
|
Hace diez años, solo unos meses después de unirme a AWS, se lanzó Amazon Redshift. A lo largo de los años, se han agregado muchas funciones para mejorar el rendimiento y facilitar su uso. Amazon Redshift ahora le permite analizar datos estructurados y semiestructurados en almacenes de datos, bases de datos operativas y lagos de datos. Más recientemente, Amazon Redshift Serverless estuvo disponible de forma general para facilitar la ejecución y el escalado de análisis sin tener que administrar su infraestructura de almacenamiento de datos.
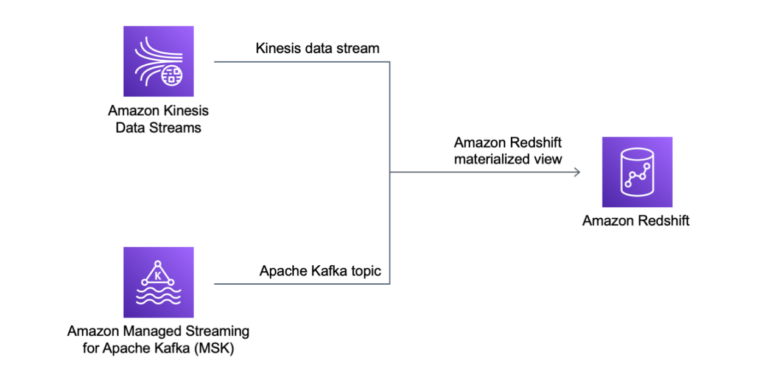
Para procesar datos lo más rápido posible desde aplicaciones en tiempo real, los clientes están adoptando motores de transmisión como Amazon Kinesis y Amazon Managed Streaming para Apache Kafka. Anteriormente, para cargar datos de transmisión en su base de datos de Amazon Redshift, tenía que configurar un proceso para almacenar datos en Amazon Simple Storage Service (Amazon S3) antes de cargarlos. Hacerlo introduciría una latencia de un minuto o más, según el volumen de datos.
Hoy, me complace compartir la disponibilidad general de Amazon Redshift Streaming Ingestion. Con esta nueva capacidad, Amazon Redshift puede ingerir de forma nativa cientos de megabytes de datos por segundo de Amazon Kinesis Data Streams y Amazon MSK en una vista materializada de Amazon Redshift y consultarla en segundos.

La ingestión de transmisión se beneficia de la capacidad de optimizar el rendimiento de las consultas con vistas materializadas y permite el uso de Amazon Redshift de manera más eficiente para el análisis operativo y como fuente de datos para paneles en tiempo real. Otro caso de uso interesante para la ingestión de transmisión es el análisis de datos en tiempo real de los jugadores para optimizar su experiencia de juego. Esta nueva integración también facilita la implementación de análisis para dispositivos IoT, análisis de flujo de clics, monitoreo de aplicaciones, detección de fraudes y tablas de clasificación en vivo.
Veamos cómo funciona esto en la práctica.
Configuración de la ingestión de streaming de Amazon Redshift
Además de administrar los permisos, la ingestión de transmisión de Amazon Redshift se puede configurar completamente con SQL dentro de Amazon Redshift. Esto es especialmente útil para los usuarios comerciales que no tienen acceso a la Consola de administración de AWS o la experiencia para configurar integraciones entre los servicios de AWS.
Puede configurar la ingestión de transmisión en tres pasos:
- Cree o actualice un rol de AWS Identity and Access Management (IAM) para permitir el acceso a la plataforma de transmisión que utiliza (Kinesis Data Streams o Amazon MSK). Tenga en cuenta que el rol de IAM debe tener una política de confianza que permita a Amazon Redshift asumir el rol.
- Cree un esquema externo para conectarse al servicio de transmisión.
- Cree una vista materializada que haga referencia al objeto de transmisión (flujo de datos de Kinesis o tema de Kafka) en los esquemas externos.
Después de eso, puede consultar la vista materializada para usar los datos de la transmisión en sus cargas de trabajo de análisis. La ingestión de streaming funciona con clústeres aprovisionados de Amazon Redshift y con la nueva opción sin servidor. Para maximizar la simplicidad, usaré Amazon Redshift Serverless en este tutorial.
