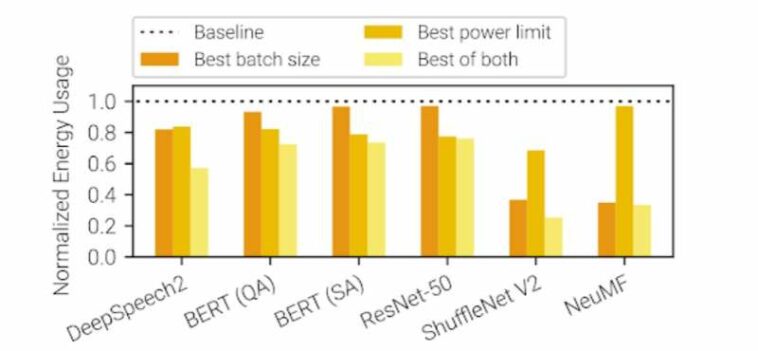

La optimización podría reducir la huella de carbono del entrenamiento de IA entre un 15 y un 75 %. Una variedad de modelos comunes de aprendizaje profundo se benefician de la capacidad de Zeus para ajustar los límites de potencia de la GPU y el tamaño del lote de entrenamiento. Cuando se ajustaron ambos parámetros, el software logró una reducción de energía de hasta un 75 %. Crédito: SymbioticLab, Universidad de Michigan
Una nueva forma de optimizar el entrenamiento de modelos de aprendizaje profundo, una herramienta en rápida evolución para impulsar la inteligencia artificial, podría reducir drásticamente las demandas de energía de la IA.
Desarrollado en la Universidad de Michigan, el marco de optimización de código abierto estudia modelos de aprendizaje profundo durante el entrenamiento, identificando la mejor compensación entre el consumo de energía y la velocidad del entrenamiento.
«A escalas extremas, entrenar el modelo GPT-3 solo una vez consume 1287 MWh, que es suficiente para abastecer a un hogar estadounidense promedio durante 120 años», dijo Mosharaf Chowdhury, profesor asociado de ingeniería eléctrica e informática.
Con Zeus, el nuevo marco de optimización de energía desarrollado por Chowdhury y su equipo, cifras como esta podrían reducirse hasta en un 75 % sin ningún hardware nuevo, y con impactos mínimos en el tiempo que lleva entrenar un modelo. Se presentó en el Simposio USENIX de 2023 sobre diseño e implementación de sistemas en red (NSDI), en Boston.
Los usos convencionales de modelos pesados de aprendizaje profundo se han disparado en los últimos tres años, desde modelos de generación de imágenes y chatbots expresivos hasta los sistemas de recomendación que impulsan a TikTok y Amazon. Dado que la computación en la nube ya supera en emisiones a la aviación comercial, la mayor carga climática de la inteligencia artificial es una preocupación importante.
«El trabajo existente se centra principalmente en optimizar la capacitación de aprendizaje profundo para una finalización más rápida, a menudo sin considerar el impacto en la eficiencia energética», dijo Jae-Won Chung, estudiante de doctorado en informática e ingeniería y coautor del estudio. «Descubrimos que la energía que invertimos en las GPU está dando rendimientos decrecientes, lo que nos permite reducir significativamente el consumo de energía, con una ralentización relativamente pequeña».
El aprendizaje profundo es una familia de técnicas que utilizan redes neuronales artificiales de varias capas para abordar una variedad de tareas comunes de aprendizaje automático. Estas también se conocen como redes neuronales profundas (DNN). Los modelos en sí son extremadamente complejos y aprenden de algunos de los conjuntos de datos más masivos jamás utilizados en el aprendizaje automático. Debido a esto, se benefician enormemente de las capacidades multitarea de las unidades de procesamiento gráfico (GPU), que consumen el 70 % de la energía que se utiliza para entrenar uno de estos modelos.
Zeus utiliza dos perillas de software para reducir el consumo de energía. Uno es el límite de potencia de la GPU, que reduce el uso de energía de la GPU y ralentiza el entrenamiento del modelo hasta que se vuelve a ajustar la configuración. El otro es el parámetro de tamaño de lote del modelo de aprendizaje profundo, que controla cuántas muestras de los datos de entrenamiento trabaja el modelo antes de actualizar la forma en que el modelo representa las relaciones que encuentra en los datos. Los tamaños de lote más altos reducen el tiempo de capacitación, pero con un mayor consumo de energía.
Zeus puede ajustar cada una de estas configuraciones en tiempo real, buscando el punto de equilibrio óptimo en el que se minimiza el uso de energía con el menor impacto posible en el tiempo de entrenamiento. En ejemplos, el equipo pudo demostrar visualmente este punto de compensación al mostrar todas las combinaciones posibles de estos dos parámetros. Si bien ese nivel de minuciosidad no ocurrirá en la práctica con un trabajo de capacitación en particular, Zeus aprovechará la naturaleza repetitiva del aprendizaje automático para acercarse mucho.
«Afortunadamente, las empresas entrenan el mismo DNN una y otra vez con datos más nuevos, cada hora. Podemos aprender sobre cómo se comporta el DNN al observar esas recurrencias», dijo Jie You, un recién graduado de doctorado en informática e ingeniería. y coautor principal del estudio.
Zeus es el primer marco diseñado para conectarse a los flujos de trabajo existentes para una variedad de GPU y tareas de aprendizaje automático, lo que reduce el consumo de energía sin requerir ningún cambio en el hardware del sistema o la infraestructura del centro de datos.
Además, el equipo ha desarrollado un software complementario que se superpone a Zeus para reducir aún más la huella de carbono. Este software, llamado Chase, privilegia la velocidad cuando hay disponible energía baja en carbono y elige la eficiencia a expensas de la velocidad durante las horas pico, que es más probable que requieran aumentar la generación de energía intensiva en carbono, como el carbón. Chase obtuvo el segundo lugar en el hackathon CarbonHack del año pasado y se presentará el 4 de mayo en el Taller de la Conferencia Internacional sobre Representaciones de Aprendizaje.
«No siempre es posible migrar fácilmente los trabajos de capacitación de DNN a otras ubicaciones debido al gran tamaño de los conjuntos de datos o las regulaciones de datos», dijo Zhenning Yang, estudiante de maestría en informática e ingeniería. «Diferir los trabajos de capacitación a plazos más ecológicos tampoco puede ser una opción, ya que las DNN deben capacitarse con los datos más actualizados e implementarse rápidamente en producción para lograr la mayor precisión.
«Nuestro objetivo es diseñar e implementar soluciones que no entren en conflicto con estas limitaciones realistas, al mismo tiempo que reducimos la huella de carbono de la capacitación de DNN».
Citación: La optimización podría reducir la huella de carbono del entrenamiento de IA hasta en un 75 % (17 de abril de 2023) consultado el 17 de abril de 2023 en https://techxplore.com/news/2023-04-optimization-carbon-footprint-ai.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.
