|
|
Hoy, anunciamos una nueva opción de implementación Multi-AZ de Amazon Relational Database Service (RDS) con una latencia de compromiso de transacciones hasta 2 veces más rápida, conmutaciones por error automatizadas generalmente en menos de 35 segundos e instancias en espera legibles.
Amazon RDS ofrece dos opciones de replicación para mejorar la disponibilidad y el rendimiento:
- Las implementaciones Multi-AZ brindan alta disponibilidad y conmutación por error automática. Amazon RDS crea una réplica a nivel de almacenamiento de la base de datos en una segunda zona de disponibilidad. Luego replica sincrónicamente los datos desde la instancia de base de datos primaria a la de reserva para lograr una alta disponibilidad. La instancia de base de datos principal atiende solicitudes de aplicaciones, mientras que la instancia de base de datos en espera permanece lista para tomar el control en caso de falla. Amazon RDS administra todos los aspectos de la detección de fallas, la conmutación por error y las acciones de reparación para que las aplicaciones que utilizan la base de datos puedan tener una alta disponibilidad.
- Las réplicas de lectura permiten que las aplicaciones escalen sus operaciones de lectura en varias instancias de bases de datos. El motor de la base de datos replica los datos de forma asíncrona en las réplicas de lectura. La aplicación envía las solicitudes de escritura (
INSERT,UPDATEyDELETE) a la base de datos principal y las solicitudes de lectura (SELECT) se puede equilibrar la carga en las réplicas de lectura. En caso de falla del nodo principal, puede promover manualmente una réplica de lectura para que se convierta en la nueva base de datos principal.
Las implementaciones Multi-AZ y las réplicas de lectura tienen diferentes propósitos. Las implementaciones Multi-AZ brindan a su aplicación alta disponibilidad, durabilidad y conmutación por error automática. Las réplicas de lectura brindan escalabilidad de lectura a sus aplicaciones.
Pero, ¿qué pasa con las aplicaciones que requieren alta disponibilidad con conmutación por error automática y escalabilidad de lectura?
Presentamos la nueva opción de implementación Multi-AZ de Amazon RDS con dos instancias en espera legibles.
A partir de hoy, agregaremos una nueva opción para implementar bases de datos RDS. Esta opción combina la conmutación por error automática y las réplicas de lectura: Amazon RDS Multi-AZ con dos instancias en espera legibles. Esta opción de implementación está disponible para bases de datos MySQL y PostgreSQL. Este es un clúster de base de datos con una instancia principal y dos instancias en espera legibles. Proporciona una latencia de confirmación de transacciones hasta 2 veces más rápida y conmutaciones por error automatizadas, normalmente en menos de 35 segundos.
El siguiente diagrama ilustra una implementación de este tipo:
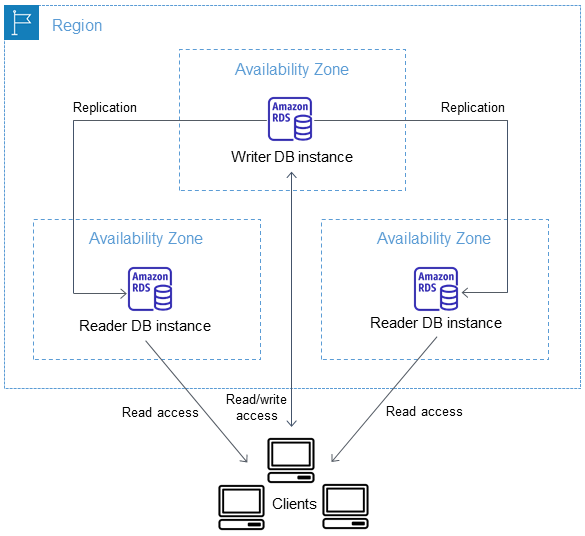
Cuando la nueva opción de implementación de clúster de base de datos Multi-AZ está habilitada, RDS configura una base de datos principal y dos réplicas de lectura en tres zonas de disponibilidad distintas. Luego supervisa y habilita la conmutación por error en caso de falla del nodo principal.