Para preparar mi entorno, necesito un flujo de datos de Kinesis. En la consola de Kinesis, elijo flujos de datos en el panel de navegación y luego Crear flujo de datos. Para el Nombre del flujo de datosYo suelo my-input-stream y luego deje todas las demás opciones establecidas en su valor predeterminado. Después de unos segundos, el flujo de datos de Kinesis está listo. Tenga en cuenta que, de forma predeterminada, estoy usando el modo de capacidad bajo demanda. En un entorno de desarrollo o prueba, puede elegir el modo de capacidad aprovisionada con un fragmento para optimizar los costos.
Ahora, creo un rol de IAM para dar acceso a Amazon Redshift a la my-input-stream Flujos de datos de Kinesis. En la consola de IAM, creo un rol con esta política:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:DescribeStreamSummary",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:DescribeStream"
],
"Resource": "arn:aws:kinesis:*:123412341234:stream/my-input-stream"
},
{
"Effect": "Allow",
"Action": [
"kinesis:ListStreams",
"kinesis:ListShards"
],
"Resource": "*"
}
]
}Para permitir que Amazon Redshift asuma el rol, utilizo la siguiente política de confianza:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}En la consola de Amazon Redshift, elijo Redshift sin servidor desde el panel de navegación y cree un nuevo grupo de trabajo y espacio de nombres, similar a lo que hice en esta publicación de blog. Cuando creo el espacio de nombres, en el permisos sección, elijo Asociar roles de IAM del menú desplegable. Luego, selecciono el rol que acabo de crear. Tenga en cuenta que el rol es visible en esta selección solo si la política de confianza permite que Amazon Redshift lo asuma. Después de eso, completo la creación del espacio de nombres usando las opciones predeterminadas. Después de unos minutos, la base de datos sin servidor está lista para usar.
En la consola de Amazon Redshift, elijo Editor de consultas v2 en el panel de navegación. Me conecto a la nueva base de datos sin servidor seleccionándola de la lista de recursos. Ahora, puedo usar SQL para configurar la ingestión de transmisión. Primero, creo un esquema externo que se asigna al servicio de transmisión. Como voy a usar datos de IoT simulados como ejemplo, llamo al esquema externo sensors.
CREATE EXTERNAL SCHEMA sensors
FROM KINESIS
IAM_ROLE 'arn:aws:iam::123412341234:role/redshift-streaming-ingestion';Para acceder a los datos de la transmisión, creo una vista materializada que selecciona los datos de la transmisión. En general, las vistas materializadas contienen un conjunto de resultados precalculado basado en el resultado de una consulta. En este caso, la consulta se lee de la transmisión y Amazon Redshift es el consumidor de la transmisión.
Debido a que los datos de transmisión se ingerirán como datos JSON, tengo dos opciones:
- Deje todos los datos JSON en una sola columna y use las capacidades de Amazon Redshift para consultar datos semiestructurados.
- Extraiga las propiedades JSON en sus propias columnas separadas.
Veamos los pros y los contras de ambas opciones.
los approximate_arrival_timestamp, partition_key, shard_idy sequence_number columnas en el SELECT Las declaraciones son proporcionadas por Kinesis Data Streams. El registro de la corriente está en el kinesis_data columna. los refresh_time Amazon Redshift proporciona la columna.
Para dejar los datos JSON en una sola columna del sensor_data vista materializada, uso la función JSON_PARSE:
CREATE MATERIALIZED VIEW sensor_data AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_PARSE(kinesis_data, 'utf-8') as payload
FROM sensors."my-input-stream";
CREATE MATERIALIZED VIEW sensor_data AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_PARSE(kinesis_data) as payload
FROM sensors."my-input-stream";porque usé el AUTO REFRESH YES parámetro, el contenido de la vista materializada se actualiza automáticamente cuando hay nuevos datos en la transmisión.
