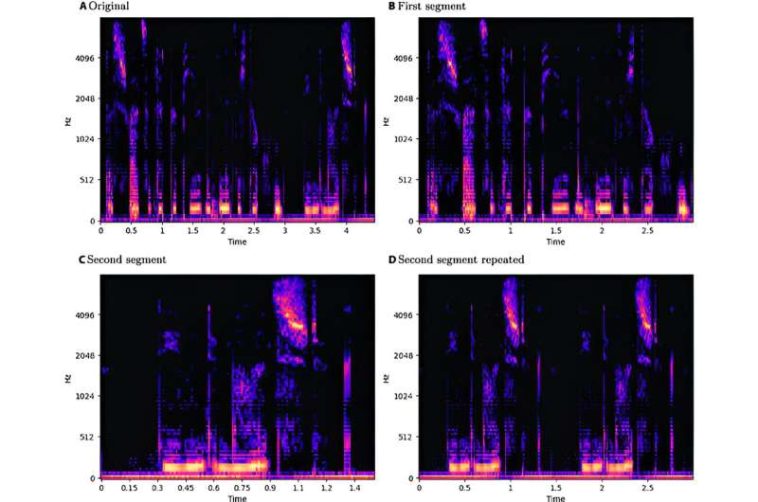
, segmentos cortados (B y C) y segmento (C) repetido durante 3 s (D). Crédito: Intelligent Computing (2024). DOI: 10.34133/icomputing.0088")
Ejemplo de proceso de división y repetición en espectrogramas log-Mel. Espectrograma log-Mel original (A), segmentos cortados (B y C) y segmento (C) repetido durante 3 s (D). Crédito: Computación inteligente (2024). DOI: 10.34133/icomputación.0088
Los recientes avances en el reconocimiento de emociones del habla han puesto de relieve el potencial significativo de las tecnologías de aprendizaje profundo en diversas aplicaciones. Sin embargo, estos modelos de aprendizaje profundo son susceptibles a ataques adversarios.
Un equipo de investigadores de la Universidad de Milán evaluó sistemáticamente el impacto de los ataques de caja blanca y caja negra en diferentes idiomas y géneros dentro del reconocimiento de emociones del habla. publicado 27 de mayo en Computación inteligente.
La investigación destaca la considerable vulnerabilidad de los modelos de memoria a corto plazo de redes neuronales convolucionales a los ejemplos adversarios, que son entradas «perturbadas» cuidadosamente diseñadas que llevan a los modelos a producir predicciones erróneas. Los hallazgos indican que todos los ataques adversarios considerados pueden reducir significativamente el rendimiento de los modelos de reconocimiento de emociones del habla. Según los autores, la susceptibilidad de estos modelos a los ataques adversarios «podría desencadenar graves consecuencias».
Los investigadores propusieron una metodología para el procesamiento de datos de audio y la extracción de características que se adapta a la arquitectura de memoria a corto plazo de las redes neuronales convolucionales. Examinaron tres conjuntos de datos, EmoDB para alemán, EMOVO para italiano y RAVDESS para inglés. Utilizaron el método Fast Gradient Sign, el método iterativo básico, DeepFool, el ataque de mapa de saliencia basado en Jacobiano y Carlini y Wagner para los ataques de caja blanca y el ataque de un píxel y el ataque de límites para los escenarios de caja negra.
Los ataques de caja negra, especialmente el ataque de límite, lograron resultados impresionantes a pesar de su acceso limitado al funcionamiento interno de los modelos. Si bien los ataques de caja blanca no tenían tales limitaciones, los ataques de caja negra a veces los superaron; es decir, generaron ejemplos adversarios con un rendimiento superior y menos interrupciones.
Los autores dijeron: «Estas observaciones son alarmantes ya que implican que los atacantes pueden potencialmente lograr resultados notables sin ninguna comprensión del funcionamiento interno del modelo, simplemente examinando su resultado».
La investigación incorporó una perspectiva de género para investigar los impactos diferenciales de los ataques adversarios en el habla masculina y femenina, así como en el habla en diferentes idiomas. Al evaluar los impactos de los ataques en tres idiomas, solo se observaron diferencias menores en el desempeño.
El inglés parecía ser el más susceptible, mientras que el italiano mostró la mayor resistencia. El examen detallado de las muestras masculinas y femeninas indicó una ligera superioridad en las muestras masculinas, que exhibieron una precisión y perturbación marginalmente menores, particularmente en escenarios de ataque de caja blanca. Sin embargo, las variaciones entre las muestras masculinas y femeninas fueron insignificantes.
«Ideamos un proceso para estandarizar muestras en los tres idiomas y extraer espectrogramas log-Mel. Nuestra metodología implicó aumentar los conjuntos de datos utilizando técnicas de cambio de tono y estiramiento temporal, manteniendo al mismo tiempo una duración máxima de muestra de 3 segundos», explicaron los autores. Además, para garantizar la coherencia metodológica, el equipo utilizó la misma arquitectura de memoria a corto plazo de red neuronal convolucional para todos los experimentos.
Si bien la publicación de investigaciones que revelan vulnerabilidades en los modelos de reconocimiento de emociones del habla puede parecer que podría brindar información valiosa a los atacantes, no compartir estos hallazgos podría ser potencialmente más perjudicial. La transparencia en las investigaciones permite que tanto los atacantes como los defensores comprendan las debilidades de estos sistemas.
Al dar a conocer estas vulnerabilidades, los investigadores y profesionales pueden preparar y fortalecer mejor sus sistemas contra amenazas potenciales, contribuyendo en última instancia a un panorama tecnológico más seguro.
Más información:
Nicolas Facchinetti et al, Una evaluación sistemática de ataques adversarios contra modelos de reconocimiento de emociones del habla, Computación inteligente (2024). DOI: 10.34133/icomputing.0088
Citación:Los investigadores exponen la vulnerabilidad de los modelos de reconocimiento de emociones del habla a los ataques adversarios (9 de agosto de 2024) recuperado el 9 de agosto de 2024 de https://techxplore.com/news/2024-08-expose-vulnerability-speech-emotion-recognition.html
Este documento está sujeto a derechos de autor. Salvo que se haga un uso legítimo con fines de estudio o investigación privados, no se podrá reproducir ninguna parte del mismo sin autorización por escrito. El contenido se ofrece únicamente con fines informativos.

GIPHY App Key not set. Please check settings