Al igual que con las réplicas de lectura tradicionales, el motor de la base de datos replica los datos entre el nodo principal y las réplicas de lectura. Y al igual que con la opción de implementación en espera Multi-AZ one, RDS detecta y administra automáticamente la conmutación por error para una alta disponibilidad.
No tiene que elegir entre alta disponibilidad o escalabilidad; El clúster de base de datos Multi-AZ con dos modos de espera legibles habilita ambos.
¿Cuales son los beneficios?
Esta nueva opción de implementación le ofrece cuatro beneficios sobre las implementaciones multi-AZ tradicionales: latencia de confirmación mejorada, conmutación por error más rápida, instancias en espera legibles y replicaciones optimizadas.
Primero, las operaciones de escritura son más rápidas cuando se utiliza el clúster de base de datos Multi-AZ. Las nuevas instancias de clúster de base de datos Multi-AZ aprovechan los tipos de instancias M6gd y R6gd. Estas instancias funcionan con procesadores AWS Graviton2. Están equipados con rápido NVMe SSD para almacenamiento local, ideal para almacenamiento de alta velocidad y baja latencia. Ofrecen hasta un 40 % más de rendimiento de precio y un 50 % más de GB de almacenamiento local por vCPU en comparación con instancias comparables basadas en x86.
Las instancias de base de datos Multi-AZ utilizan Amazon Elastic Block Store (EBS) para almacenar los datos y el registro de transacciones. Las nuevas instancias de clúster de base de datos Multi-AZ utilizan el almacenamiento local proporcionado por las instancias para almacenar el registro de transacciones. El almacenamiento local está optimizado para ofrecer operaciones de E/S altas y de baja latencia por segundo (IOPS) a las aplicaciones. Las operaciones de escritura se escriben primero en el registro de transacciones del almacenamiento local y luego se descargan en el almacenamiento permanente en los volúmenes de almacenamiento de la base de datos.
Segundo, las operaciones de conmutación por error suelen ser más rápidas que en la instancia de base de datos Multi-AZ guión. Las réplicas de lectura creadas por el nuevo clúster de base de datos Multi-AZ son instancias de base de datos completas. El sistema está diseñado para fallar en tan solo 35 segundos, más el tiempo para aplicar cualquier registro de transacciones pendiente. En caso de conmutación por error, el sistema está completamente automatizado para promocionar un nuevo primario y reconfigurar el antiguo primario como una nueva instancia de lector.
Tercera, las dos instancias en espera son esperas activas. Sus aplicaciones pueden usar el extremo del lector del clúster para enviar sus solicitudes de lectura (SELECT) a estas instancias en espera. Permite que su aplicación distribuya la carga de lectura de la base de datos por igual entre las instancias del clúster de la base de datos.
Y finalmente, aprovechar el almacenamiento local para el registro de transacciones optimiza la replicación. La instancia de base de datos Multi-AZ existente replica todos los cambios a nivel de almacenamiento. El nuevo clúster de base de datos Multi-AZ replica solo el registro de transacciones y utiliza un mecanismo de quórum para confirmar que al menos un standby reconoció el cambio. Las transacciones de la base de datos se confirman sincrónicamente cuando una de las instancias secundarias confirma que el registro de transacciones está escrito en su disco local.
Migración de bases de datos existentes
Para aquellos de ustedes que tienen bases de datos RDS existentes y desean aprovechar esta nueva opción de implementación de clúster de base de datos Multi-AZ, pueden tomar una instantánea de su base de datos para crear una copia de seguridad a nivel de almacenamiento de su instancia de base de datos existente. Una vez que la instantánea esté lista, puede crear un nuevo clúster de base de datos, con la opción de implementación de clúster de base de datos Multi-AZ, en función de esta instantánea. Su nuevo clúster de base de datos Multi-AZ será una copia perfecta de su base de datos existente.
