
|
Los modelos de aprendizaje profundo (DL) han aumentado en tamaño y complejidad en los últimos años, lo que ha llevado el tiempo de capacitación de días a semanas. Entrenamiento de grandes modelos de lenguaje del tamaño de GPT-3 puede tomar meses, lo que lleva a un crecimiento exponencial en el costo de la capacitación. Para reducir los tiempos de capacitación del modelo y permitir que los profesionales del aprendizaje automático (ML) iteren rápidamente, AWS ha estado innovando en chips, servidores y conectividad del centro de datos.
En AWS re:Invent 2021, anunciamos la versión preliminar de las instancias Amazon EC2 Trn1 con tecnología de chips Trainium de AWS. AWS Trainium está optimizado para la formación de aprendizaje profundo de alto rendimiento y es el chip de aprendizaje automático de segunda generación creado por AWS, siguiendo a AWS Inferentia.
Hoy, me complace anunciar que las instancias Amazon EC2 Trn1 ahora están disponibles para el público en general. Estas instancias son adecuadas para el entrenamiento distribuido a gran escala de modelos DL complejos en un amplio conjunto de aplicaciones, como procesamiento de lenguaje natural, reconocimiento de imágenes y más.
En comparación con las instancias P4d de Amazon EC2, las instancias Trn1 ofrecen 1,4 veces más teraFLOPS para tipos de datos BF16, 2,5 veces más teraFLOPS para tipos de datos TF32, 5 veces más teraFLOPS para tipos de datos FP32, 4 veces más ancho de banda entre nodos y hasta un 50 % de costo- para entrenar ahorros. Las instancias Trn1 se pueden implementar en EC2 UltraClusters que funcionan como poderosas supercomputadoras para entrenar rápidamente modelos complejos de aprendizaje profundo. Compartiré más detalles sobre EC2 UltraClusters más adelante en esta publicación de blog.
Aspectos destacados de la nueva instancia Trn1
Las instancias Trn1 están disponibles hoy en dos tamaños y funcionan con hasta 16 chips AWS Trainium con 128 vCPU. Proporcionan redes y almacenamiento de alto rendimiento para admitir datos eficientes y paralelismo de modelos, estrategias populares para el entrenamiento distribuido.
Las instancias Trn1 ofrecen hasta 512 GB de memoria de alto ancho de banda, brindan hasta 3,4 petaFLOPS de potencia de cómputo TF32/FP16/BF16 y cuentan con una interconexión NeuronLink de ultra alta velocidad entre chips. NeuronLink ayuda a evitar cuellos de botella en la comunicación al escalar cargas de trabajo en múltiples chips Trainium.
Las instancias Trn1 también son las primeras instancias EC2 que permiten hasta 800 Gbps de ancho de banda de red del adaptador de tejido elástico (EFA) para comunicaciones de red de alto rendimiento. Este EFA de segunda generación ofrece una latencia más baja y hasta 2 veces más ancho de banda de red en comparación con la generación anterior. Las instancias Trn1 también vienen con hasta 8 TB de almacenamiento SSD NVMe local para un acceso ultrarrápido a grandes conjuntos de datos.
La siguiente tabla enumera los tamaños y especificaciones de las instancias Trn1 en detalle.
