|
|
Para crear modelos de aprendizaje automático, los ingenieros de aprendizaje automático deben desarrollar una canalización de transformación de datos para preparar los datos. El proceso de diseño de esta canalización lleva mucho tiempo y requiere una colaboración entre equipos entre ingenieros de aprendizaje automático, ingenieros de datos y científicos de datos para implementar la canalización de preparación de datos en un entorno de producción.
El objetivo principal de Amazon SageMaker Data Wrangler es facilitar las cargas de trabajo de preparación y procesamiento de datos. Con SageMaker Data Wrangler, los clientes pueden simplificar el proceso de preparación de datos y todos los pasos necesarios del flujo de trabajo de preparación de datos en una sola interfaz visual. SageMaker Data Wrangler reduce el tiempo para crear rápidamente prototipos e implementar cargas de trabajo de procesamiento de datos en producción, de modo que los clientes puedan integrarse fácilmente con los entornos de producción de MLOps.
Sin embargo, las transformaciones aplicadas a los datos del cliente para el entrenamiento del modelo deben aplicarse a los nuevos datos durante la inferencia en tiempo real. Sin soporte para SageMaker Data Wrangler en un punto final de inferencia en tiempo real, los clientes necesitan escribir código para replicar las transformaciones de su flujo en un script de preprocesamiento.
Presentamos la compatibilidad con la inferencia por lotes y en tiempo real en Amazon SageMaker Data Wrangler
Me complace compartir que ahora puede implementar flujos de preparación de datos desde SageMaker Data Wrangler para inferencias por lotes y en tiempo real. Esta característica le permite reutilizar el flujo de transformación de datos que creó en SageMaker Data Wrangler como un paso en las canalizaciones de inferencia de Amazon SageMaker.
La compatibilidad con SageMaker Data Wrangler para la inferencia por lotes y en tiempo real acelera su implementación de producción porque no es necesario repetir la implementación del flujo de transformación de datos. Ahora puede integrar SageMaker Data Wrangler con la inferencia de SageMaker. Los mismos flujos de transformación de datos creados con la interfaz de apuntar y hacer clic fácil de usar de SageMaker Data Wrangler, que contiene operaciones como el análisis de componentes principales y la codificación one-hot, se usarán para procesar sus datos durante la inferencia. Esto significa que no tiene que reconstruir la canalización de datos para una aplicación de inferencia por lotes y en tiempo real, y puede llegar a la producción más rápido.
Introducción a la inferencia por lotes y en tiempo real
Veamos cómo usar los soportes de implementación de SageMaker Data Wrangler. En este escenario, tengo un flujo dentro de SageMaker Data Wrangler. Lo que debo hacer es integrar este flujo en la inferencia por lotes y en tiempo real mediante la canalización de inferencia de SageMaker.
Primero, aplicaré algunas transformaciones al conjunto de datos para prepararlo para el entrenamiento.