Veámoslo en acción
Para comenzar, apunto mi navegador a la Consola de administración de AWS y navego a RDS. La opción de implementación de clúster de base de datos Multi-AZ está disponible para MySQL versión 8.0.28 o posterior y PostgreSQL versión 13.4 R1 y 13.5 R1. Selecciono cualquier motor de base de datos y me aseguro de que la versión cumpla con los requisitos mínimos. El resto del procedimiento es el mismo que el lanzamiento de una base de datos estándar de Amazon RDS.
Bajo Opciones de implementaciónYo selecciono postgresqlversión 13.4 R1Y debajo Disponibilidad y DurabilidadYo selecciono Clúster de base de datos Multi-AZ.

Si es necesario, puedo elegir el conjunto de usos RDS de zonas de disponibilidad para el clúster. Para hacerlo, creo un grupo de subred de base de datos y asigno el clúster a este grupo de subred.
Una vez lanzado, verifico que se hayan creado tres instancias de base de datos. También tomo nota de los dos puntos de enlace proporcionados por Amazon RDS: el punto de enlace principal y un punto de enlace con equilibrio de carga para las dos instancias en espera legibles.
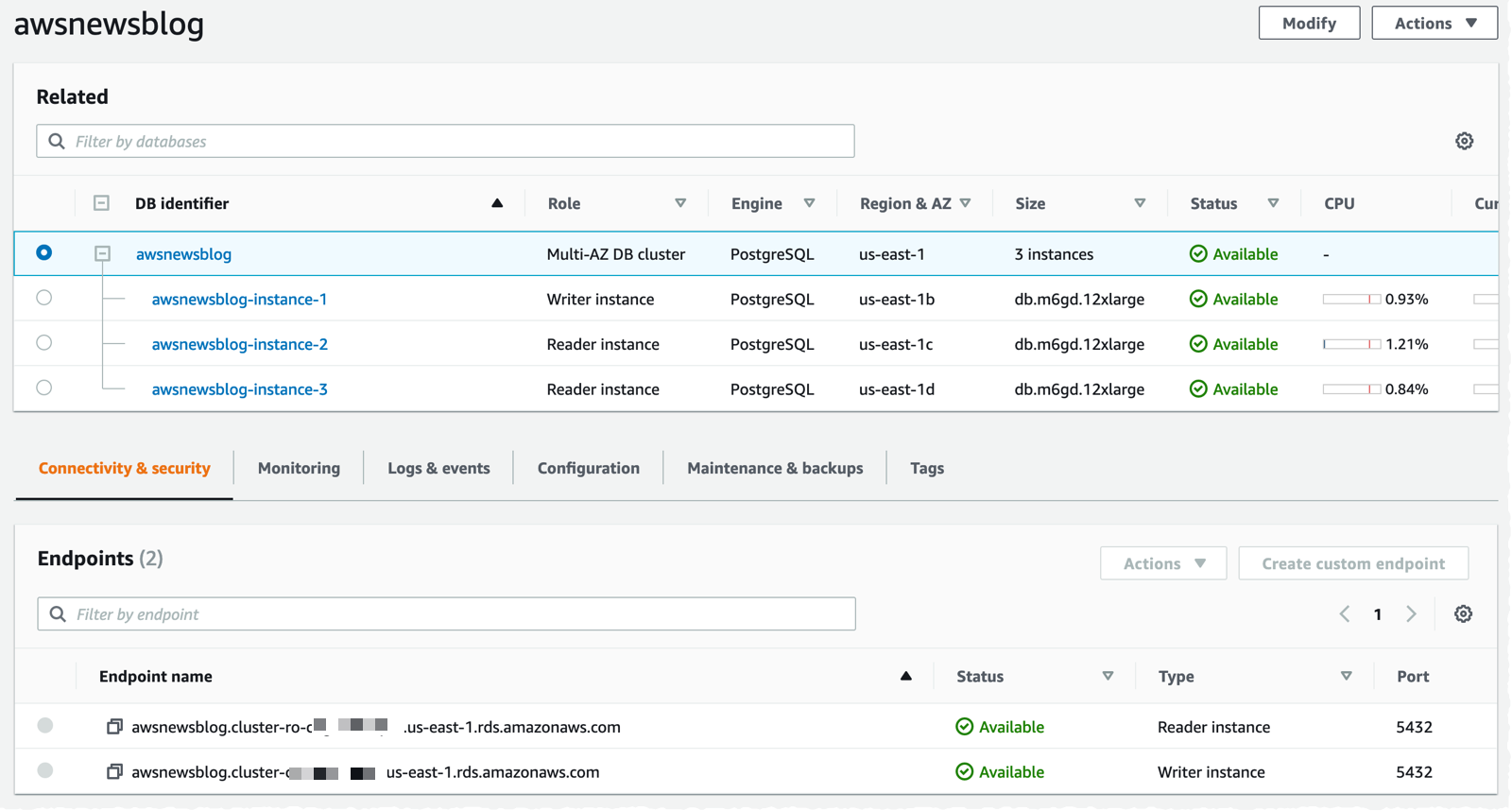
Para probar el nuevo clúster, creo una instancia EC2 de Amazon Linux 2 en la misma VPC, dentro del mismo grupo de seguridad que la base de datos, y me aseguro de adjuntar un rol de IAM que contenga la política administrada de AmazonSSMManagedInstanceCore. Esto me permite conectarme a la instancia mediante SSM en lugar de SSH.
Una vez que se inicia la instancia, uso SSM para conectarme a la instancia. Instalo las herramientas de cliente de PostgreSQL.
sudo amazon-linux-extras enable postgresql13
sudo yum clean metadata
sudo yum install postgresqlMe conecto a la base de datos principal. Creo una tabla e INSERTO un registro.
psql -h awsnewsblog.cluster-c1234567890r.us-east-1.rds.amazonaws.com -U postgres
postgres=> create table awsnewsblogdemo (id int primary key, name varchar);
