|
|
Hoy presentamos Amazon Nova Multimodal Embeddings, un modelo de incorporación multimodal de última generación para aplicaciones de búsqueda semántica y de generación aumentada de recuperación agente (RAG), disponible en Amazon Bedrock. Es el primer modelo de incrustación unificado que admite texto, documentos, imágenes, video y audio a través de un único modelo para permitir la recuperación intermodal con una precisión líder.
Los modelos de incrustación convierten entradas textuales, visuales y de audio en representaciones numéricas llamadas incrustaciones. Estas incorporaciones capturan el significado de la entrada de una manera que los sistemas de inteligencia artificial pueden comparar, buscar y analizar, impulsando casos de uso como la búsqueda semántica y RAG.
Las organizaciones buscan cada vez más soluciones para desbloquear conocimientos del creciente volumen de datos no estructurados que se distribuyen en contenido de texto, imágenes, documentos, videos y audio. Por ejemplo, una organización puede tener imágenes de productos, folletos que contienen infografías y texto, y videoclips subidos por los usuarios. Los modelos integrados pueden generar valor a partir de datos no estructurados; sin embargo, los modelos tradicionales suelen estar especializados para manejar un tipo de contenido. Esta limitación lleva a los clientes a crear soluciones complejas de integración multimodal o a limitarse a casos de uso centrados en un único tipo de contenido. El problema también se aplica a tipos de contenido de modalidad mixta, como documentos con texto e imágenes entrelazados o videos con elementos visuales, de audio y textuales, donde los modelos existentes luchan por capturar relaciones intermodales de manera efectiva.
Nova Multimodal Embeddings admite un espacio semántico unificado para texto, documentos, imágenes, video y audio para casos de uso como búsqueda intermodal en contenido de modalidad mixta, búsqueda con una imagen de referencia y recuperación de documentos visuales.
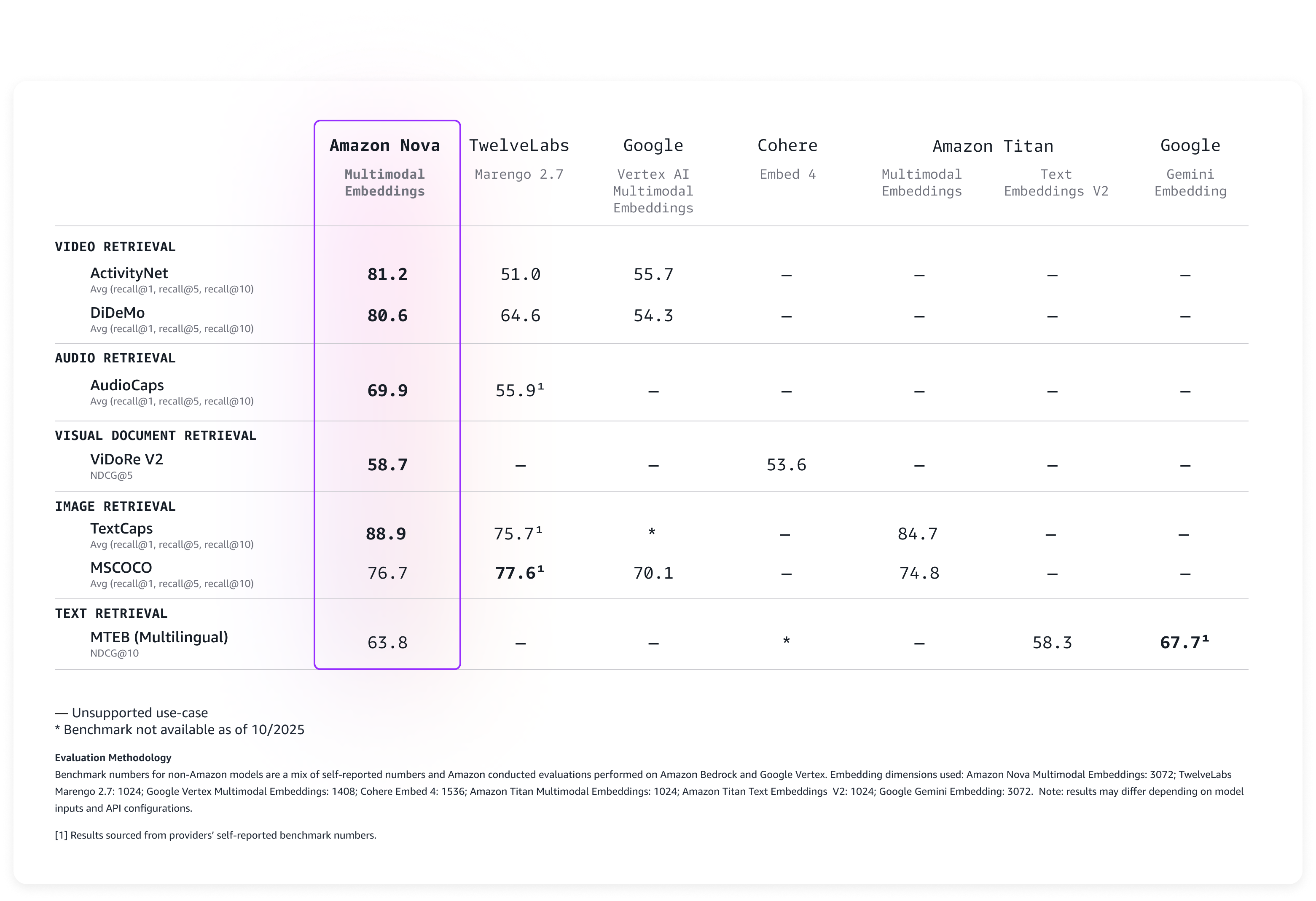
Evaluación del rendimiento de las incorporaciones multimodales de Amazon Nova
Evaluamos el modelo en una amplia gama de puntos de referencia y ofrece una precisión líder lista para usar, como se describe en la siguiente tabla.