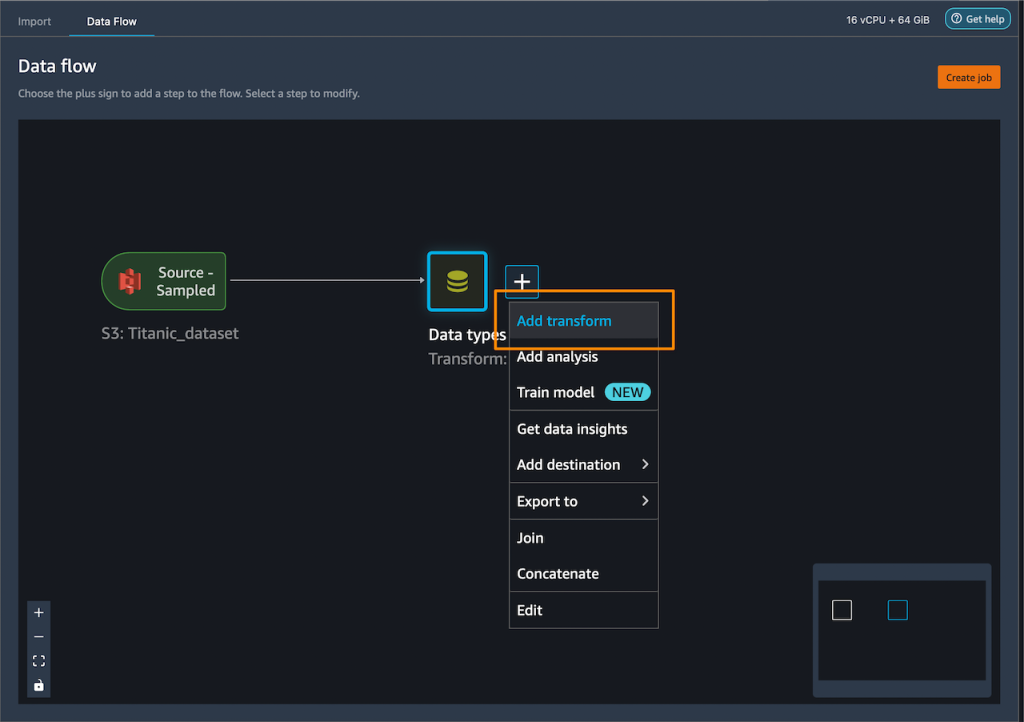
Agrego codificación one-hot en las columnas categóricas para crear nuevas funciones.
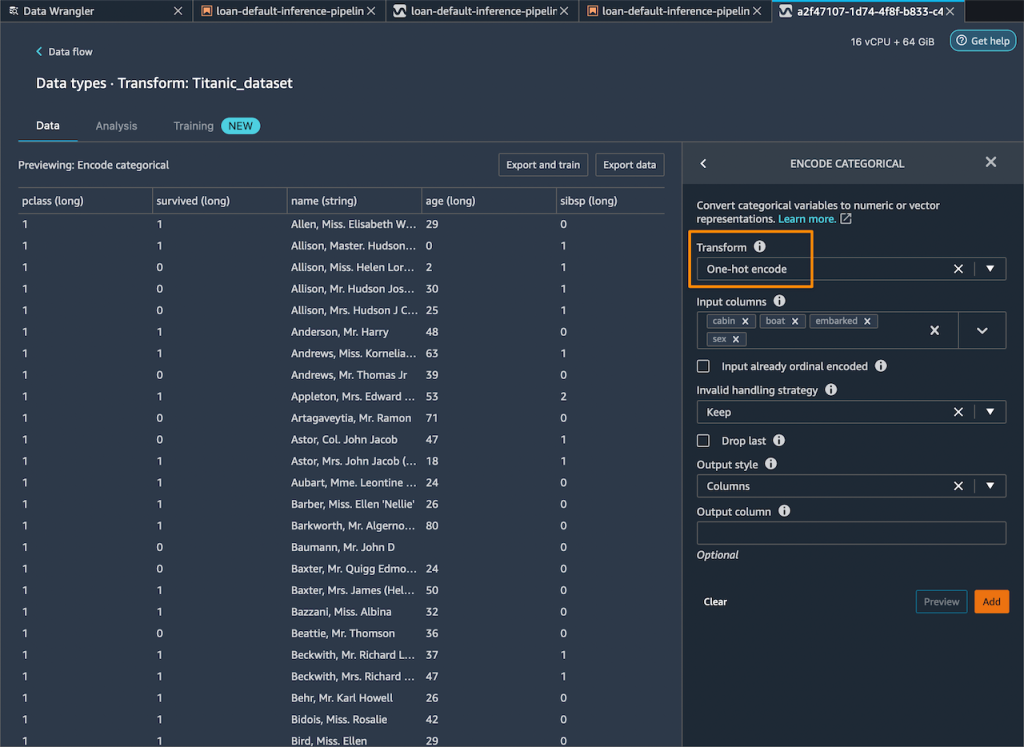
Luego, elimino las columnas de cadena restantes que no se pueden usar durante el entrenamiento.