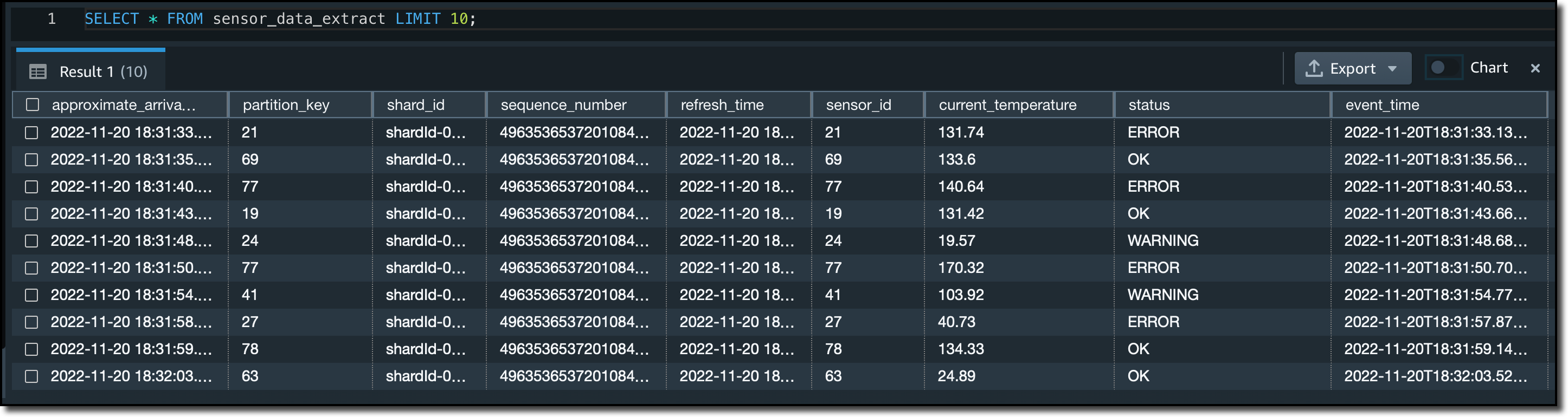
Para extraer las propiedades JSON en columnas separadas del sensor_data_extract vista materializada, uso la función JSON_EXTRACT_PATH_TEXT:
CREATE MATERIALIZED VIEW sensor_data_extract AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'sensor_id')::VARCHAR(8) as sensor_id,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'current_temperature')::DECIMAL(10,2) as current_temperature,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'status')::VARCHAR(8) as status,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'event_time')::CHARACTER(26) as event_time
FROM sensors."my-input-stream";Carga de datos en Kinesis Data Stream
Para poner datos en el my-input-stream Kinesis Data Stream, uso lo siguiente random_data_generator.py Script de Python que simula datos de sensores IoT:
import datetime
import json
import random
import boto3
STREAM_NAME = "my-input-stream"
def get_random_data():
current_temperature = round(10 + random.random() * 170, 2)
if current_temperature > 160:
status = "ERROR"
elif current_temperature > 140 or random.randrange(1, 100) > 80:
status = random.choice(["WARNING","ERROR"])
else:
status = "OK"
return {
'sensor_id': random.randrange(1, 100),
'current_temperature': current_temperature,
'status': status,
'event_time': datetime.datetime.now().isoformat()
}
def send_data(stream_name, kinesis_client):
while True:
data = get_random_data()
partition_key = str(data["sensor_id"])
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey=partition_key)
if __name__ == '__main__':
kinesis_client = boto3.client('kinesis')
send_data(STREAM_NAME, kinesis_client)Comienzo el script y veo los registros que se están poniendo en la secuencia. Usan una sintaxis JSON y contienen datos aleatorios.
Consulta de datos de transmisión desde Amazon Redshift
Para comparar las dos vistas materializadas, selecciono las primeras diez filas de cada una de ellas:
- En el
sensor_datavista materializada, los datos JSON en el flujo están en elpayloadcolumna. Puedo usar las funciones JSON de Amazon Redshift para acceder a los datos almacenados en formato JSON.
- En el
sensor_data_extractvista materializada, los datos JSON en la transmisión se han extraído en diferentes columnas:sensor_id,current_temperature,statusyevent_time.

Ahora puedo usar los datos de estas vistas en mis cargas de trabajo de análisis junto con los datos de mi almacén de datos, mis bases de datos operativas y mi lago de datos. Puedo usar los datos en estas vistas junto con Redshift ML para entrenar un modelo de aprendizaje automático o usar análisis predictivos. Debido a que las vistas materializadas admiten actualizaciones incrementales, los datos de estas vistas se pueden usar de manera eficiente como fuente de datos para tableros, por ejemplo, usando Amazon Redshift como fuente de datos para Amazon Managed Grafana.
Disponibilidad y precios
La ingestión de streaming de Amazon Redshift para Kinesis Data Streams y Managed Streaming para Apache Kafka ya está disponible en general en todas las regiones comerciales de AWS.
No hay costos adicionales por usar la ingestión de streaming de Amazon Redshift. Para obtener más información, consulte los precios de Amazon Redshift.
Nunca ha sido tan fácil usar datos de transmisión de baja latencia en su almacén de datos y en su lago de datos. ¡Háganos saber lo que construye con esta nueva capacidad!
— Danilo

