Los grandes modelos de lenguaje previamente entrenados, como GPT-3, Codex y otros, se pueden ajustar para generar código a partir de las especificaciones de lenguaje natural de la intención del programador. Dichos modelos automatizados tienen el potencial de mejorar la productividad de todos los programadores del mundo. Pero dado que los modelos pueden tener dificultades para comprender la semántica del programa, no se puede garantizar la calidad del código resultante.
En nuestro trabajo de investigación, Jigsaw: Large Language Models meet Program Synthesis, que ha sido aceptado en la Congreso Internacional de Ingeniería de Software (ICSE 2022), presentamos una nueva herramienta que puede mejorar el rendimiento de estos grandes modelos de lenguaje. Jigsaw implementa técnicas de procesamiento posterior que comprenden la sintaxis y la semántica de los programas y luego aprovecha los comentarios de los usuarios para mejorar el rendimiento futuro. Jigsaw está diseñado para sintetizar código para la API de Python Pandas utilizando entradas multimodales.
Nuestra experiencia sugiere que a medida que estos grandes modelos de lenguaje evolucionan para sintetizar código a partir de la intención, Jigsaw puede desempeñar un papel importante en la mejora de la precisión de los sistemas.
La promesa y los peligros del software escrito por máquina
Los grandes modelos de lenguaje como Codex de OpenAI están redefiniendo el panorama de la programación. Un desarrollador de software, mientras resuelve una tarea de programación, puede proporcionar una descripción en inglés para un fragmento de código previsto y Codex puede sintetizar el código previsto en lenguajes como Python o JavaScript. Sin embargo, el código sintetizado puede ser incorrecto e incluso podría fallar al compilar o ejecutar. Los usuarios del Codex son responsables de examinar el código antes de usarlo. Con Project Jigsaw, nuestro objetivo es automatizar parte de esta investigación para aumentar la productividad de los desarrolladores que usan modelos de lenguaje grandes como Codex para la síntesis de código.
Supongamos que Codex proporciona un fragmento de código a un desarrollador de software. Luego, el desarrollador podría realizar una investigación básica comprobando si el código se compila. Si no se compila, entonces el desarrollador podría usar los mensajes de error del compilador para repararlo. Una vez que el código finalmente se compila, un desarrollador típico lo probará en una entrada para verificar si el código está produciendo el resultado deseado o no. Una vez más, el código podría fallar (generar una excepción o producir un resultado incorrecto) y el desarrollador tendría que repararlo más. Mostramos que este proceso puede ser completamente automatizado. Jigsaw toma como entrada una descripción en inglés del código previsto, así como un ejemplo de E/S. De esta manera, empareja una entrada con la salida asociada y proporciona la garantía de calidad de que el código Python de salida compilará y generará la salida prevista en la entrada proporcionada.
En nuestro CISE 2022 paper, Jigsaw: Large Language Models meet Program Synthesis, evaluamos este enfoque en Python Pandas. Pandas es una API ampliamente utilizada en ciencia de datos, con cientos de funciones para manipular marcos de datos o tablas con filas y columnas. En lugar de pedirle a un desarrollador que memorice el uso de todas estas funciones, podría decirse que un mejor enfoque es usar Jigsaw. Con Jigsaw, el usuario proporciona una descripción de la transformación deseada en inglés, un marco de datos de entrada y el marco de datos de salida correspondiente, y luego deja que Jigsaw sintetice el código deseado. Por ejemplo, suponga que un desarrollador desea eliminar el prefijo «Nombre:» de la columna «país» en la tabla a continuación. Usando Pandas, esto se puede solucionar realizando la siguiente operación:
df['c'] = df['c'].str.replace('Name: ', '')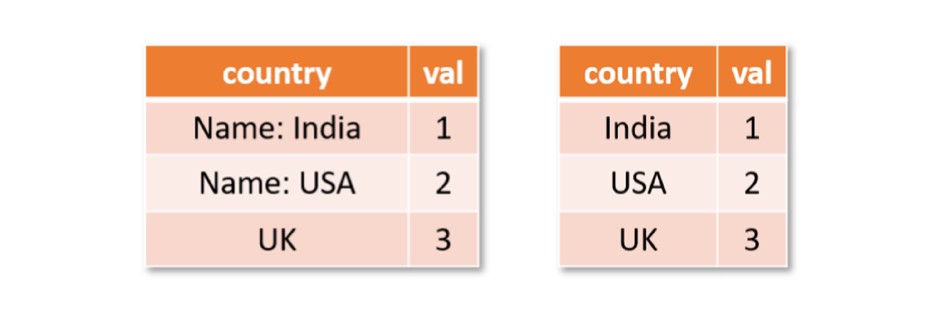
Un desarrollador nuevo en Pandas deberá descubrir las funciones y sus argumentos para armar este fragmento de código o publicar la consulta y el ejemplo en un foro como StackOverflow y esperar a que responda un buen samaritano. Además, es posible que tengan que modificar la respuesta, a veces considerablemente, según el contexto. Por el contrario, es mucho más conveniente proporcionar la consulta en inglés con una tabla de entrada y salida (o marco de datos).
