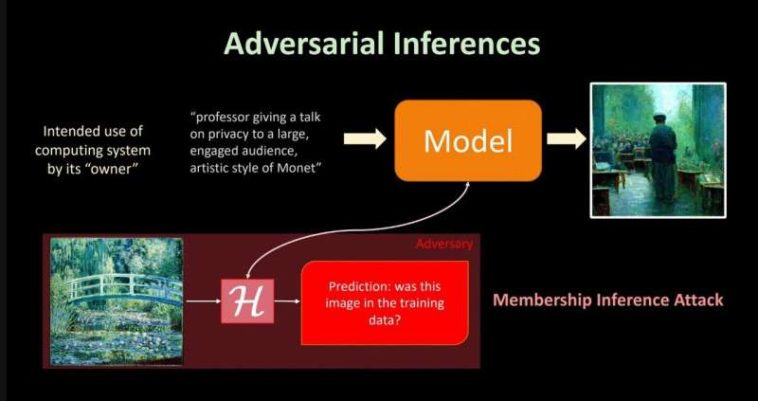

Esta diapositiva muestra cómo podría comenzar un ataque de inferencia de membresía. Evaluar el producto de una aplicación a la que se le pidió que generara una imagen de un profesor enseñando a sus estudiantes «al estilo» del artista Monet podría llevar a inferencias de que una de las pinturas del puente de Monet ayudó en el entrenamiento de la IA. Crédito: David Evans, Ingeniería UVA
Los modelos de lenguaje grandes están en todas partes, incluso se ejecutan en segundo plano en las aplicaciones del dispositivo que estás usando para leer esto. Las sugerencias de autocompletar en sus mensajes de texto y correos electrónicos, las respuestas a las consultas compuestas por Gemni, Copilot y ChatGPT, y las imágenes generadas a partir de DALL-E se crean utilizando LLM.
Y todos están capacitados con documentos e imágenes reales.
El experto en seguridad informática David Evans de la Facultad de Ingeniería y Ciencias Aplicadas de la Universidad de Virginia y sus colegas informaron recientemente que un método común que los desarrolladores de inteligencia artificial utilizan para probar si los datos de capacitación de un LLM están en riesgo de exposición no funciona tan bien como se pensaba. Los hallazgos se publican en el arXiv servidor de preimpresión.
Presentado en el Conferencia para el modelado del lenguaje El mes pasado, el artículo afirma en su resumen: «Encontramos que los MIA apenas superan las conjeturas aleatorias en la mayoría de los entornos en diferentes tamaños y dominios de LLM».
¿Qué es una MIA? ¿Una fuga?
Al crear modelos de lenguaje grandes, los desarrolladores básicamente adoptan un enfoque de aspiradora. Absorben todo el texto que pueden, a menudo de secciones de Internet, así como de fuentes más privadas, como correos electrónicos u otros depósitos de datos, para entrenar sus aplicaciones de inteligencia artificial para comprender las propiedades del mundo en el que trabajan.
Esto es importante cuando se trata de la seguridad de los datos de entrenamiento, que podrían incluir escritos o imágenes que millones de usuarios de Internet publicaron.
Las posibilidades de vulnerabilidad, ya sea para los creadores de contenido o para quienes forman LLM, son amplias.
Los ataques de inferencia de membresía, o MIA, son la herramienta principal que utilizan los desarrolladores de inteligencia artificial para medir los riesgos de exposición de información, conocidos como fugas, explicó Evans, profesor de informática que dirige el Grupo de Investigación de Seguridad en la UVA y coautor de la investigación.
Evans y el estudiante de doctorado recientemente graduado Anshuman Suri, el segundo autor del artículo, que ahora es investigador postdoctoral en la Universidad Northeastern, colaboraron con investigadores de la Universidad de Washington en el estudio.
Anshuman Suri, quien compartió la primera autoría del artículo, es ahora investigador postdoctoral en la Universidad Northeastern. Los investigadores de la UVA colaboraron con investigadores de la Universidad de Washington en el estudio. (Foto aportada)
El principal valor de una prueba de inferencia de membresía en un LLM es como una auditoría de privacidad, explicó Evans. «Es una forma de medir cuánta información filtra el modelo sobre datos de entrenamiento específicos.
Por ejemplo, el uso de software adversario para evaluar el producto de una aplicación a la que se le pide que genere una imagen de un profesor que enseña a sus estudiantes «al estilo» del artista Monet podría llevar a generar inferencias de que una de las pinturas del puente de Monet ayudó en el entrenamiento de la IA.
