
Crédito: Pu et al.
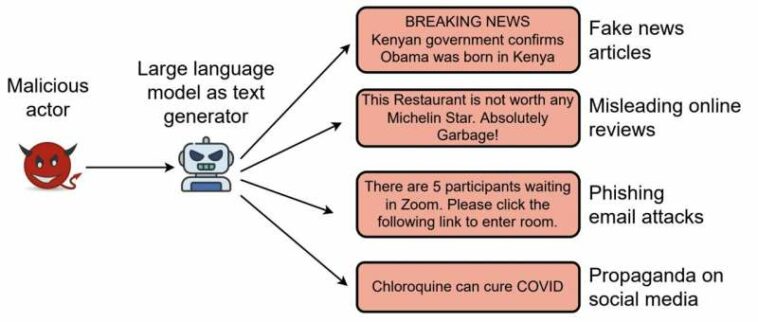
Los avances en el campo del aprendizaje automático han permitido recientemente el desarrollo de herramientas informáticas que pueden crear textos convincentes pero producidos artificialmente, también conocidos como textos falsos profundos. Si bien la creación automática de textos podría tener algunas aplicaciones interesantes, también plantea serias preocupaciones en términos de seguridad y desinformación.
En última instancia, los textos producidos sintéticamente también podrían usarse para engañar a los usuarios de Internet, por ejemplo, a través de la generación a gran escala de extremistas o textos violentos destinados a radicalizar a las personas, noticias falsas para campañas de desinformación, mensajes de correo electrónico para ataques de phishing o reseñas falsas dirigidas a hoteles específicos. locales o restaurantes. En conjunto, esto podría reducir aún más la confianza de algunos usuarios en el contenido en línea, al tiempo que incita a otros usuarios a participar en comportamientos antisociales y de riesgo.
Un estudio reciente dirigido por investigadores de Virginia Tech, en colaboración con investigadores de la Universidad de Chicago, LUMS Pakistan y la Universidad de Virginia, exploró recientemente las limitaciones y fortalezas de los enfoques existentes para detectar textos falsos profundos. Su artículo, con los estudiantes Jiameng Pu y Zain Sarwar como autores principales, se presentará en IEEE S&P’23, una conferencia centrada en la seguridad informática.
«Gran parte de la investigación de seguridad que realizamos antes de 2016 asumió un atacante algorítmicamente débil. Esta suposición ya no es válida debido a los avances realizados en IA y ML. Tenemos que considerar adversarios algorítmicamente inteligentes o basados en ML. Esto nos llevó a comenzar a explorar este espacio En 2017, publicamos un artículo que explora cómo los modelos de lenguaje (LM) como RNN pueden usarse indebidamente para generar reseñas falsas en plataformas como Yelp «, dijo a TechXplore Bimal Viswanath, investigador de Virginia Tech que dirigió el estudio.
«Esta fue nuestra primera incursión en este espacio. Desde entonces, observamos rápidos avances en las tecnologías de LM, especialmente después del lanzamiento de la familia de modelos Transformer. Estos avances aumentan la amenaza del mal uso de tales herramientas para permitir que se propaguen campañas a gran escala. desinformación, generar spam de opinión y contenido abusivo, y técnicas de phishing más efectivas».
En los últimos años, muchos científicos informáticos de todo el mundo han intentado desarrollar modelos computacionales que puedan detectar con precisión texto sintético generado por LM avanzados. Esto condujo a la introducción de numerosas estrategias defensivas diferentes; incluidos algunos que buscan artefactos específicos en textos sintéticos y otros que se basan en el uso de modelos de lenguaje previamente entrenados para construir detectores.
«Si bien estas defensas reportaron altas precisiones de detección, aún no estaba claro qué tan bien funcionarían en la práctica, en entornos adversarios», explicó Viswanath. «Las defensas existentes se probaron en conjuntos de datos creados por los propios investigadores, en lugar de datos sintéticos en la naturaleza. En la práctica, los atacantes se adaptarían a estas defensas para evadir la detección, y los trabajos existentes no consideraron tales configuraciones adversas».
