
PV2DOC organiza datos de audio y visuales de videos de presentación en documentos PDF estructurados, lo que hace que el contenido sea más fácil de entender y acceder. Crédito: Profesor asociado Hyuk-Yoon Kwon de la Universidad Nacional de Ciencia y Tecnología de Seúl
Probablemente haya encontrado videos de estilo presentación que combinan diapositivas, figuras, tablas y explicaciones habladas. Estos videos se han convertido en un medio ampliamente utilizado para transmitir información, particularmente después de la pandemia de COVID-19, cuando se implementaron medidas de confinamiento en casa.
Si bien los videos son una forma atractiva de acceder al contenido, un inconveniente importante es que consumen mucho tiempo, ya que es necesario mirar el video completo para encontrar información específica. También ocupan un espacio de almacenamiento considerable debido al gran tamaño de los archivos.
Los investigadores dirigidos por el profesor Hyuk-Yoon Kwon de la Universidad Nacional de Ciencia y Tecnología de Seúl (Corea del Sur) intentaron abordar estos problemas con PV2DOC, una herramienta de software que convierte vídeos de presentaciones en documentos resumidos. A diferencia de otros resúmenes de video, que requieren una transcripción junto con el video y se vuelven ineficaces cuando solo el video está disponible, PV2DOC supera esta limitación combinando datos visuales y de audio y convirtiendo videos en documentos.
Su investigación estuvo disponible en línea el 11 de octubre de 2024 y fue publicado en el diario SoftwareX el 1 de diciembre de 2024.
«Para los usuarios que necesitan ver y estudiar numerosos vídeos, como conferencias o presentaciones de conferencias, PV2DOC genera informes resumidos que se pueden leer en dos minutos. Además, PV2DOC gestiona figuras y tablas por separado, conectándolas con el contenido resumido para que los usuarios puedan consultar cuando sea necesario», explica el profesor Kwon.
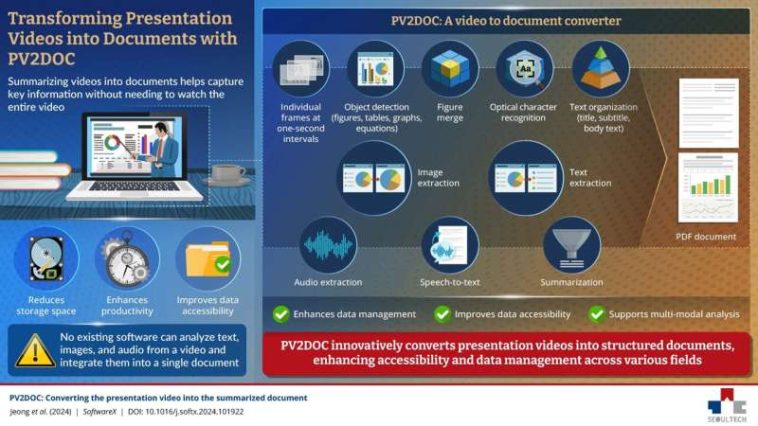
Para el procesamiento de imágenes, PV2DOC extrae fotogramas del vídeo a intervalos de un segundo. Utiliza un método llamado índice de similitud estructural, que compara cada cuadro con el anterior para identificar cuadros únicos. Los objetos en cada cuadro, como figuras, tablas, gráficos y ecuaciones, son luego detectados por los modelos de detección de objetos, Mask R-CNN y YOLOv5.
Durante este proceso, algunas imágenes pueden fragmentarse debido a espacios en blanco o subfiguras. Para resolver esto, PV2DOC utiliza una técnica de fusión de figuras que identifica áreas superpuestas y las combina en una sola figura. A continuación, el sistema aplica el reconocimiento óptico de caracteres (OCR) utilizando el motor Google Tesseract para extraer texto de las imágenes. Luego, el texto extraído se organiza en un formato estructurado, como títulos y párrafos.
Al mismo tiempo, PV2DOC extrae el audio del vídeo y utiliza el modelo Whisper, una herramienta de conversión de voz a texto (STT) de código abierto, para convertirlo en texto escrito. Luego, el texto transcrito se resume utilizando el algoritmo TextRank, creando un resumen de los puntos principales.
Las imágenes y el texto extraídos se combinan en un documento Markdown, que se puede convertir en un archivo PDF. El documento final presenta el contenido del vídeo (como texto, figuras y fórmulas) de forma clara y organizada, siguiendo la estructura del vídeo original.
Al convertir datos de video no organizados en documentos estructurados con capacidad de búsqueda, PV2DOC mejora la accesibilidad del video y reduce el espacio de almacenamiento necesario para compartir y almacenar el video.
«Este software simplifica el almacenamiento de datos y facilita el análisis de datos para vídeos de presentación transformando datos no estructurados en un formato estructurado, ofreciendo así un potencial significativo desde las perspectivas de accesibilidad de la información y gestión de datos. Proporciona una base para una utilización más eficiente de los vídeos de presentación», afirma Profesor Kwon.
Los investigadores planean simplificar aún más el contenido de vídeo en formatos accesibles. Su próximo objetivo es entrenar un modelo de lenguaje grande (LLM), similar a ChatGPT, para ofrecer un servicio de respuesta a preguntas, donde los usuarios pueden hacer preguntas basadas en el contenido de los videos, y el modelo genera respuestas precisas y contextualmente relevantes.
Más información:
Won-Ryeol Jeong et al, PV2DOC: Conversión del vídeo de presentación en un documento resumido, SoftwareX (2024). DOI: 10.1016/j.softx.2024.101922
Proporcionado por la Universidad Nacional de Ciencia y Tecnología de Seúl
Citación: PV2DOC: la nueva herramienta resume los videos de presentación en documentos PDF estructurados y con capacidad de búsqueda (2024, 30 de diciembre) recuperado el 30 de diciembre de 2024 de https://techxplore.com/news/2024-12-pv2doc-tool-videos-searchable-pdf.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.


GIPHY App Key not set. Please check settings