
|
|
Hoy anunciamos dos nuevas funciones de entrenamiento de modelos de IA dentro de Amazon SageMaker HyperPod: entrenamiento sin puntos de control, un enfoque que mitiga la necesidad de una recuperación tradicional basada en puntos de control al permitir la recuperación de estado de igual a igual, y entrenamiento elástico, que permite que las cargas de trabajo de IA escale automáticamente según la disponibilidad de recursos.
- Entrenamiento sin control – El entrenamiento sin puntos de control elimina los ciclos disruptivos de reinicio en los puntos de control, lo que mantiene el impulso del entrenamiento hacia adelante a pesar de las fallas y reduce el tiempo de recuperación de horas a minutos. Acelere el desarrollo de su modelo de IA, recupere días de los cronogramas de desarrollo y escale con confianza los flujos de trabajo de capacitación a miles de aceleradores de IA.
- Entrenamiento elástico – El entrenamiento elástico maximiza la utilización del clúster a medida que las cargas de trabajo de entrenamiento se expanden automáticamente para utilizar la capacidad inactiva a medida que está disponible y se contraen para producir recursos a medida que las cargas de trabajo de mayor prioridad, como los volúmenes de inferencia, alcanzan su punto máximo. Ahorre horas de ingeniería por semana dedicadas a reconfigurar trabajos de capacitación según la disponibilidad informática.
En lugar de dedicar tiempo a administrar la infraestructura de capacitación, estas nuevas técnicas de capacitación significan que su equipo puede concentrarse por completo en mejorar el rendimiento del modelo y, en última instancia, hacer que sus modelos de IA lleguen al mercado más rápido. Al eliminar las dependencias tradicionales de los puntos de control y utilizar plenamente la capacidad disponible, puede reducir significativamente los tiempos de finalización de la capacitación del modelo.