Mi flujo resultante ahora tiene estos dos pasos de transformación.
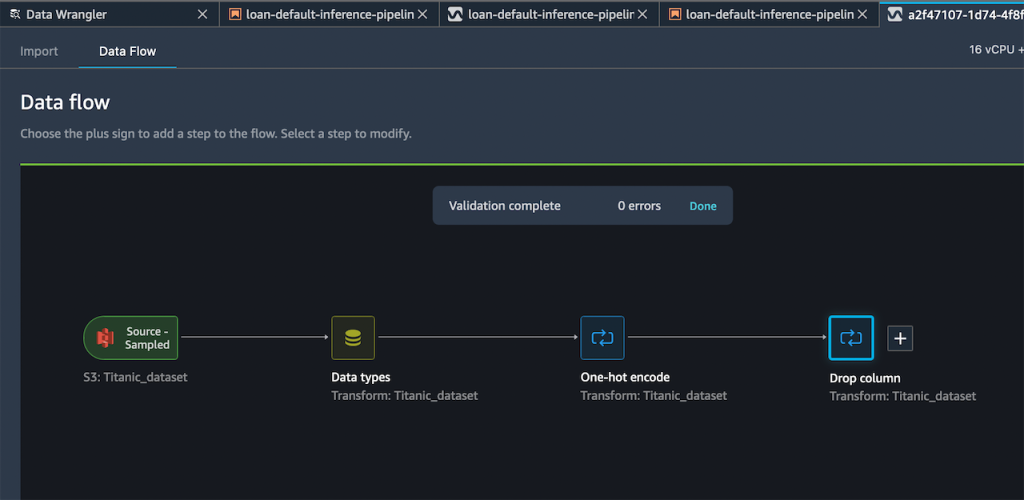
Una vez que estoy satisfecho con los pasos que he agregado, puedo expandir el Exportar a menú, y tengo la opción de exportar a Canal de inferencia de SageMaker (a través de Jupyter Notebook).

Yo selecciono Exportar a Canal de inferencia de SageMaker, y SageMaker Data Wrangler preparará un cuaderno Jupyter totalmente personalizado para integrar el flujo de SageMaker Data Wrangler con inferencia. Este cuaderno Jupyter generado realiza algunas acciones importantes. En primer lugar, defina el procesamiento de datos y los pasos de entrenamiento de modelos en una canalización de SageMaker. El siguiente paso es ejecutar la canalización para procesar mis datos con Data Wrangler y usar los datos procesados para entrenar un modelo que se usará para generar predicciones en tiempo real. Luego, implemente mi flujo de Data Wrangler y el modelo entrenado en un punto final en tiempo real como canalización de inferencia. Por último, invoque mi punto final para hacer una predicción.

Esta función utiliza el piloto automático de Amazon SageMaker, lo que me facilita la creación de modelos de aprendizaje automático. Solo necesito proporcionar el conjunto de datos transformado que es el resultado del paso SageMaker Data Wrangler y seleccionar la columna de destino para predecir. El resto estará a cargo de Amazon SageMaker Autopilot para explorar varias soluciones y encontrar el mejor modelo.

El uso de AutoML como un paso de entrenamiento de SageMaker Autopilot está habilitado de forma predeterminada en el cuaderno con el use_automl_step variable. Cuando uso el paso de AutoML, necesito definir el valor de target_attribute_name, que es la columna de mis datos que quiero predecir durante la inferencia. Alternativamente, puedo configurar use_automl_step a False si quiero usar el algoritmo XGBoost para entrenar un modelo en su lugar.
