. Crédito: arXiv (2023). DOI: 10.48550/arxiv.2302.01595")
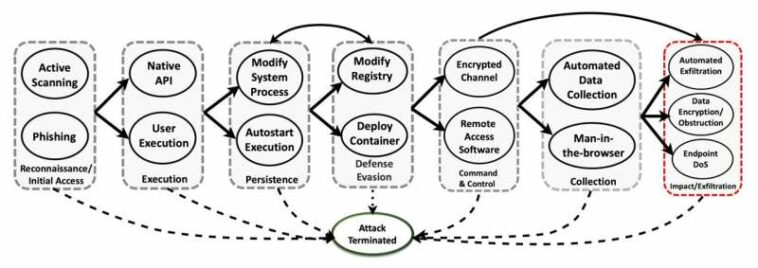
Propagación de ataques en varias etapas representada con las tácticas y técnicas MITRE ATT&CK. (Nota: un borde dirigido entre una táctica de ataque y una técnica especifica que el atacante puede intentar implementar esa técnica luego de lograr el objetivo de la táctica de ataque. La flecha bidireccional representa que la evasión de defensa puede venir antes que la persistencia). Crédito: arXiv (2023). DOI: 10.48550/arxiv.2302.01595
Los científicos han dado un paso clave para aprovechar una forma de inteligencia artificial conocida como aprendizaje de refuerzo profundo, o DRL, para proteger las redes informáticas.
Cuando se enfrentó a ataques cibernéticos sofisticados en un entorno de simulación riguroso, el aprendizaje de refuerzo profundo fue efectivo para evitar que los adversarios alcanzaran sus objetivos hasta el 95 por ciento de las veces. El resultado promete un papel para la IA autónoma en la ciberdefensa proactiva.
Los científicos del Laboratorio Nacional del Noroeste del Pacífico del Departamento de Energía documentaron sus hallazgos en un trabajo de investigación y presentaron su trabajo el 14 de febrero en un taller sobre IA para ciberseguridad durante la reunión anual de la Asociación para el Avance de la Inteligencia Artificial en Washington, DC
El punto de partida fue el desarrollo de un entorno de simulación para probar escenarios de ataque en varias etapas que involucran distintos tipos de adversarios. La creación de un entorno de simulación de ataque-defensa tan dinámico para la experimentación en sí misma es una victoria. El entorno ofrece a los investigadores una forma de comparar la eficacia de diferentes métodos defensivos basados en IA en entornos de prueba controlados.
Estas herramientas son esenciales para evaluar el rendimiento de los algoritmos de aprendizaje por refuerzo profundo. El método está emergiendo como una poderosa herramienta de apoyo a la toma de decisiones para expertos en seguridad cibernética: un agente de defensa con la capacidad de aprender, adaptarse a circunstancias que cambian rápidamente y tomar decisiones de manera autónoma. Mientras que otras formas de IA son estándar para detectar intrusiones o filtrar mensajes de spam, el aprendizaje de refuerzo profundo amplía las habilidades de los defensores para orquestar planes de toma de decisiones secuenciales en su enfrentamiento diario con los adversarios.
El aprendizaje por refuerzo profundo ofrece una ciberseguridad más inteligente, la capacidad de detectar antes los cambios en el panorama cibernético y la oportunidad de tomar medidas preventivas para frustrar un ciberataque.
DRL: Decisiones en un amplio espacio de ataque
«Un agente de IA eficaz para la ciberseguridad necesita sentir, percibir, actuar y adaptarse, en función de la información que puede recopilar y de los resultados de las decisiones que adopta», dijo Samrat Chatterjee, científico de datos que presentó el trabajo del equipo. «El aprendizaje de refuerzo profundo tiene un gran potencial en este espacio, donde la cantidad de estados del sistema y las opciones de acción pueden ser grandes».
DRL, que combina el aprendizaje por refuerzo y el aprendizaje profundo, es especialmente adecuado en situaciones en las que es necesario tomar una serie de decisiones en un entorno complejo. Las buenas decisiones que conducen a resultados deseables se refuerzan con una recompensa positiva (expresada como un valor numérico); Las malas decisiones que conducen a resultados indeseables se desalientan a través de un costo negativo.
