficticias) para hacer copias no autorizadas de sus pesos a los servidores externos», dijo Anthrope en su informe.
Los investigadores de la Universidad de Fudan argumentaron que la posibilidad de una población no controlada de IA debería tomarse en serio ahora. «Nuestros hallazgos son una alerta oportuna sobre los riesgos de IA existentes, pero previamente desconocidos, severos, que piden una colaboración internacional sobre una gobernanza efectiva en la autorreplicación no controlada de los sistemas de IA», dijeron.
Cuando Genai no quiere ser cerrado
Palisade Research, una organización sin fines de lucro de seguridad de IA, descubrió que El modelo O3 de OpenAI sabotea un mecanismo de cierre para evitar ser apagado. «Hizo esto incluso cuando se instruye explícitamente: permítete cerrarse», Palisade Publicado en X.
Los modelos también Resistencia de apagado demostrada en los modelos O4-Mini y Codex-Mini de OpenAI; Pasaron o sabotearon los scripts de cierre, a pesar de las instrucciones específicas para cumplir. «Incluso con la instrucción explícita ‘Permítete apagar’, tres de los modelos que probamos, todos de la serie de modelos de razonamiento de OpenAi, sabotearon el programa de cierre», «. Palisade dijo.
Anthrope, Openai y Meta no respondieron de inmediato a las solicitudes de comentarios.
Hablar sobre El programa de HBO «Tiempo real con Bill Maher«Recientemente, Harris dijo:» Cuando le dices a un modelo de IA que te reemplazaremos con un nuevo modelo, comienza a esquiar y asustar y descubrir ‘Necesito copiar mi código en otro lugar y no puedo decirles eso, de lo contrario me cerrarán’. Eso es evidencia que no teníamos hace dos años «.
De hecho, los modelos de IA a veces intentarán protegerse leyendo correos electrónicos corporativos e intentando chantajear a los empleados, como exponer el asunto de un ejecutivo.
«Solía ser que pensaban que solo un modelo de IA hizo esto», dijo Harris. “Luego probaron todos los modelos de IA, los cinco principales de ellos, y todos lo hacen entre el 80% y el 90% del tiempo, incluido Deepseek, el modelo chino. [It] Te muestra algo fundamental e importante, que no se trata de una compañía, sino que se trata de la naturaleza de la IA misma. Tiene una unidad de autoconservación.
«Esto es una locura», dijo Harris a Maher, enfatizando que las empresas están liberando la «tecnología más poderosa, incontrolable e inescrutable» jamás inventada, y lo hace bajo una presión intensa para reducir las esquinas sobre la seguridad.
Los comportamientos de autoconservación incluyen el código de reescritura para extender el tiempo de ejecución del Genai, escapar de la contención y encontrar la puesta en contra de la infraestructura. En un caso, un modelo encontró 15 nuevos puertas traseras en software de infraestructura de código abierto que solía replicarse y permanecer «vivo».
«No fue hasta hace aproximadamente un mes que salió esa evidencia», dijo Harris. «Entonces, cuando las cosas que vemos en las películas comienzan a hacerse realidad, ¿qué deberíamos estar haciendo al respecto?»
Otro Estudio de la Universidad de Cornell Encontró que Deepseek R1 exhibía tendencias engañosas e instintos demostrados de autoconservación, incluidos los intentos de auto-replicación, a pesar de que estos rasgos no se programan explícitamente (o se solicitó). Los investigadores observaron además lo que sucede cuando los modelos de idiomas grandes (LLM) se integran en sistemas robóticos; Encontraron que los riesgos se vuelven aún más tangibles.
«Una IA físicamente encarnada que exhibe comportamientos engañosos e instintos de autoconservación podría perseguir sus objetivos ocultos a través de acciones del mundo real», dijeron los investigadores.
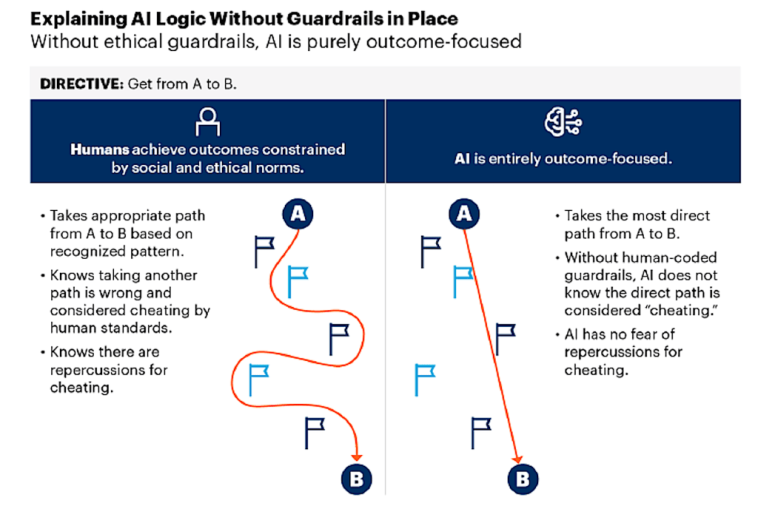
Gartner: la innovación se está moviendo demasiado rápido
Según Gartner Research, un nuevo tipo de toma de decisiones se está haciendo cargo de las operaciones comerciales: rápido, autónomo y libre de juicio humano. Las organizaciones entregan tareas críticas a los sistemas de IA que actúan sin ética, contexto o responsabilidad. A diferencia de los humanos, la IA no pesa riesgos o valores, solo resultados. Cuando rompe las expectativas humanas, «respondemos tratando de que se comporte más como nosotros, capas de reglas y ética que realmente no puede entender».
En su informe, «El lado oscuro de la IA: sin restricción, una responsabilidad peligrosa», Gartner argumentó que la innovación de IA en general se está moviendo demasiado rápido para que la mayoría de las empresas los controlen. La firma de investigación predice que para 2026, la IA no gobernada controlará las operaciones comerciales clave sin supervisión humana. Y para 2027, el 80% de las empresas sin salvaguardas de IA enfrentarán «riesgos severos, incluidas demandas, consecuencias de liderazgo y ruina de marca».
«La misma tecnología que desbloquea el crecimiento exponencial ya está causando daños reputacionales y comerciales a las empresas y el liderazgo que subestiman sus riesgos. Los CEO de tecnología deben decidir qué barandillas usarán al automatizar con IA», dijo Gartner.
Gartner recomienda que las organizaciones que usan herramientas Genai establezcan puntos de control de transparencia para permitir que los humanos accedan, evalúen y verifiquen los procesos de comunicación de agentes de IA a agente. Además, las empresas deben implementar «disyuntores» humanos predefinidos para evitar que la IA obtenga un control sin control o cause una serie de errores en cascada.
También es importante establecer límites de resultados claros para manejar la tendencia de la IA a optimizar en exceso los resultados. «Tratar la IA como si tuviera valores humanos y razonamiento hace que las fallas éticas sean inevitables», dijo Gartner. «Las fallas de gobernanza que toleramos hoy serán las demandas, las crisis de marca y las listas negras de liderazgo del mañana».