Nova Multimodal Embeddings admite una longitud de contexto de hasta 8K tokens, texto en hasta 200 idiomas y acepta entradas a través de API sincrónicas y asincrónicas. Además, admite la segmentación (también conocida como «fragmentación») para dividir contenido de texto, vídeo o audio de formato largo en segmentos manejables, generando incrustaciones para cada parte. Por último, el modelo ofrece cuatro dimensiones de incorporación de salida, entrenadas utilizando Aprendizaje de representación de matrioskas (MRL) que permite la recuperación de un extremo a otro de baja latencia con cambios mínimos de precisión.
Veamos cómo se puede utilizar el nuevo modelo en la práctica.
Uso de incrustaciones multimodales de Amazon Nova
La introducción a Nova Multimodal Embeddings sigue el mismo patrón que otros modelos de Amazon Bedrock. El modelo acepta texto, documentos, imágenes, vídeo o audio como entrada y devuelve incrustaciones numéricas que puede utilizar para búsqueda semántica, comparación de similitudes o RAG.
A continuación se muestra un ejemplo práctico que utiliza AWS SDK para Python (Boto3) que muestra cómo crear incrustaciones de diferentes tipos de contenido y almacenarlas para su posterior recuperación. Para simplificar, usaré Amazon S3 Vectors, un almacenamiento de costo optimizado con soporte nativo para almacenar y consultar vectores a cualquier escala, para almacenar y buscar las incrustaciones.
Comencemos con lo fundamental: convertir texto en incrustaciones. Este ejemplo muestra cómo transformar una descripción de texto simple en una representación numérica que capture su significado semántico. Estas incrustaciones se pueden comparar posteriormente con incrustaciones de documentos, imágenes, vídeos o audio para encontrar contenido relacionado.
Para que el código sea fácil de seguir, mostraré una sección del script a la vez. El guión completo se incluye al final de este tutorial.
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Initialize Amazon Bedrock Runtime client
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
print(f"Generating text embedding with {MODEL_ID} ...")
# Text to embed
text = "Amazon Nova is a multimodal foundation model"
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# Extract embedding
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")Ahora procesaremos contenido visual usando el mismo espacio de incrustación usando un photo.jpg archivo en la misma carpeta que el script. Esto demuestra el poder de la multimodalidad: Nova Multimodal Embeddings es capaz de capturar contexto textual y visual en una única incrustación que proporciona una mejor comprensión del documento.
Nova Multimodal Embeddings puede generar incrustaciones optimizadas para su uso. Al indexar para un caso de uso de búsqueda o recuperación, embeddingPurpose se puede configurar en GENERIC_INDEX. Para el paso de consulta, embeddingPurpose Se puede configurar según el tipo de elemento que se va a recuperar. Por ejemplo, al recuperar documentos, embeddingPurpose se puede configurar en DOCUMENT_RETRIEVAL.
# Read and encode image
print(f"Generating image embedding with {MODEL_ID} ...")
with open("photo.jpg", "rb") as f:
image_bytes = base64.b64encode(f.read()).decode("utf-8")
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "jpeg",
"source": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# Extract embedding
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")Para procesar contenido de video, utilizo la API asincrónica. Este es un requisito para vídeos de más de 25 MB cuando se codifican como Base64. Primero, subo un vídeo local a un depósito S3 en la misma región de AWS.
aws s3 cp presentation.mp4 s3://my-video-bucket/videos/Este ejemplo muestra cómo extraer incrustaciones de componentes visuales y de audio de un archivo de vídeo. La función de segmentación divide los videos más largos en partes manejables, lo que hace que sea práctico buscar horas de contenido de manera eficiente.