| Nombre de instancia |
vCPU | Chips de tren de AWS | Memoria del acelerador | NeuronLink | Memoria de instancia | Redes de instancias | Almacenamiento de instancias locales |
| trn1.2xgrande | 8 | 1 | 32 GB | N / A | 32 GB | Hasta 12,5 Gbps | 1x 500 GB NVMe |
| trn1.32xgrande | 128 | dieciséis | 512GB | Soportado | 512GB | 800 Gbps | 4x 2TB NVMe |
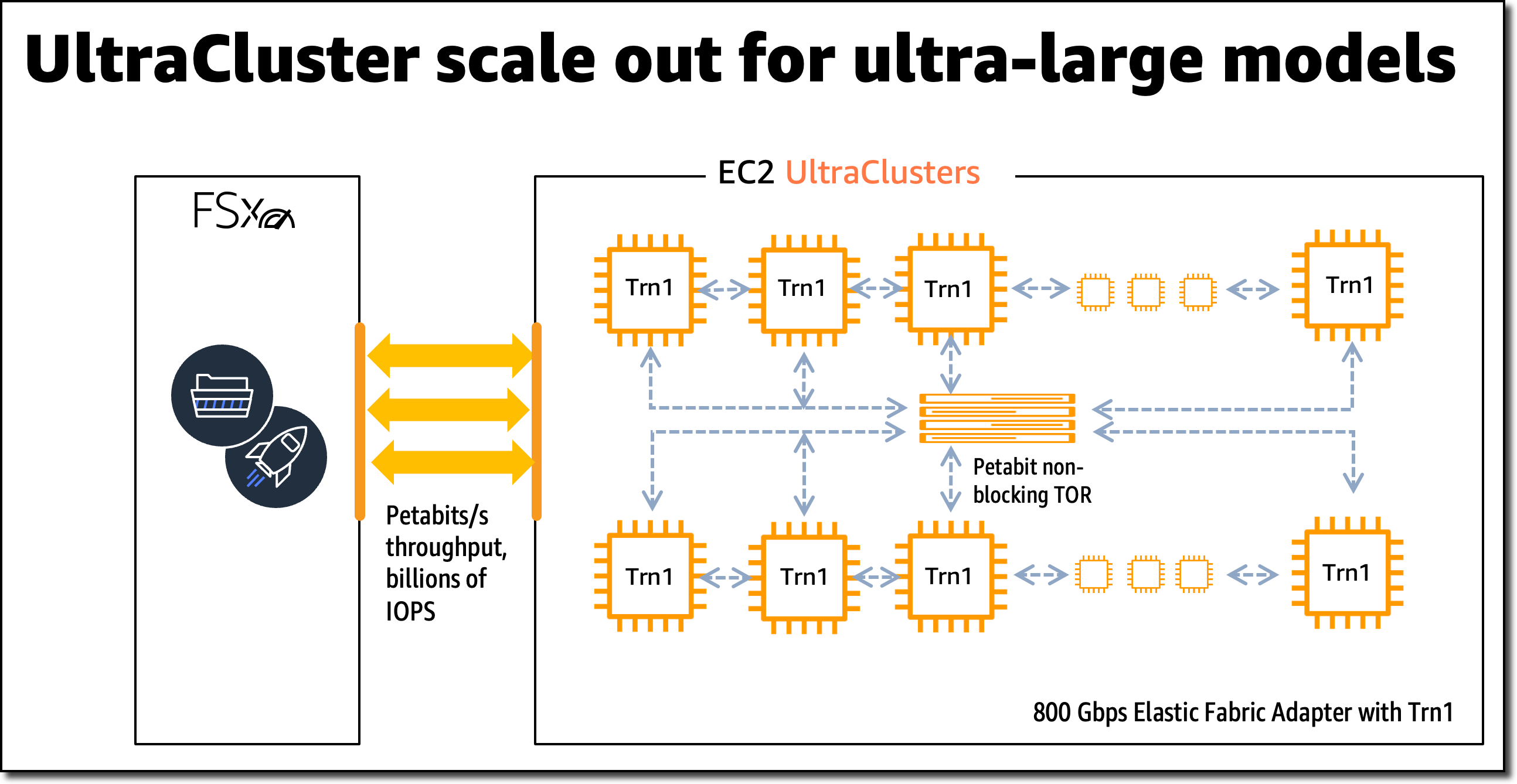
Trn1 EC2 UltraClusters
Para el entrenamiento de modelos a gran escala, las instancias Trn1 se integran con Amazon FSx para el almacenamiento de alto rendimiento Lustre y se implementan en EC2 UltraClusters. EC2 UltraClusters son clústeres de hiperescala interconectados con una red a escala de petabit sin bloqueo. Esto le brinda acceso a pedido a una supercomputadora para reducir el tiempo de entrenamiento de modelos grandes y complejos de meses a semanas o incluso días.