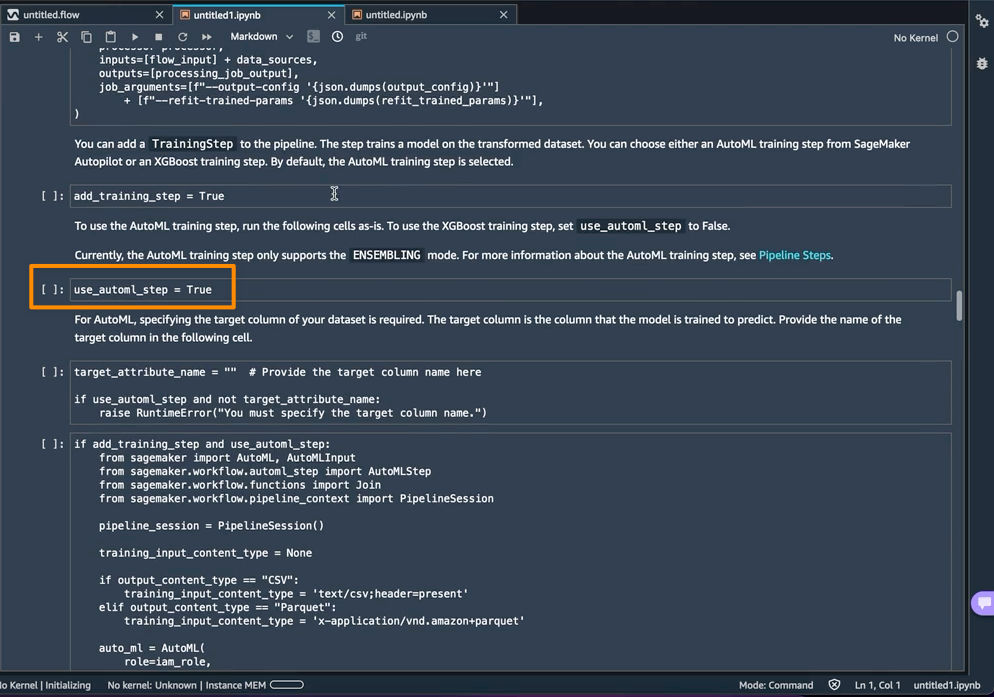
Por otro lado, si quisiera usar un modelo que entrené fuera de este cuaderno, entonces puedo pasar directamente al Crear canalización de inferencia de SageMaker sección del cuaderno. Aquí, tendría que establecer el valor de la byo_model variable a True. También necesito proporcionar el valor de algo_model_uri, que es el URI de Amazon Simple Storage Service (Amazon S3) donde se encuentra mi modelo. Al entrenar un modelo con el portátil, estos valores se completarán automáticamente.
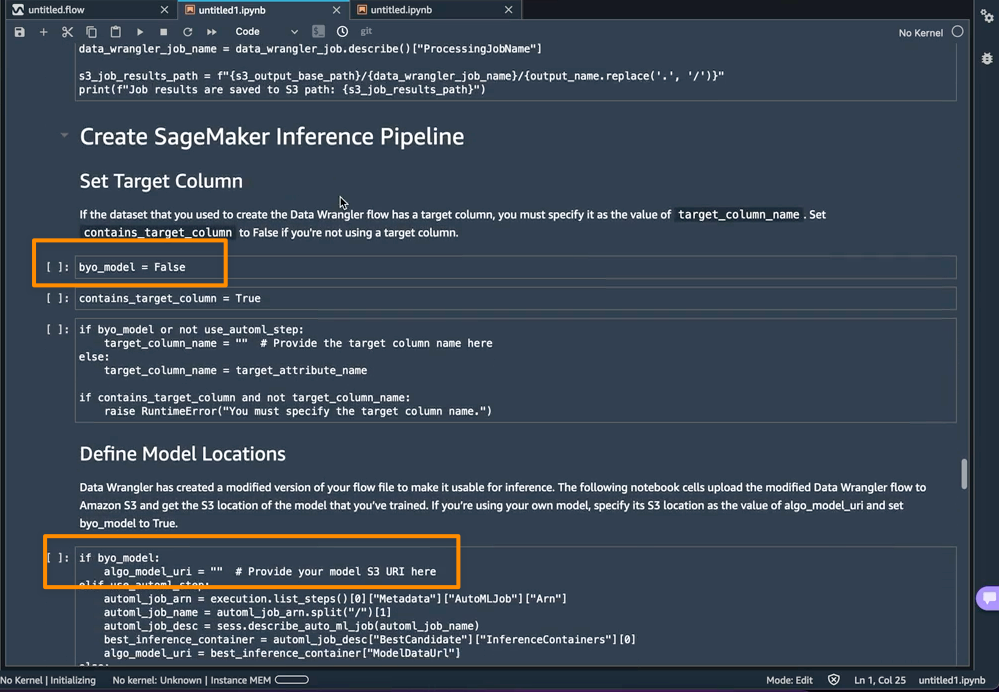
Además, esta característica también guarda un tarball dentro del data_wrangler_inference_flows carpeta en mi instancia de SageMaker Studio. Este archivo es una versión modificada del flujo de SageMaker Data Wrangler, que contiene los pasos de transformación de datos que se aplicarán en el momento de la inferencia. Se cargará en S3 desde el cuaderno para que se pueda usar para crear un paso de preprocesamiento de SageMaker Data Wrangler en la canalización de inferencia.