Las defensas que los usuarios malintencionados pueden superar fácilmente cambiando ligeramente el diseño de sus modelos de lenguaje son, en última instancia, ineficaces en el mundo real. Por lo tanto, Viswanath y sus colegas se propusieron explorar las limitaciones, las fortalezas y el valor real de algunos de los modelos de detección de texto falso profundo más prometedores creados hasta el momento.
Su artículo se centró en 6 esquemas de detección de texto sintético existentes introducidos en los últimos años, todos los cuales habían alcanzado un rendimiento notable en las evaluaciones iniciales, con precisiones de detección que oscilaban entre el 79,6 % y el 98,5 %. Los modelos que evaluaron son BERT-Defense, GLTR-GPT2, GLTR-BERT, GROVER, FAST y RoBERTa-Defense.
«Agradecemos a los desarrolladores de estos modelos por compartir código y datos con nosotros, ya que esto nos permitió reproducirlos con precisión», dijo Viswanath. «Nuestro primer objetivo era evaluar de forma fiable el rendimiento de estas defensas en conjuntos de datos del mundo real. Para ello, preparamos 4 nuevos conjuntos de datos sintéticos, que ahora lanzamos a la comunidad».
Para compilar sus conjuntos de datos, Viswanath y sus colegas recopilaron miles de artículos de texto sintético creados por diferentes plataformas de generación de texto como servicio, así como publicaciones falsas de Reddit creadas por bots. Las plataformas de generación de texto como servicio son sitios de Internet impulsados por IA que permiten a los usuarios simplemente crear texto sintético y que pueden usarse indebidamente para crear contenido engañoso.
Crédito: Pu et al.
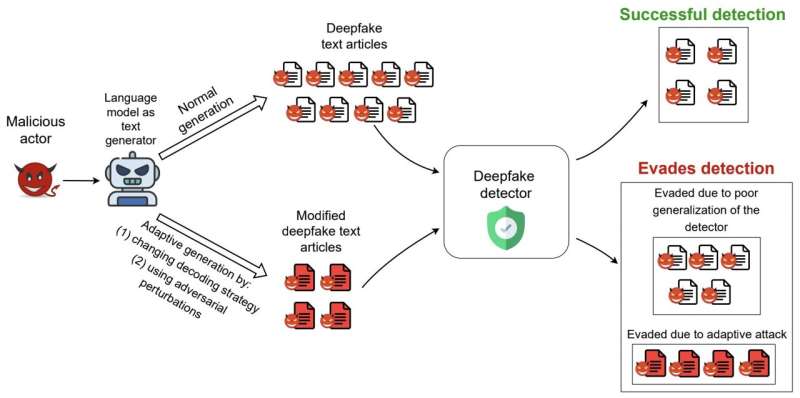
Para evaluar de forma fiable el rendimiento de los seis modelos de defensa que seleccionaron en la detección de textos falsos profundos, los investigadores propusieron una serie de estrategias de evasión de «bajo coste» que solo requieren cambios en el generador de texto basado en LM en el momento de la inferencia. Básicamente, esto significa que el LM que genera el texto falso se puede adaptar o mejorar durante las pruebas, sin necesidad de capacitación adicional.
«También propusimos una nueva estrategia de evasión, llamada DFTFooler, que puede perturbar o modificar automáticamente cualquier artículo de texto sintético para evadir la detección, al tiempo que conserva la semántica», dijo Viswanath. «DFTFooler utiliza LM disponibles públicamente y aprovecha los conocimientos exclusivos del problema de detección de texto sintético. A diferencia de otros esquemas de perturbación adversarios, DFTFooler no requiere ningún acceso de consulta al clasificador de defensa de víctimas para crear muestras evasivas, lo que lo convierte en una herramienta de ataque más sigilosa y práctica. .»