Innovación de Trainium de AWS
Los chips de AWS Trainium incluyen motores escalares, vectoriales y tensoriales específicos que están diseñados específicamente para algoritmos de aprendizaje profundo. Esto garantiza una mayor utilización del chip en comparación con otras arquitecturas, lo que se traduce en un mayor rendimiento.
Aquí hay un breve resumen de las innovaciones de hardware adicionales:
- Tipos de datos: AWS Trainium admite una amplia gama de tipos de datos, incluidos FP32, TF32, BF16, FP16 y UINT8, por lo que puede elegir el tipo de datos más adecuado para sus cargas de trabajo. También es compatible con un nuevo tipo de datos FP8 (cFP8) configurable, que es especialmente relevante para modelos grandes porque reduce la huella de memoria y los requisitos de E/S del modelo.
- Redondeo estocástico optimizado por hardware: El redondeo estocástico logra una precisión cercana al nivel FP32 con un rendimiento de nivel BF16 más rápido cuando habilita la conversión automática de tipos de datos FP32 a BF16. El redondeo estocástico es una forma diferente de redondear números de punto flotante, que es más adecuada para cargas de trabajo de aprendizaje automático en comparación con el redondeo Round Nearest Even comúnmente utilizado. Al establecer la variable de entorno
NEURON_RT_STOCHASTIC_ROUNDING_EN=1Para usar el redondeo estocástico, puede entrenar un modelo hasta un 30 por ciento más rápido. - Operadores personalizados, formas de tensor dinámico: AWS Trainium también admite operadores personalizados escritos en C++ y formas de tensor dinámico. Las formas de tensor dinámico son clave para los modelos con tamaños de tensor de entrada desconocidos, como los modelos que procesan texto.
AWS Trainium comparte el mismo SDK de AWS Neuron® como AWS Inferentia, lo que facilita que todos los que ya usan AWS Inferentia comiencen a usar AWS Trainium.
Para el entrenamiento de modelos, Neuron SDK consta de un compilador, extensiones de marco, una biblioteca de tiempo de ejecución y herramientas para desarrolladores. El complemento Neuron se integra de forma nativa con marcos de ML populares, como PyTorch y TensorFlow.
El SDK de AWS Neuron admite la compilación justo a tiempo (JIT), además de la compilación anticipada (AOT), para acelerar la compilación del modelo, y el modo de depuración ansiosa, para una ejecución paso a paso.
Para compilar y ejecutar su modelo en AWS Trainium, necesita cambiar solo unas pocas líneas de código en su script de entrenamiento. No necesita modificar su modelo ni pensar en la conversión de tipos de datos.
Comience con las instancias Trn1
En este ejemplo, entreno un modelo PyTorch en una instancia EC2 Trn1 usando los paquetes PyTorch Neuron disponibles. PyTorch Neuron se basa en el Paquete de software PyTorch XLA y permite la conversión de operaciones de PyTorch a instrucciones de AWS Trainium.
Cada chip AWS Trainium incluye dos aceleradores NeuronCore, que son las principales unidades informáticas de la red neuronal. Con solo unos pocos cambios en su código de entrenamiento, puede entrenar su modelo PyTorch en AWS Trainium NeuronCores.
SSH en la instancia Trn1 y active un entorno virtual de Python que incluye los paquetes PyTorch Neuron. Si utiliza una AMI proporcionada por Neuron, puede activar el entorno preinstalado ejecutando el siguiente comando:
source aws_neuron_venv_pytorch_p36/bin/activateAntes de que pueda ejecutar su script de entrenamiento, debe hacer algunas modificaciones. En las instancias Trn1, el dispositivo XLA predeterminado debe asignarse a un NeuronCore.
