
|
|
La computación de alto rendimiento (HPC) permite a los científicos e ingenieros resolver problemas complejos que requieren mucha computación, como la dinámica de fluidos computacional (CFD), el pronóstico del tiempo y la genómica. Las aplicaciones de HPC suelen requerir instancias con un alto ancho de banda de memoria, una baja latencia, una interconexión de red de alto ancho de banda y acceso a un sistema de archivos paralelo rápido.
Muchos clientes recurrieron a AWS para ejecutar sus cargas de trabajo de HPC. Por ejemplo, Descartes Labs usó AWS para impulsar un Evaluación comparativa TOP500 LINPACK (los sistemas informáticos más potentes disponibles en el mercado) que generó 1,93 PFLOPS y se ubicó en la posición 136 de la lista TOP500 en junio de 2019. Esa ejecución utilizó 41 472 núcleos en un clúster de instancias C5 de Amazon EC2. El año pasado, Descartes Labs volvió a ejecutar el benchmark LINPACK y se ubicó entre los 40 primeros en la lista TOP500 de junio de 2021 con 172 692 núcleos en un clúster de instancias EC2, lo que representa un aumento del rendimiento del 417 % en solo dos años.
AWS le permite aumentar la velocidad de la investigación y reducir el tiempo de obtención de resultados al ejecutar HPC en la nube y escalar a decenas de miles de tareas paralelas que no serían prácticas en la mayoría de los entornos locales. AWS lo ayuda a reducir costos al proporcionar instancias de CPU, GPU y FPGA a pedido, Elastic Fabric Adapter (EFA), un dispositivo de red EC2 que mejora el rendimiento y escala las cargas de trabajo estrechamente acopladas, y AWS ParallelCluster, una herramienta de administración de clústeres de código abierto que le facilita la implementación y administración de clústeres de HPC en AWS.
Anuncio de instancias EC2 Hpc6a para cargas de trabajo de HPC
Actualmente, los clientes de diversas industrias utilizan instancias de Amazon EC2 habilitadas para EFA optimizadas para computación (por ejemplo, C5n, R5n, M5n y M5zn) para maximizar el rendimiento de una variedad de cargas de trabajo de HPC, pero a medida que estas cargas de trabajo escalan a decenas de miles de núcleos , la rentabilidad se vuelve cada vez más importante. Hemos descubierto que los clientes no solo buscan optimizar el rendimiento de sus cargas de trabajo de HPC, sino que también quieren optimizar los costos.
Como anunciamos previamente en noviembre de 2021, Hpc6a, una nueva instancia EC2 optimizada para HPC, está disponible en general a partir de hoy. Esta instancia ofrece redes de 100 Gbps a través de EFA con 96 núcleos de procesador AMD EPYC™ de tercera generación (Milan) con 384 GB de RAM, y ofrece una relación precio-rendimiento hasta un 65 % mejor que las instancias optimizadas para computación basadas en x86 comparables.
Puede lanzar instancias Hpc6a hoy en las regiones EE. UU. Este (Ohio) y GovCloud (EE. UU. Oeste) en alojamiento bajo demanda y dedicado o como parte de un plan de ahorro. Aquí están las especificaciones detalladas:
| Nombre de instancia | CPU* | RAM | Ancho de banda de la red EFA | Almacenamiento adjunto |
| hpc6a.48xgrande | 96 | 384 GiB | Hasta 100 Gbps | Solo EBS |
*Las instancias Hpc6a tienen subprocesos múltiples simultáneos deshabilitados para optimizar los códigos HPC. Esto significa que, a diferencia de otras instancias EC2, las CPU virtuales Hpc6a son núcleos físicos, no subprocesos.
Para permitir un rendimiento de subprocesos predecible y una programación eficiente para las cargas de trabajo de HPC, se deshabilitan los subprocesos múltiples simultáneos. Gracias a AWS Nitro System, no se retienen núcleos para el hipervisor, lo que hace que todos los núcleos estén disponibles para su código.
Las instancias Hpc6a presentan una serie de funciones específicas para ofrecer optimizaciones de costos y rendimiento para los clientes que ejecutan cargas de trabajo de HPC estrechamente acopladas que dependen de altos niveles de comunicaciones entre instancias. Estas instancias permiten un ancho de banda de red EFA de 100 Gbps y están diseñadas para escalar de manera eficiente grandes clústeres estrechamente acoplados dentro de una única zona de disponibilidad.