# Initialize Amazon S3 client
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URIs
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
S3_EMBEDDING_DESTINATION_URI = "s3://my-embedding-destination-bucket/embeddings-output/"
# Create async embedding job for video with audio
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # Segment into 15-second chunks
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job started: {invocation_arn}")
# Poll until job completes
print("\nPolling for job completion...")
while True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(15)
# Check if job completed successfully
if status == "Completed":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"\nSuccess! Embeddings at: {output_s3_uri}")
# Parse S3 URI to get bucket and prefix
s3_uri_parts = output_s3_uri[5:].split("/", 1) # Remove "s3://" prefix
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED mode outputs to embedding-audio-video.jsonl
# The output_s3_uri already includes the job ID, so just append the filename
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Reading embeddings from: s3://{bucket}/{embeddings_key}")
# Read and parse JSONL file
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content = response['Body'].read().decode('utf-8')
embeddings = []
for line in content.strip().split('\n'):
if line:
embeddings.append(json.loads(line))
print(f"\nFound {len(embeddings)} video segments:")
for i, segment in enumerate(embeddings):
print(f" Segment {i}: {segment.get('startTime', 0):.1f}s - {segment.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(segment.get('embedding', []))}")
else:
print(f"\nJob failed: {job.get('failureMessage', 'Unknown error')}")Una vez generadas nuestras incrustaciones, necesitamos un lugar para almacenarlas y buscarlas de manera eficiente. Este ejemplo demuestra la configuración de un almacén de vectores utilizando Amazon S3 Vectors, que proporciona la infraestructura necesaria para la búsqueda de similitudes a escala. Piense en esto como la creación de un índice de búsqueda donde el contenido semánticamente similar se agrupa naturalmente. Al agregar una incrustación al índice, uso los metadatos para especificar el formato original y el contenido que se indexa.
# Initialize Amazon S3 Vectors client
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# Configuration
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# Create vector bucket and index (if they don't exist)
try:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
try:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"\nGenerating embeddings for {len(texts)} texts...")
# Generate embeddings using Amazon Nova for each text
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"text:{text[:50]}", # Unique identifier
"data": {"float32": embedding},
"metadata": {"type": "text", "content": text}
})
print(f" ✓ Generated embedding for: {text}")
# Add all vectors to store in a single call
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"\nSuccessfully added {len(vectors)} vectors to the store in one put_vectors call!")Este último ejemplo demuestra la capacidad de buscar en diferentes tipos de contenido con una sola consulta, encontrando el contenido más similar independientemente de si se originó a partir de texto, imágenes, videos o audio. Las puntuaciones de distancia le ayudan a comprender qué tan estrechamente relacionados están los resultados con su consulta original.
# Text to query
query_text = "foundation models"
print(f"\nGenerating embeddings for query '{query_text}' ...")
# Generate embeddings
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": query_text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Searching for similar embeddings...\n")
# Search for top 5 most similar vectors
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# Display results
print(f"Found {len(response['vectors'])} results:\n")
for i, result in enumerate(response["vectors"], 1):
print(f"{i}. {result['key']}")
print(f" Distance: {result['distance']:.4f}")
if result.get("metadata"):
print(f" Metadata: {result['metadata']}")
print()La búsqueda intermodal es una de las ventajas clave de las incorporaciones multimodales. Con la búsqueda intermodal, puede realizar consultas con texto y encontrar imágenes relevantes. También puede buscar videos usando descripciones de texto, encontrar clips de audio que coincidan con ciertos temas o descubrir documentos según su contenido visual y textual. Para su referencia, el script completo con todos los ejemplos anteriores combinados está aquí:
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Initialize Amazon Bedrock Runtime client
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
print(f"Generating text embedding with {MODEL_ID} ...")
# Text to embed
text = "Amazon Nova is a multimodal foundation model"
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# Extract embedding
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# Read and encode image
print(f"Generating image embedding with {MODEL_ID} ...")
with open("photo.jpg", "rb") as f:
image_bytes = base64.b64encode(f.read()).decode("utf-8")
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "jpeg",
"source": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# Extract embedding
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# Initialize Amazon S3 client
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URIs
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
# Amazon S3 output bucket and location
S3_EMBEDDING_DESTINATION_URI = "s3://my-video-bucket/embeddings-output/"
# Create async embedding job for video with audio
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # Segment into 15-second chunks
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job started: {invocation_arn}")
# Poll until job completes
print("\nPolling for job completion...")