Comencemos agregando las importaciones de PyTorch XLA a su script de entrenamiento:
import torch, torch_xla
import torch_xla.core.xla_model as xmLuego, coloque su modelo y tensores en un dispositivo XLA:
model.to(xm.xla_device())
tensor.to(xm.xla_device())Cuando el modelo se mueve al dispositivo XLA (NeuronCore), las operaciones posteriores en el modelo se registran para su posterior ejecución. Esta es la ejecución perezosa de XLA, que es diferente de la ejecución ansiosa de PyTorch. Dentro del ciclo de entrenamiento, debe marcar el gráfico para optimizarlo y ejecutarlo en el dispositivo XLA usando xm.mark_step(). Sin esta marca, XLA no puede determinar dónde termina el gráfico.
...
for data, target in train_loader:
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
xm.mark_step()
...Ahora puede ejecutar su script de entrenamiento usando torchrun <my_training_script>.py.
Al ejecutar el script de entrenamiento, puede configurar la cantidad de NeuronCores que se usarán para el entrenamiento usando torchrun –nproc_per_node.
Por ejemplo, para ejecutar un entrenamiento de modelo paralelo de datos de varios trabajadores en los 32 NeuronCores en una instancia trn1.32xlarge, ejecute torchrun --nproc_per_node=32 <my_training_script>.py.
El paralelo de datos es una estrategia para el entrenamiento distribuido que le permite replicar su secuencia de comandos entre varios trabajadores, y cada trabajador procesa una parte del conjunto de datos de entrenamiento. Los trabajadores luego comparten su resultado entre ellos.
Para obtener más detalles sobre los marcos de ML admitidos, los tipos de modelos y cómo preparar su secuencia de comandos de entrenamiento de modelos para el entrenamiento distribuido a gran escala en instancias trn1.32xlarge, eche un vistazo a la documentación del SDK de AWS Neuron.
Herramientas de perfilado