Entrenamiento sin controles: cómo funciona
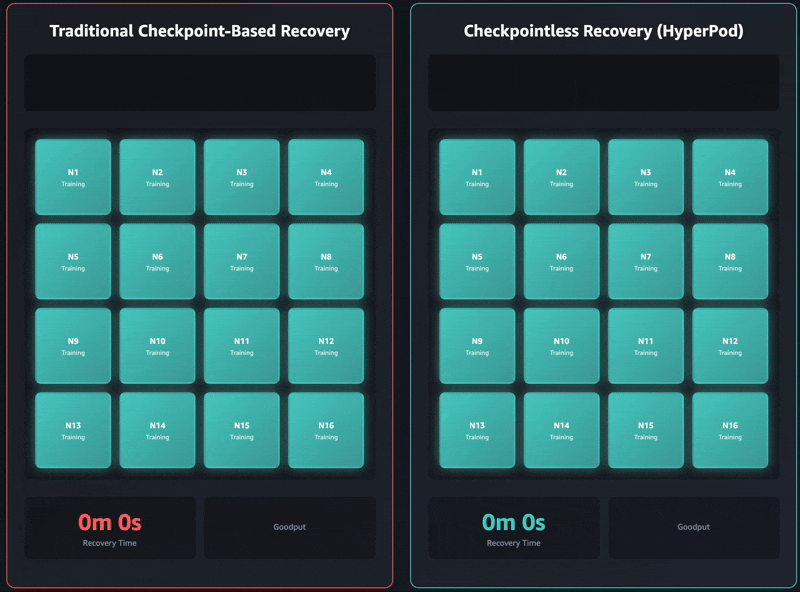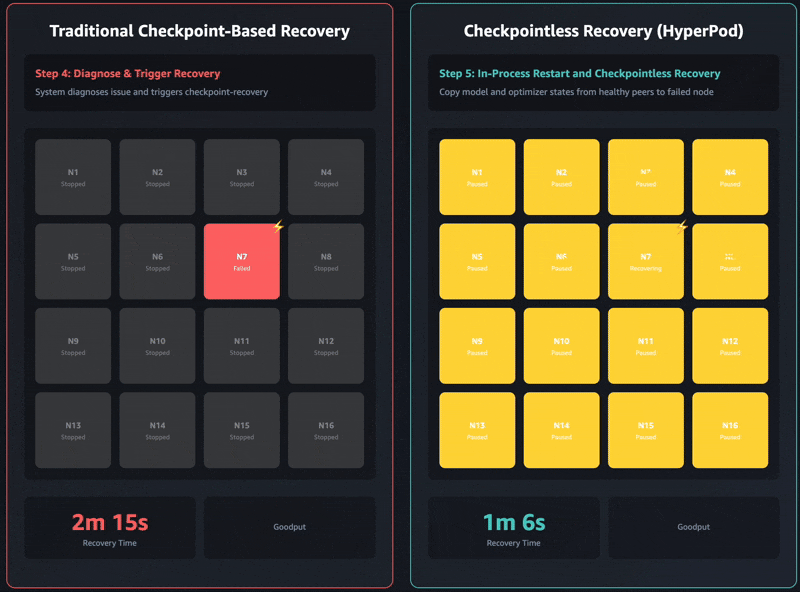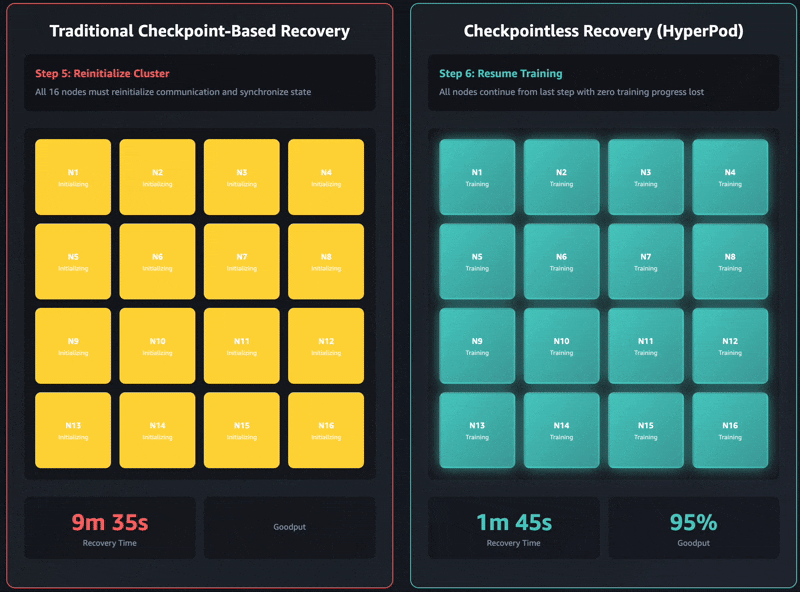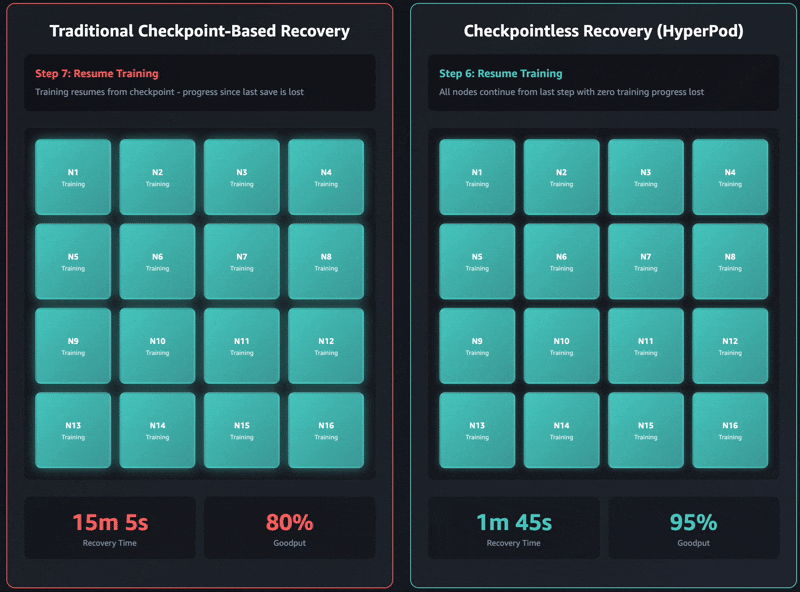
La recuperación tradicional basada en puntos de control tiene estas etapas de trabajo secuenciales: 1) finalización y reinicio del trabajo, 2) descubrimiento de procesos y configuración de la red, 3) recuperación de puntos de control, 4) inicialización del cargador de datos y 5) reanudación del ciclo de entrenamiento. Cuando se producen fallas, cada etapa puede convertirse en un cuello de botella y la recuperación del entrenamiento puede tardar hasta una hora en los grupos de entrenamiento autogestionados. Todo el grupo debe esperar a que se complete cada etapa antes de poder reanudar el entrenamiento. Esto puede llevar a que todo el grupo de capacitación quede inactivo durante las operaciones de recuperación, lo que aumenta los costos y extiende el tiempo de comercialización.
El entrenamiento sin puntos de control elimina este cuello de botella por completo al mantener la preservación continua del estado del modelo en todo el grupo de entrenamiento. Cuando ocurren fallas, el sistema se recupera instantáneamente mediante el uso de pares sanos, evitando la necesidad de una recuperación basada en puntos de control que requiere reiniciar todo el trabajo. Como resultado, la capacitación sin puntos de control permite la recuperación de fallas en minutos.