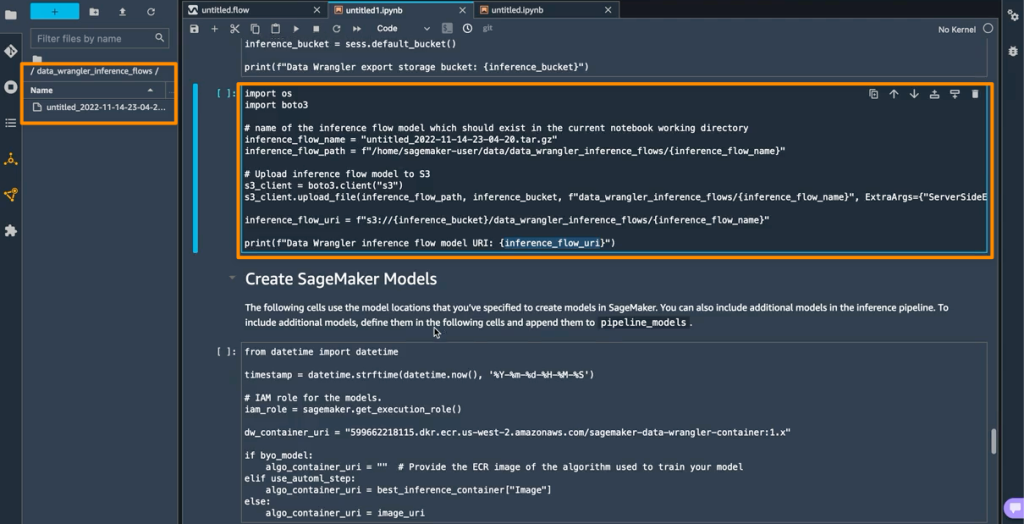
El siguiente paso es que este cuaderno creará dos objetos de modelo de SageMaker. El primer modelo de objeto es el objeto de modelo SageMaker Data Wrangler con la variable data_wrangler_modely el segundo es el objeto modelo del algoritmo, con la variable algo_model. Objeto data_wrangler_model se utilizará para proporcionar entrada en forma de datos que han sido procesados en algo_model para la predicción.