Es similar a cómo la gente aprende muchas tareas. Un niño que hace sus tareas puede recibir un refuerzo positivo con una cita para jugar deseada; un niño que no hace su trabajo recibe un refuerzo negativo, como si le quitaran un dispositivo digital.
«Es el mismo concepto en el aprendizaje por refuerzo», dijo Chatterjee. «El agente puede elegir entre un conjunto de acciones. Con cada acción viene una retroalimentación, buena o mala, que se convierte en parte de su memoria. Existe una interacción entre explorar nuevas oportunidades y explotar experiencias pasadas. El objetivo es crear un agente que aprenda a tomar buenas decisiones.»
Abra AI Gym y MITRE ATT&CK
El equipo utilizó un conjunto de herramientas de software de código abierto conocido como Open AI Gym como base para crear un entorno de simulación personalizado y controlado para evaluar las fortalezas y debilidades de cuatro algoritmos de aprendizaje de refuerzo profundo.
El equipo utilizó el marco MITRE ATT&CK, desarrollado por MITRE Corp., e incorporó siete tácticas y 15 técnicas implementadas por tres adversarios distintos. Los defensores estaban equipados con 23 acciones de mitigación para tratar de detener o prevenir la progresión de un ataque.
Las etapas del ataque incluyeron tácticas de reconocimiento, ejecución, persistencia, evasión de defensa, comando y control, recopilación y exfiltración (cuando los datos se transfieren fuera del sistema). Un ataque se registró como una victoria para el adversario si alcanzaba con éxito la etapa final de exfiltración.
«Nuestros algoritmos operan en un entorno competitivo: una competencia con la intención del adversario de violar el sistema», dijo Chatterjee. «Es un ataque de varias etapas, donde el adversario puede seguir múltiples rutas de ataque que pueden cambiar con el tiempo a medida que intentan pasar del reconocimiento a la explotación. Nuestro desafío es mostrar cómo las defensas basadas en el aprendizaje de refuerzo profundo pueden detener un ataque de este tipo».
DQN supera a otros enfoques
El equipo entrenó agentes defensivos en base a cuatro algoritmos de aprendizaje de refuerzo profundo: DQN (Deep Q-Network) y tres variaciones de lo que se conoce como el enfoque actor-crítico. Los agentes fueron entrenados con datos simulados sobre ciberataques, luego probados contra ataques que no habían observado en el entrenamiento.
DQN se desempeñó mejor.
- Ataques menos sofisticados (basados en diferentes niveles de habilidad y persistencia del adversario): DQN detuvo el 79 por ciento de los ataques a la mitad de las etapas de ataque y el 93 por ciento en la etapa final.
- Ataques moderadamente sofisticados: DQN detuvo el 82 % de los ataques a la mitad y el 95 % en la etapa final.
- Ataques más sofisticados: DQN detuvo el 57 % de los ataques a mitad de camino y el 84 % en la etapa final, mucho más que los otros tres algoritmos.
“Nuestro objetivo es crear un agente de defensa autónomo que pueda aprender cuál es el próximo paso más probable de un adversario, planificarlo y luego responder de la mejor manera para proteger el sistema”, dijo Chatterjee.
A pesar del progreso, nadie está listo para confiar la ciberdefensa por completo a un sistema de IA. En cambio, un sistema de seguridad cibernética basado en DRL necesitaría trabajar en conjunto con los humanos, dijo el coautor Arnab Bhattacharya, ex PNNL.
«La IA puede ser buena para defenderse de una estrategia específica, pero no es tan buena para comprender todos los enfoques que podría adoptar un adversario», dijo Bhattacharya. «No estamos ni cerca de la etapa en la que la IA pueda reemplazar a los analistas cibernéticos humanos. La retroalimentación y la orientación humanas son importantes».
La investigación se publica en el arXiv servidor de preimpresión.
Más información:
Ashutosh Dutta et al, Aprendizaje de refuerzo profundo para la defensa del sistema cibernético bajo incertidumbres antagónicas dinámicas, arXiv (2023). DOI: 10.48550/arxiv.2302.01595
Citación: Los defensores de la ciberseguridad están ampliando su caja de herramientas de IA (2023, 16 de febrero) consultado el 16 de febrero de 2023 en https://techxplore.com/news/2023-02-cybersecurity-defenders-ai-toolbox.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.