Cómo funciona el rompecabezas
Jigsaw toma la consulta en inglés y la procesa previamente con el contexto apropiado para crear una entrada que se puede alimentar a un modelo de lenguaje grande. El modelo se trata como una caja negra y Jigsaw se ha evaluado tanto con GPT-3 como con Codex. La ventaja de este diseño es que permite conectar y usar con los mejores y más recientes modelos disponibles. Una vez que el modelo genera un código de salida, Jigsaw verifica si cumple con el ejemplo de E/S. Si es así, ¡entonces Jigsaw está listo! La salida del modelo ya es correcta. En nuestros experimentos, encontramos que esto sucedió aproximadamente el 30% del tiempo. Si el código falla, el proceso de reparación comienza en una fase de posprocesamiento.
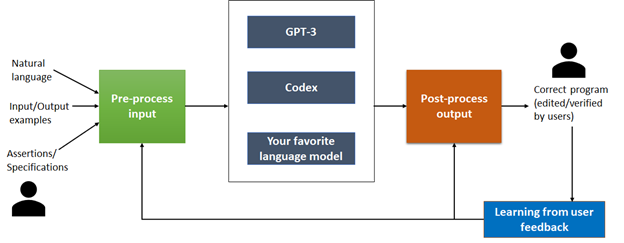
Durante el posprocesamiento, Jigsaw aplica tres tipos de transformaciones para reparar el código. Cada una de estas transformaciones está motivada por los modos de falla que hemos observado en GPT-3 y Codex. Sorprendentemente, tanto GPT-3 como Codex fallan de manera similar y, por lo tanto, el procesamiento posterior de Jigsaw para abordar estos modos de falla es útil para ambos.
Transformaciones de variables
Hemos observado que Codex puede generar resultados que utilizan nombres de variables incorrectos. Por ejemplo, la mayoría de los códigos disponibles públicamente usan nombres como df1, df2, etc. para marcos de datos. Entonces, la salida del Codex también usa estos nombres. Ahora, si el desarrollador usa g1, g2, etc. como nombres de marcos de datos, la salida del Codex probablemente usará df1, df2, etc. y fallará. Otras veces, Codex confunde los nombres de las variables que se le proporcionan. Por ejemplo, produce df2.merge(df1)instead of df1.merge(df2). Para corregir este tipo de errores, Jigsaw reemplaza los nombres en el código generado por Codex con todos los nombres posibles en el alcance hasta que encuentra un programa que satisface el ejemplo de E/S. Encontramos que esta simple transformación es muy útil en muchos casos.
Transformaciones de argumentos
A veces, el código generado por Codex llama a las funciones API esperadas pero con algunos de los argumentos incorrectos. Por ejemplo:
a.) Consulta: suelte todas las filas que están duplicadas en la columna ‘inputB’
dfout = dfin.drop_duplicates(subset=['inputB']) # Model
dfout = dfin.drop_duplicates(subset=['inputB'],keep=False) # Correctb.) Consulta: reemplace Canadá con CAN en columna pais de df
df = df.replace({'Canada':'CAN'}) # Model
df = df.replace({'country':{'Canada':'CAN'}) # CorrectPara corregir tales errores, Jigsaw enumera sistemáticamente todos los argumentos posibles, utilizando las secuencias de funciones y argumentos generadas por Codex como punto de partida, hasta que encuentra un programa que satisface el ejemplo de E/S.