CREATE TABLE
postgres=> insert into awsnewsblogdemo (id,name) values (1, 'seb');
INSERT 0 1
postgres=> exitPara verificar que la replicación funciona como se esperaba, me conecto a la réplica de solo lectura. Observe la -ro- en el nombre del punto final. Compruebo la estructura de la tabla e ingreso un SELECT declaración para confirmar que los datos han sido replicados.
psql -h awsnewsblog.cluster-ro-c1234567890r.us-east-1.rds.amazonaws.com -U postgres
postgres=> \dt
List of relations
Schema | Name | Type | Owner
--------+-----------------+-------+----------
public | awsnewsblogdemo | table | postgres
(1 row)
postgres=> select * from awsnewsblogdemo;
id | name
----+------
1 | seb
(1 row)
postgres=> exitEn el escenario de una conmutación por error, la aplicación se desconectará de la instancia de la base de datos principal. En ese caso, es importante que su código de nivel de aplicación intente restablecer la conexión de red. Después de un breve período de tiempo, el nombre DNS del extremo apuntará a la instancia en espera y su aplicación podrá volver a conectarse.
Para obtener más información sobre los clústeres de base de datos Multi-AZ, puede consultar nuestra documentación.
Precios y disponibilidad
Las implementaciones de Amazon RDS Multi-AZ con dos modos de espera legibles generalmente están disponibles en las siguientes regiones: EE. UU. Este (Norte de Virginia), EE. UU. Oeste (Oregón) y Europa (Irlanda). Agregaremos más regiones a esta lista.
Puede usarlo con MySQL versión 8.0.28 o posterior, o PostgreSQL versión 13.4 R1 o 13.5 R1.
El precio depende del tipo de instancia. En las regiones de EE. UU., el precio bajo demanda comienza en $0,522 por hora para instancias M6gd y $0,722 por hora para instancias R6gd. Como de costumbre, la página de precios de Amazon RDS tiene los detalles de MySQL y PostgreSQL.
Puedes empezar a usarlo hoy.