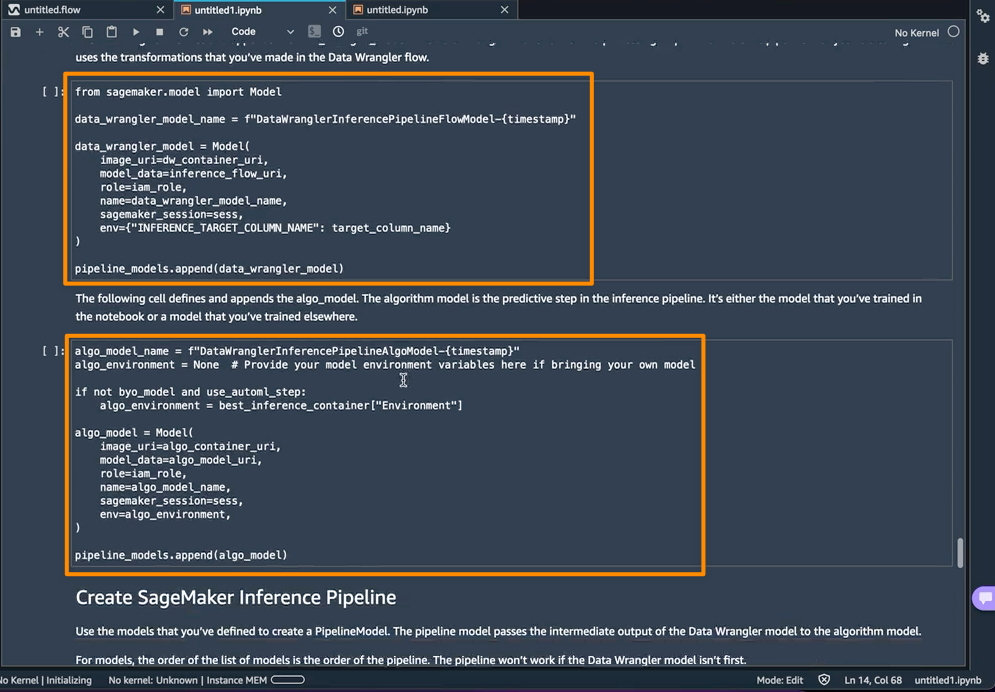
El paso final dentro de este cuaderno es crear un modelo de canalización de inferencia de SageMaker e implementarlo en un punto final.
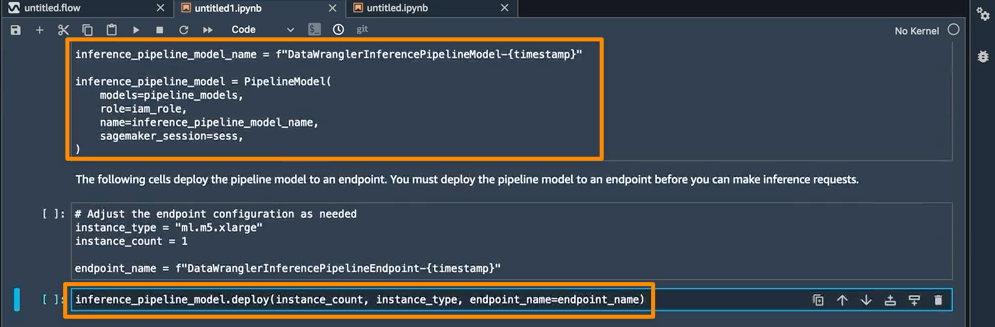
Una vez que se complete la implementación, obtendré un punto final de inferencia que puedo usar para la predicción. Con esta característica, la canalización de inferencia usa el flujo de SageMaker Data Wrangler para transformar los datos de su solicitud de inferencia en un formato que el modelo entrenado pueda usar.
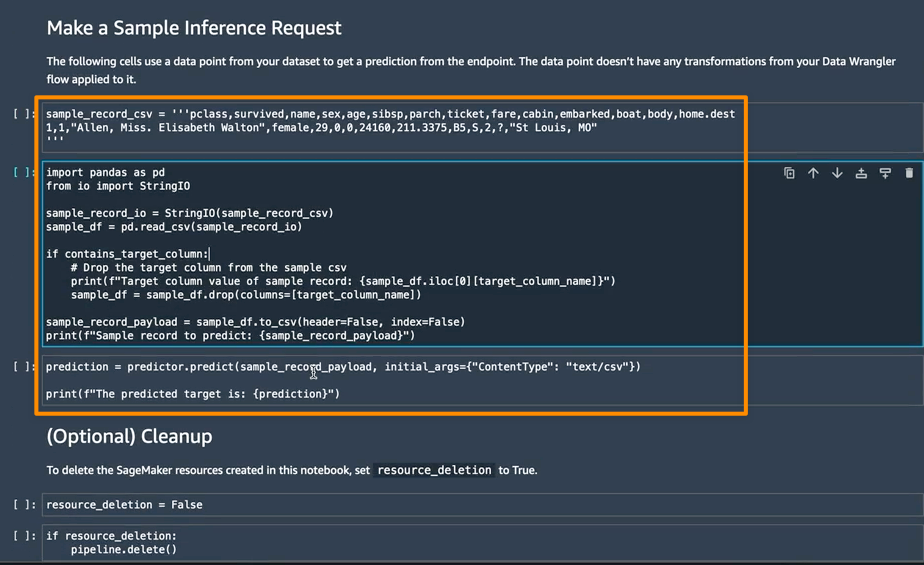
En la siguiente sección, puedo ejecutar celdas de cuaderno individuales en Hacer una solicitud de inferencia de muestra. Esto es útil si necesito hacer una verificación rápida para ver si el punto final funciona invocando el punto final con un único punto de datos de mis datos sin procesar. Data Wrangler coloca automáticamente este punto de datos en el cuaderno, por lo que no tengo que proporcionar uno manualmente.