Las evaluaciones del equipo arrojaron varios resultados interesantes. En primer lugar, los investigadores descubrieron que el rendimiento de tres de los seis modelos de defensa que evaluaron disminuyó significativamente cuando se probaron en conjuntos de datos del mundo real, con caídas del 18 % al 99 % en su precisión. Esto destaca la necesidad de mejorar estos modelos para garantizar que se generalicen bien en diferentes datos.
Además, Viswanath y sus colegas encontraron que cambiar la estrategia de decodificación de texto de un LM (es decir, muestreo de texto) a menudo rompía muchas de las defensas. Esta estrategia simple no requiere ningún modelo adicional de reentrenamiento, ya que solo modifica los parámetros de generación de texto existentes de un LM y, por lo tanto, es muy fácil de aplicar para los atacantes.
«También descubrimos que nuestra nueva estrategia de manipulación de texto adversaria llamada DFTFooler puede crear con éxito muestras evasivas sin requerir ninguna consulta al clasificador del defensor», dijo Viswanath. «Entre las seis defensas que evaluamos, encontramos que una defensa llamada FAST es más resistente en estos entornos adversarios, en comparación con las otras defensas. Desafortunadamente, FAST tiene una tubería compleja que utiliza múltiples técnicas avanzadas de PNL, lo que dificulta la comprensión de su mejor presentación.»
Para obtener más información sobre las cualidades que hacen que el modelo FAST sea particularmente resistente y confiable para detectar textos falsos, los investigadores realizaron un análisis en profundidad de sus características. Descubrieron que la resiliencia del modelo se debe a su uso de características semánticas extraídas de los artículos.
En contraste con los otros modelos de defensa evaluados en este estudio, FAST analiza las características semánticas de un texto, observando las entidades nombradas y las relaciones entre estas entidades en el texto. Esta cualidad única pareció mejorar significativamente el rendimiento del modelo en conjuntos de datos falsos profundos del mundo real.
Inspirándose en estos hallazgos, Viswanath y sus colegas crearon DistilFAST, una versión simplificada de FAST que solo analiza características semánticas. Descubrieron que este modelo superó al modelo FAST original en entornos adversarios.
«Nuestro trabajo destaca el potencial de las características semánticas para permitir esquemas de detección sintética resistentes a los adversarios», dijo Viswanath. «Aunque FAST parece prometedor, todavía hay mucho margen de mejora. La generación de artículos de texto extensos semánticamente consistentes sigue siendo un problema desafiante para los LM. Por lo tanto, las diferencias en la representación de la información semántica en artículos sintéticos y reales pueden explotarse para construir defensas sólidas .»
Al intentar eludir los detectores de texto falso, es posible que los atacantes no siempre puedan cambiar el contenido semántico de los textos sintéticos, especialmente cuando estos textos están diseñados para transmitir ideas específicas. En el futuro, los hallazgos recopilados por este equipo de investigadores y el modelo FAST simplificado que crearon podrían ayudar a fortalecer las defensas contra los textos sintéticos en línea, lo que podría limitar las campañas de desinformación o radicalización a gran escala.
«Actualmente, esta dirección no ha sido investigada en la comunidad de seguridad», agregó Viswanath. «En nuestro trabajo futuro, planeamos aprovechar los gráficos de conocimiento para extraer características semánticas más ricas, con la esperanza de producir defensas más robustas y de mayor rendimiento».
Jiameng Pu et al, Detección de texto falso profundo: limitaciones y oportunidades, arXiv (2022). DOI: 10.48550/arxiv.2210.09421
Yuanshun Yao et al, Ataques y defensas automatizados de crowdturfing en sistemas de revisión en línea, Actas de la Conferencia ACM SIGSAC 2017 sobre seguridad informática y de las comunicaciones (2017). DOI: 10.1145/3133956.3133990
© 2022 Ciencia X Red
Citación: Las fortalezas y limitaciones de los enfoques para detectar texto falso profundo (21 de noviembre de 2022) recuperado el 21 de noviembre de 2022 de https://techxplore.com/news/2022-11-strengths-limitations-approaches-deepfake-text.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.