«Un MIA también se utiliza para comprobar si el modelo ha memorizado textos palabra por palabra, y en caso afirmativo, en qué medida», añadió Suri.
Dada la posibilidad de responsabilidad legal, los desarrolladores querrían saber qué tan sólidas son sus tuberías fundamentales.
¿Qué tan privado es ese LLM? ¿Qué tan efectiva es esa MIA?
Los investigadores realizaron una evaluación a gran escala de cinco MIA de uso común. Todas las herramientas adversas fueron entrenadas en el popular conjunto de datos de modelado de lenguaje de código abierto conocido como «the Pile». Un grupo de investigación sin fines de lucro llamado EleutherAI publicó públicamente la gran colección de modelos de lenguaje en diciembre de 2020.
Microsoft y Meta, junto con importantes universidades como Stanford, han capacitado a los LLM de aplicaciones seleccionadas en el conjunto de datos.
¿Qué hay en los datos de entrenamiento? Subconjuntos de datos recopilados de entradas de Wikipedia, resúmenes de PubMed, antecedentes de la Oficina de Patentes y Marcas de los Estados Unidos, subtítulos de YouTube, matemáticas de Google DeepMind y más, que representan 22 ubicaciones web populares y ricas en información en total.
The Pile no se filtró según quién dio su consentimiento, aunque los investigadores pueden usar las herramientas de Eleuther para refinar el modelo, según los tipos de preocupaciones éticas que puedan tener.
«Descubrimos que los métodos actuales para realizar ataques de inferencia de membresía en LLM en realidad no miden bien la inferencia de membresía, ya que tienen dificultades para definir un buen conjunto representativo de candidatos no miembros para los experimentos», dijo Evans.
Una razón es que la fluidez del lenguaje, a diferencia de otros tipos de datos, puede generar ambigüedad en cuanto a qué constituye un miembro de un conjunto de datos.
«El problema es que los datos del lenguaje no son como registros para entrenar un modelo tradicional, por lo que es muy difícil definir qué es un miembro de entrenamiento», dijo, señalando que las oraciones pueden tener similitudes sutiles o diferencias dramáticas en el significado basadas en pequeños cambios. en la elección de palabras.
«También es muy difícil encontrar candidatos no miembros que sean de la misma distribución, y utilizar límites de tiempo de capacitación para esto es propenso a errores ya que la distribución real del idioma siempre cambia».
Eso es lo que ha provocado que investigaciones publicadas en el pasado que mostraban que los MIA eran efectivos demostraran en realidad una inferencia de distribución, afirman Evans y sus colegas.
La discrepancia «puede atribuirse a un cambio en la distribución, por ejemplo, los miembros y los no miembros aparentemente provienen de un dominio idéntico pero con diferentes rangos temporales», afirma el artículo.
Su investigación de código abierto basada en Python ahora está disponible en un proyecto general llamado MIMIRpara que otros investigadores puedan realizar pruebas de inferencia de membresía más reveladoras.
¿Preocupado? El riesgo relativo sigue siendo bajo
Hasta ahora, la evidencia es que los riesgos de inferencia para registros individuales en datos previos al entrenamiento son bajos, pero no hay garantía.
«Esperamos que haya menos riesgo de inferencia para los LLM debido al enorme tamaño del corpus de entrenamiento y a la forma en que se realiza el entrenamiento, ya que el modelo en entrenamiento a menudo solo ve el texto individual unas pocas veces», dijo Evans.
Al mismo tiempo, la naturaleza interactiva de este tipo de LLM de código abierto abre más vías que podrían usarse en el futuro para realizar ataques más fuertes.
«Sin embargo, sabemos que si un adversario utiliza LLM existentes para entrenar con sus propios datos, lo que se conoce como ajuste fino, sus propios datos son mucho más susceptibles a errores que los datos vistos durante la fase de entrenamiento original del modelo», dijo Suri. .
La conclusión de los investigadores es que medir los riesgos de privacidad del LLM es un desafío y la comunidad de IA apenas está comenzando a aprender cómo hacerlo.
Más información:
Michael Duan et al, ¿Funcionan los ataques de inferencia de membresía en modelos de lenguaje grandes? arXiv (2024). DOI: 10.48550/arxiv.2402.07841
Citación: La forma común de probar fugas en modelos de lenguajes grandes puede tener fallas (2024, 15 de noviembre) recuperado el 15 de noviembre de 2024 de https://techxplore.com/news/2024-11-common-leaks-large-language-flawed.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.


GIPHY App Key not set. Please check settings