Cosas que saber
Configuración mejorada de Apache Spark: En esta versión de SageMaker Data Wrangler, ahora puede configurar fácilmente cómo Apache Spark divide la salida de sus trabajos de SageMaker Data Wrangler al guardar datos en Amazon S3. Al agregar un nodo de destino, puede establecer la cantidad de particiones, correspondiente a la cantidad de archivos que se escribirán en Amazon S3, y puede especificar los nombres de las columnas para particionar, para escribir registros con diferentes valores de esas columnas en diferentes subdirectorios. en Amazon S3. Además, también puede definir la configuración en el cuaderno proporcionado.

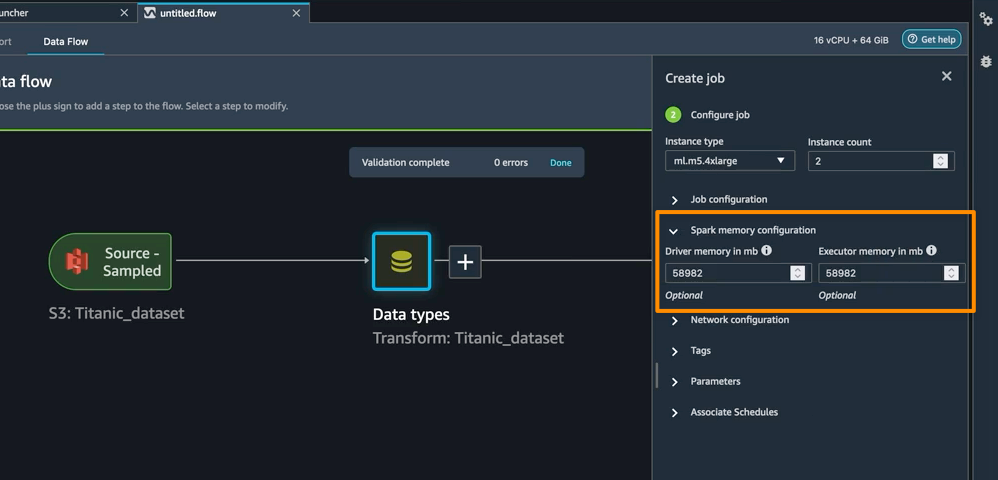
También puede definir configuraciones de memoria para trabajos de procesamiento de SageMaker Data Wrangler como parte del crear trabajo flujo de trabajo. Encontrará una configuración similar como parte de su computadora portátil.
Disponibilidad — SageMaker Data Wrangler es compatible con la inferencia por lotes y en tiempo real, así como la configuración mejorada de Apache Spark para cargas de trabajo de procesamiento de datos, por lo general están disponibles en todas las regiones de AWS que Data Wrangler admite actualmente.
Para comenzar con la compatibilidad de Amazon SageMaker Data Wrangler con la implementación de inferencia por lotes y en tiempo real, visite la documentación de AWS.
edificio feliz
— Donnie

