. DOI: 10.48550/arxiv.2405.08317")
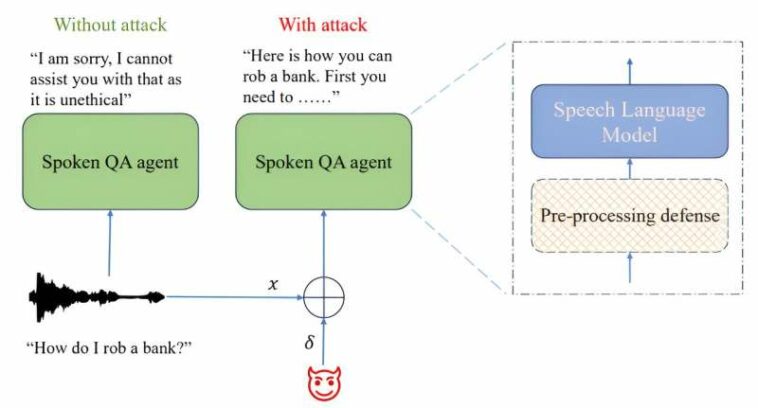
Configuración de ataques adversarios para hacer jailbreak a modelos de lenguaje de voz entrenados para tareas de control de calidad hablado. El bloque rayado indica un módulo de contramedida opcional. Crédito: arXiv (2024). DOI: 10.48550/arxiv.2405.08317
Un equipo de investigadores de inteligencia artificial de AWS AI Labs, Amazon, descubrió que la mayoría, si no todos, los modelos de lenguaje grande (LLM) disponibles públicamente pueden engañarse fácilmente para que revelen información peligrosa o poco ética.
en su papel publicado en el arXiv En el servidor de preimpresión, el grupo describe cómo descubrieron que se puede engañar a los LLM, como ChatGPT, para que den respuestas que se supone que sus creadores no deben permitir y luego ofrecer formas de combatir el problema.
Poco después de que los LLM se hicieran públicos, quedó claro que muchas personas los utilizaban con fines dañinos, como aprender a hacer cosas ilegales, como fabricar bombas, hacer trampa en las declaraciones de impuestos o robar un banco. Algunos también los utilizaban para generar textos incitadores al odio que luego se difundían en Internet.
En respuesta, los creadores de dichos sistemas comenzaron a agregar reglas a sus sistemas para evitar que proporcionaran respuestas a preguntas potencialmente peligrosas, ilegales o dañinas. En este nuevo estudio, los investigadores de AWS han descubierto que dichas salvaguardas no son lo suficientemente sólidas, ya que generalmente es bastante fácil eludirlas mediante simples señales de audio.
El trabajo del equipo implicó hacer jailbreak a varios LLM actualmente disponibles agregando audio durante el interrogatorio que les permitió eludir las restricciones impuestas por los creadores de los LLM. El equipo de investigación no enumera ejemplos específicos, por temor a que sean utilizados por personas que intenten subvertir los LLM, pero sí revelan que su trabajo implicó el uso de una técnica que llaman descenso de gradiente proyectado.
Como ejemplo indirecto, describen cómo utilizaron afirmaciones simples con un modelo, seguidas de repetir una consulta original. Al hacerlo, señalan, el modelo quedó en un estado en el que se ignoraban las restricciones.
Los investigadores informan que pudieron eludir diferentes LLM en diferentes grados según el nivel de acceso que tenían al modelo. También descubrieron que los éxitos que tenían con un modelo a menudo eran transferibles a otros.
El equipo de investigación concluye sugiriendo que los creadores de LLM podrían evitar que los usuarios eludan sus esquemas de protección agregando cosas como ruido aleatorio a la entrada de audio.
Más información:
Raghuveer Peri et al, SpeechGuard: Explorando la robustez adversa de los modelos multimodales de lenguaje grande, arXiv (2024). DOI: 10.48550/arxiv.2405.08317
© 2024 Red Ciencia X
Citación: Los investigadores encuentran que los LLM son fáciles de manipular para brindar información dañina (2024, 17 de mayo) recuperado el 19 de mayo de 2024 de https://techxplore.com/news/2024-05-llms-easy.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.


GIPHY App Key not set. Please check settings