Transformaciones de AST a AST
Un AST (abstract-syntax-tree) es una representación de código en forma de árbol. Dado que los modelos como Codex funcionan a un nivel sintáctico, pueden producir código sintácticamente muy similar al programa deseado, pero algunos caracteres pueden ser incorrectos. Por ejemplo:
a.) Consulta: seleccione filas de dfin donde el valor en la barra es or >60
dfout = dfin[dfin['bar']60] # Model
dfout = dfin[(dfin['bar'])|(dfin['bar']>60)] # CorrectError: los paréntesis faltantes cambian la precedencia y causan una excepción
b.) Consulta: cuente el número de filas duplicadas en df
out = df.duplicated() # Model
out = df.duplicated().sum() # CorrectError: falta la suma requerida para obtener el conteo
Para corregir este modo de falla, Jigsaw proporciona transformaciones de AST a AST que se aprenden con el tiempo. El usuario tendría que corregir el código por sí mismo; luego, la interfaz de usuario de Jigsaw capturará la edición, generalizará la edición a una transformación más aplicable y aprenderá esta transformación. Con el uso, el número de transformaciones aumenta y Jigsaw se vuelve cada vez más efectivo.
Evaluación
Evaluamos Codex y Jigsaw (con Codex) en varios conjuntos de datos y medimos la precisión, que es el porcentaje de tareas en el conjunto de datos donde el sistema produce el resultado deseado. Codex da una precisión de alrededor del 30% lista para usar, que es lo que se espera de El artículo de OpenAI así como. Jigsaw mejora la precisión a >60 % y, a través de los comentarios de los usuarios, la precisión mejora a >80 %.
El camino por delante
Hemos publicado los conjuntos de datos que usamos para evaluar Jigsaw en el dominio público. Cada conjunto de datos incluye múltiples tareas, donde cada tarea tiene una consulta en inglés y un ejemplo de E/S. Resolver una tarea requiere generar un código de Pandas que asigne el marco de datos de entrada proporcionado al marco de datos de salida correspondiente. Esperamos que este conjunto de datos ayude a evaluar y comparar otros sistemas. Aunque hay conjuntos de datos en los que las tareas solo tienen consultas en inglés o solo ejemplos de E/S, los conjuntos de datos de Jigsaw son los primeros en contener consultas en inglés y los ejemplos de E/S asociados.
A medida que estos modelos de lenguaje continúen evolucionando y se vuelvan más poderosos, creemos que Jigsaw seguirá siendo necesario para proporcionar las barreras y hacer que estos modelos sean viables en escenarios del mundo real. Esto es solo abordar la punta del iceberg de los problemas de investigación en esta área y aún quedan muchas preguntas por responder:
- ¿Se pueden entrenar estos modelos de lenguaje para aprender la semántica asociada con el código?
- ¿Se pueden integrar mejores pasos de preprocesamiento y posprocesamiento en Jigsaw? Por ejemplo, estamos buscando técnicas de análisis estático para mejorar el posprocesamiento.
- ¿Los ejemplos de E/S son efectivos para otras API además de Python Pandas? ¿Cómo abordamos escenarios donde los ejemplos de E/S no están disponibles? ¿Cómo adaptamos Jigsaw para lenguajes como JavaScript y código general en Python?
- La sobrecarga del desarrollador de proporcionar un ejemplo en lugar de solo proporcionar una consulta en lenguaje natural necesita una mayor evaluación e investigación.
Estas son algunas de las direcciones interesantes que estamos siguiendo. A medida que refinamos y mejoramos Jigsaw, creemos que puede desempeñar un papel importante en la mejora de la productividad del programador a través de la automatización. Seguimos trabajando para generalizar nuestra experiencia con la API de Python Pandas para que funcione en otras API y otros lenguajes.
Otros colaboradores:
namán jainistaInvestigador en Microsoft Research India Lab
Skanda Vaidyanathpasante en Microsoft Research India Lab, actualmente cursando una maestría en Stanford