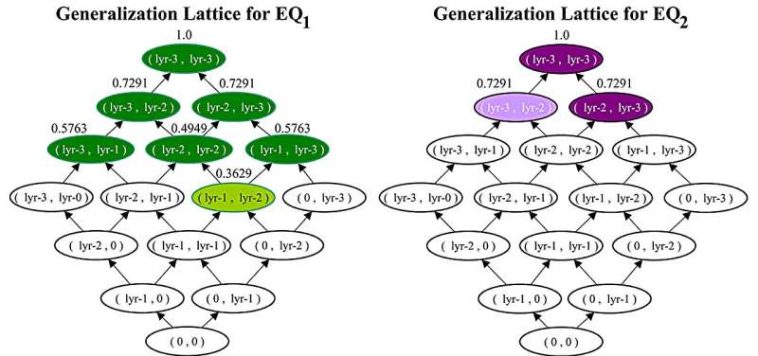
 que son anónimos para formar las clases de equivalencia 𝐸𝑄1 y 𝐸𝑄2. Crédito: arXiv (2025). DOI: 10.48550/arxiv.2509.03350")
De izquierda a derecha, mostramos cómo ARX-LR procesa el conjunto de datos original para iterar sobre la red de generalización, identificando los estados (coloreados) que son anónimos para formar las clases de equivalencia 𝐸𝑄1 y 𝐸𝑄2. Crédito: arXiv (2025). DOI: 10.48550/arxiv.2509.03350
Un equipo de profesores y estudiantes de la Universidad George Mason descubrió recientemente una vulnerabilidad en una herramienta de anonimización ampliamente utilizada. Presentaron sus hallazgos la semana pasada en Taiwán en la Conferencia de la Asociación de Maquinaria de Computación sobre Seguridad de Computadoras y Comunicaciones (ACM CCS 2025). el papel es disponible en el arXiv servidor de preimpresión.
El problema que descubrieron fue con ARX, una herramienta de anonimización de datos de código abierto, que proporciona lo que se conoce como k-anonimato. Es una herramienta comúnmente utilizada en entornos clínicos para mantener la privacidad de los datos. El descubrimiento es particularmente importante en un momento en el que cada vez se utilizan más datos privados en una variedad de entornos y sistemas.
Evgenios Kornaropoulos, profesor asistente en el Departamento de Ciencias de la Computación, dijo: «A veces este tipo de microdatos es muy valioso. Herramientas como ARX anonimizan los datos para que cumplan con HIPAA, y luego esos datos se pueden compartir con formuladores de políticas, ingenieros, científicos y otros que tomarán decisiones políticas y estudios científicos basados en esta información».
Si bien muchas personas que reciben atención médica se sienten cómodas con que su información se incluya en conjuntos de datos más grandes con fines de descubrimiento médico, es probable que no quieran que se divulgue información personal identificable.
Rebecca Sutter, coautora del artículo, profesora de Enfermería y directora de MAP Clinics, dijo: «Para los pacientes, y especialmente aquellos de comunidades más vulnerables o marginadas, la privacidad de los datos no es una preocupación abstracta, sino que está profundamente ligada a la confianza en el sistema de atención médica. La integridad de herramientas como ARX es importante porque sustentan la forma en que protegemos la información de los pacientes mientras avanzamos en la investigación de salud pública. Cuando falla la anonimización, no es solo una cuestión técnica vulnerabilidad, es humana.»
Somiya Chhillar, Ph.D. estudiante de informática y autor principal del artículo, dijo que la ubicuidad de ARX fue una de las razones por las que eligieron estudiarlo. «Queríamos ver cómo funciona realmente ARX y cómo funciona el algoritmo. Mientras lo hacíamos, nos dimos cuenta de que algunos de los pasos que toma son muy oportunistas y, debido a eso, filtra información que no deberíamos descubrir con solo mirar los datos anonimizados».
Chhillar dijo que ARX sigue una «estrategia codiciosa» y explicó que existe una tensión entre privacidad y utilidad. Cuando se comparten datos, deberían ser útiles sin filtrar información. La mejor métrica para decidir la utilidad de los datos se mide por la pérdida de información mientras los datos se hacen privados.
«El algoritmo intenta minimizar la pérdida de información mientras anonimiza los datos, e idealmente, queremos la menor pérdida de información posible. Y ese es el aspecto codicioso; no siempre se busca lo más privado, solo se busca la mayor utilidad».
Esto es lo que resulta contraproducente, dijo Kornaropoulos, porque los expertos (o atacantes) pueden aplicar ingeniería inversa a los pasos de anonimización que tomó el algoritmo durante su ejecución para maximizar la utilidad y descubrir las propiedades de los datos que estaban allí antes y después de este paso de anonimización.
Kornaropoulos elogió la dedicación de su estudiante al descubrimiento, señalando que Chhillar «trabajó en este proyecto por un tiempo, y esta base de código de ARX es una herramienta elaborada, con miles de líneas de código. Tuvo que revisarla para interiorizar verdaderamente y comprender todo lo que está sucediendo allí», dijo.
Más información:
Somiya Chhillar et al, Exponiendo los riesgos de privacidad al anonimizar datos clínicos: ataques de refinamiento combinatorio al k-anonimato sin información auxiliar, arXiv (2025). DOI: 10.48550/arxiv.2509.03350
Citación: La némesis ARX de Anonymity (2025, 23 de octubre) obtenido el 23 de octubre de 2025 en https://techxplore.com/news/2025-10-anonymity-arx-nemesis.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.