La capacitación sin puntos de control está diseñada para una adopción incremental y se basa en cuatro componentes principales que funcionan juntos: 1) optimizaciones de inicialización de comunicaciones colectivas, 2) carga de datos mapeados en memoria que permite el almacenamiento en caché, 3) recuperación en proceso y 4) replicación de estado de igual a igual sin puntos de control. Estos componentes se organizan a través del operador de capacitación HyperPod que se utiliza para iniciar el trabajo. Cada componente optimiza un paso específico en el proceso de recuperación y juntos permiten la detección y recuperación automática de fallas de infraestructura en minutos sin intervención manual, incluso con miles de aceleradores de IA. Puede habilitar progresivamente cada una de estas funciones a medida que su entrenamiento aumenta.
Los últimos modelos de Amazon Nova se entrenaron utilizando esta tecnología en decenas de miles de aceleradores. Además, según estudios internos sobre tamaños de clúster que van desde 16 GPU hasta más de 2000 GPU, el entrenamiento sin puntos de control mostró mejoras significativas en los tiempos de recuperación, reduciendo el tiempo de inactividad en más del 80 % en comparación con la recuperación tradicional basada en puntos de control.
Para obtener más información, visite HyperPod Checkpointless Training en la Guía para desarrolladores de IA de Amazon SageMaker.
Entrenamiento elástico: cómo funciona
En los clústeres que ejecutan diferentes tipos de cargas de trabajo de IA modernas, la disponibilidad del acelerador puede cambiar continuamente a lo largo del día a medida que se completan las ejecuciones de entrenamiento de corta duración, se producen y disminuyen picos de inferencia o se liberan recursos de los experimentos completados. A pesar de esta disponibilidad dinámica de los aceleradores de IA, las cargas de trabajo de capacitación tradicionales permanecen atrapadas en su asignación informática inicial, incapaces de aprovechar los aceleradores inactivos sin intervención manual. Esta rigidez deja sin utilizar una valiosa capacidad de GPU e impide que las organizaciones maximicen su inversión en infraestructura.
 La capacitación elástica transforma la forma en que las cargas de trabajo de capacitación interactúan con los recursos del clúster. Los trabajos de capacitación pueden ampliarse automáticamente para utilizar los aceleradores disponibles y contraerse elegantemente cuando se necesitan recursos en otros lugares, todo ello manteniendo la calidad de la capacitación.
La capacitación elástica transforma la forma en que las cargas de trabajo de capacitación interactúan con los recursos del clúster. Los trabajos de capacitación pueden ampliarse automáticamente para utilizar los aceleradores disponibles y contraerse elegantemente cuando se necesitan recursos en otros lugares, todo ello manteniendo la calidad de la capacitación.
La elasticidad de la carga de trabajo se habilita a través del operador de capacitación HyperPod que organiza las decisiones de escalamiento a través de la integración con el plano de control y el programador de recursos de Kubernetes. Supervisa continuamente el estado del clúster a través de tres canales principales: eventos del ciclo de vida del pod, cambios en la disponibilidad de los nodos y señales de prioridad del programador de recursos. Este monitoreo integral permite la detección casi instantánea de oportunidades de escalado, ya sea de recursos recientemente disponibles o de solicitudes de cargas de trabajo de mayor prioridad.
El mecanismo de escalado se basa en agregar y eliminar réplicas paralelas de datos. Cuando hay recursos informáticos adicionales disponibles, nuevas réplicas paralelas de datos se unen al trabajo de capacitación, lo que acelera el rendimiento. Por el contrario, durante los eventos de reducción (por ejemplo, cuando una carga de trabajo de mayor prioridad solicita recursos), el sistema se reduce eliminando réplicas en lugar de finalizar todo el trabajo, lo que permite que la capacitación continúe con una capacidad reducida.
En diferentes escalas, el sistema preserva el tamaño del lote global y adapta las tasas de aprendizaje, evitando que la convergencia del modelo se vea afectada negativamente. Esto permite que las cargas de trabajo aumenten o disminuyan dinámicamente para utilizar los aceleradores de IA disponibles sin ninguna intervención manual.
Puede iniciar el entrenamiento elástico a través de las recetas de HyperPod para modelos básicos (FM) disponibles públicamente, incluidos Llama y GPT-OSS. Además, puede modificar sus scripts de entrenamiento de PyTorch para agregar controladores de eventos elásticos, que permiten que el trabajo escale dinámicamente.
Para obtener más información, visite HyperPod Elastic Training en la Guía para desarrolladores de IA de Amazon SageMaker. Para comenzar, busque el Recetas de HyperPod disponible en el repositorio de AWS GitHub.
Ahora disponible
Ambas funciones están disponibles en todas las regiones en las que Amazon SageMaker HyperPod está disponible. Puedes utilizar estas técnicas de entrenamiento sin coste adicional. Para obtener más información, visite la página del producto SageMaker HyperPod y la página de precios de SageMaker AI.
Pruébelo y envíe sus comentarios a AWS re: Publicación para SageMaker o a través de sus contactos habituales de AWS Support.
— chany