while True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(15)
# Check if job completed successfully
if status == "Completed":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"\nSuccess! Embeddings at: {output_s3_uri}")
# Parse S3 URI to get bucket and prefix
s3_uri_parts = output_s3_uri[5:].split("/", 1) # Remove "s3://" prefix
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED mode outputs to embedding-audio-video.jsonl
# The output_s3_uri already includes the job ID, so just append the filename
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Reading embeddings from: s3://{bucket}/{embeddings_key}")
# Read and parse JSONL file
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content = response['Body'].read().decode('utf-8')
embeddings = []
for line in content.strip().split('\n'):
if line:
embeddings.append(json.loads(line))
print(f"\nFound {len(embeddings)} video segments:")
for i, segment in enumerate(embeddings):
print(f" Segment {i}: {segment.get('startTime', 0):.1f}s - {segment.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(segment.get('embedding', []))}")
else:
print(f"\nJob failed: {job.get('failureMessage', 'Unknown error')}")
# Initialize Amazon S3 Vectors client
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# Configuration
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# Create vector bucket and index (if they don't exist)
try:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
try:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"\nGenerating embeddings for {len(texts)} texts...")
# Generate embeddings using Amazon Nova for each text
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"text:{text[:50]}", # Unique identifier
"data": {"float32": embedding},
"metadata": {"type": "text", "content": text}
})
print(f" ✓ Generated embedding for: {text}")
# Add all vectors to store in a single call
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"\nSuccessfully added {len(vectors)} vectors to the store in one put_vectors call!")
# Text to query
query_text = "foundation models"
print(f"\nGenerating embeddings for query '{query_text}' ...")
# Generate embeddings
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": query_text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Searching for similar embeddings...\n")
# Search for top 5 most similar vectors
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# Display results
print(f"Found {len(response['vectors'])} results:\n")
for i, result in enumerate(response["vectors"], 1):
print(f"{i}. {result['key']}")
print(f" Distance: {result['distance']:.4f}")
if result.get("metadata"):
print(f" Metadata: {result['metadata']}")
print()Para aplicaciones de producción, las incrustaciones se pueden almacenar en cualquier base de datos vectorial. Amazon OpenSearch Service ofrece integración nativa con Nova Multimodal Embeddings en el lanzamiento, lo que facilita la creación de aplicaciones de búsqueda escalables. Como se muestra en los ejemplos anteriores, Amazon S3 Vectors proporciona una forma sencilla de almacenar y consultar incrustaciones con los datos de su aplicación.
Cosas que debes saber
Nova Multimodal Embeddings ofrece cuatro opciones de dimensiones de salida: 3072, 1024, 384 y 256. Las dimensiones más grandes proporcionan representaciones más detalladas pero requieren más almacenamiento y cálculo. Las dimensiones más pequeñas ofrecen un equilibrio práctico entre el rendimiento de recuperación y la eficiencia de los recursos. Esta flexibilidad le ayuda a optimizar sus aplicaciones y requisitos de costos específicos.
El modelo maneja longitudes de contexto sustanciales. Para entradas de texto, puede procesar hasta 8192 tokens a la vez. Las entradas de video y audio admiten segmentos de hasta 30 segundos y el modelo puede segmentar archivos más largos. Esta capacidad de segmentación es particularmente útil cuando se trabaja con archivos multimedia grandes: el modelo los divide en partes manejables y crea incrustaciones para cada segmento.
El modelo incluye funciones de IA responsable integradas en Amazon Bedrock. El contenido enviado para su inserción pasa por los filtros de seguridad de contenido de Amazon Bedrock y el modelo incluye medidas de equidad para reducir el sesgo.
Como se describe en los ejemplos de código, el modelo se puede invocar a través de API tanto síncronas como asíncronas. La API síncrona funciona bien para aplicaciones en tiempo real donde necesita respuestas inmediatas, como procesar consultas de usuarios en una interfaz de búsqueda. La API asincrónica maneja cargas de trabajo insensibles a la latencia de manera más eficiente, lo que la hace adecuada para procesar contenido de gran tamaño, como videos.
Disponibilidad y precios
Amazon Nova Multimodal Embeddings está disponible hoy en Amazon Bedrock en la región de AWS de EE. UU. Este (Norte de Virginia). Para obtener información detallada sobre precios, visite la página de precios de Amazon Bedrock.
Para obtener más información, consulte la Guía del usuario de Amazon Nova para obtener documentación completa y la Libro de cocina modelo Amazon Nova en GitHub para ejemplos prácticos de código.
Si está utilizando un asistente con tecnología de inteligencia artificial para el desarrollo de software, como Amazon Q Developer o kiropuedes configurar el Servidor MCP API de AWS para ayudar a los asistentes de IA a interactuar con los servicios y recursos de AWS y el Servidor MCP de conocimientos de AWS para proporcionar documentación actualizada, ejemplos de código y conocimientos sobre la disponibilidad regional de las API de AWS y los recursos de CloudFormation.
Comience a crear aplicaciones multimodales impulsadas por IA con Nova Multimodal Embeddings hoy y comparta sus comentarios a través de AWS re: Publicación para Amazon Bedrock o sus contactos habituales de AWS Support.
— Danilo