Echemos un vistazo rápido a las herramientas útiles para realizar un seguimiento de sus experimentos de ML y perfilar el consumo de recursos de la instancia Trn1. Neurona se integra con TensorTablero para rastrear y visualizar las métricas de entrenamiento de su modelo.
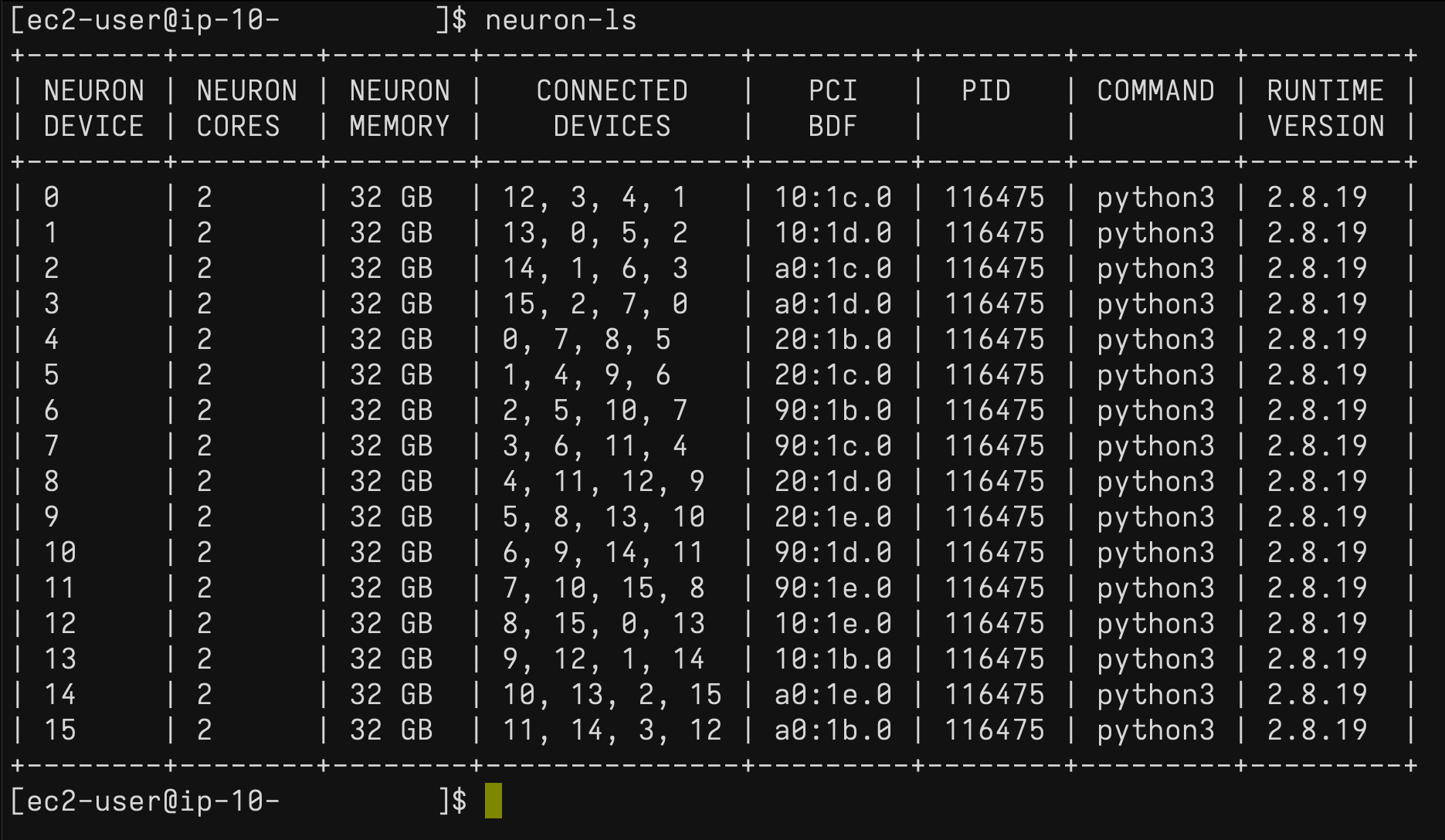
En la instancia Trn1, puede usar el neuron-ls Comando para describir la cantidad de dispositivos Neuron presentes en el sistema, junto con el recuento de NeuronCore asociado, la memoria, la conectividad/topología, la información del dispositivo PCI y el proceso de Python que actualmente tiene la propiedad de los NeuronCores:
Del mismo modo, puede utilizar el neuron-top Comando para ver una vista de alto nivel del entorno Neuron. Esto muestra la utilización de cada uno de los NeuronCores, cualquier modelo que esté actualmente cargado en uno o más NeuronCores, los ID de proceso para cualquier proceso que esté usando el tiempo de ejecución de Neuron y las estadísticas básicas del sistema relacionadas con el uso de memoria y vCPU.

Disponible ahora
Puede lanzar instancias Trn1 hoy en las regiones de AWS EE. UU. Este (Norte de Virginia) y EE. UU. Oeste (Oregón) como instancias bajo demanda, reservadas y puntuales o como parte de un plan de ahorro. Como es habitual con Amazon EC2, solo paga por lo que usa. Para obtener más información, consulte Precios de Amazon EC2.
Las instancias Trn1 se pueden implementar mediante AMI de aprendizaje profundo de AWS, y las imágenes de contenedores están disponibles a través de servicios administrados como Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS) y AWS ParallelCluster.
Para obtener más información, visite nuestra página de instancias Amazon EC2 Trn1 y envíe sus comentarios a AWS re: publicar para EC2 o a través de sus contactos habituales de AWS Support.
— Antje