Escuchamos de muchos de nuestros clientes de ingeniería, como los del sector automotriz, que quieren reducir la necesidad de pruebas físicas y avanzar hacia un proceso de diseño de productos basado en simulación cada vez más virtual más rápido a un costo menor.
De acuerdo con nuestros resultados de evaluación comparativa para la simulación CFD automotriz Simcenter STAR-CCM+ de Siemens, cuando el Hpc6a escala hasta 400 nodos (aproximadamente 40 000 núcleos), con la ayuda de la red EFA, puede mantener una eficiencia de escalado de aproximadamente el 100 %. La instancia Hpc6a muestra un costo 70 por ciento más bajo en comparación con c5n, lo que significa que las empresas pueden entregar nuevos diseños más rápido y a un costo menor cuando usan instancias Hpc6a. Esto significa que las empresas pueden entregar nuevos diseños más rápido y a un costo menor cuando usan instancias Hpc6a.
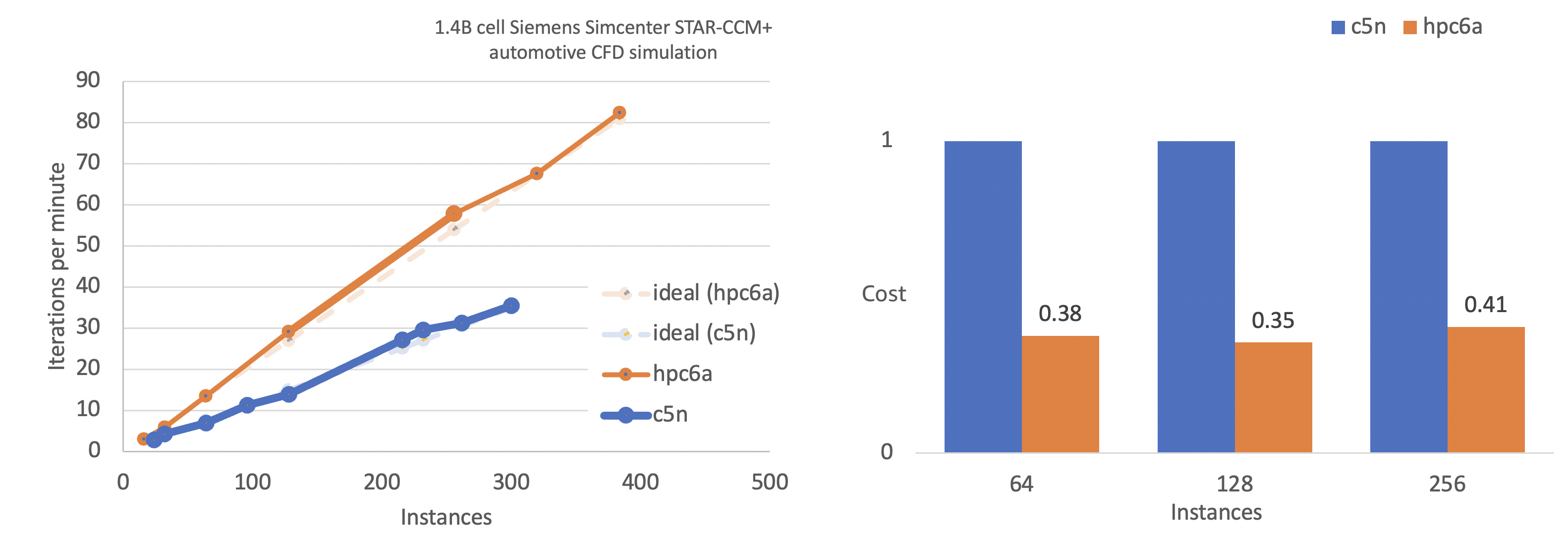
Puede usar la instancia Hpc6a con procesadores AMD EPYC de tercera generación (Milan) para ejecutar sus simulaciones de HPC más grandes y complejas en EC2 y optimizar el costo y el rendimiento. Los clientes también pueden usar las nuevas instancias Hpc6a con AWS Batch y AWS ParallelCluster para simplificar el envío de cargas de trabajo y la creación de clústeres.
Para obtener más información, visite nuestro Página de instancia de hpc6a y ponerse en contacto con nuestro equipo HPC, AWS re: publicar para EC2, o a través de sus contactos habituales de AWS Support.
– channy

