
Un equipo de investigación del Instituto de Tecnología de Illinois extrajo información personal, específicamente características protegidas como la edad y el género, de datos anónimos de teléfonos celulares utilizando algoritmos de aprendizaje automático e inteligencia artificial, lo que genera dudas sobre la seguridad de los datos.
La investigación fue realizada por un equipo interdisciplinario de tres profesores de Illinois Tech, incluidos Vijay K. Gurbani, profesor asociado de investigación de ciencias de la computación; Matthew Shapiro, profesor de ciencias políticas; y Yuri Mansury, profesor asociado de ciencias sociales. A ellos se unieron los ex alumnos de Illinois Tech Lida Kuang (MS CS ’19) y Samruda Pobbathi (MS CS ’19) que trabajaron con Gurbani para publicar «Predicción de la edad y el género a partir de la telemetría de red: implicaciones para la privacidad y el impacto en la política» en Más uno.
Los investigadores utilizaron datos de una compañía de telefonía celular latinoamericana para estimar con relativa facilidad el género y la edad de los usuarios individuales a través de sus comunicaciones privadas.
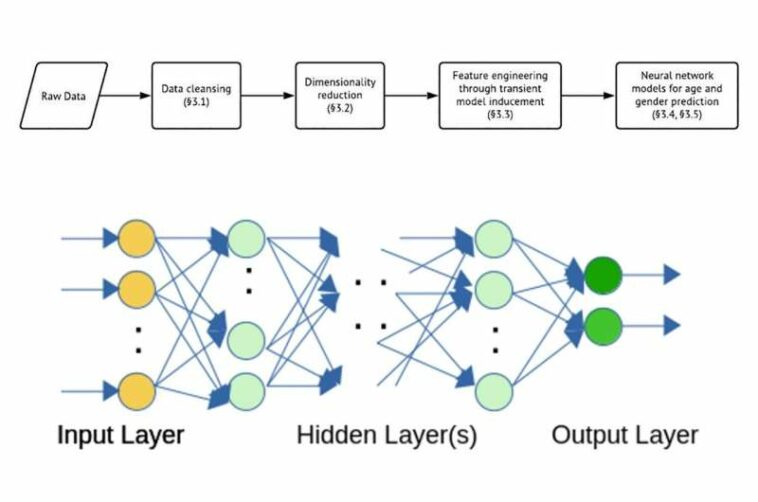
El equipo desarrolló un modelo de red neuronal para estimar el género con un 67 % de precisión, lo que supera a las técnicas modernas como el árbol de decisión, el bosque aleatorio y los modelos de aumento de gradiente por un margen significativo. También pudieron estimar la edad de los usuarios individuales con una tasa de precisión del 78 % utilizando el mismo modelo.
«La información sobre la edad y el género parece inocua, pero las personas utilizan esta información de manera nefasta, muchas veces con consecuencias devastadoras», dice Shapiro.
«Cuando alguien con malas intenciones apunta a niños pequeños por cualquier cosa, desde ventas hasta depredación sexual, viola una serie de leyes diseñadas para proteger a los menores, como la Ley de protección de la privacidad en línea de los niños y la HIPAA. En el otro extremo del espectro de edad, las personas mayores son objeto de sofisticados esfuerzos de spam y phishing dada su susceptibilidad y su acceso a los ahorros».
Esta información se extrapoló utilizando equipos de cómputo comúnmente accesibles. El equipo usó un sistema operativo Linux (Fedora) con 16 GB de memoria y una CPU Intel i5-6200U con cuatro núcleos para ejecutar el modelo de red neuronal.
«La computadora portátil que usamos para este trabajo no es exclusiva en absoluto», dice Gurbani. «Para un adversario con buenos recursos, habrá máquinas mucho más poderosas disponibles, incluido el acceso a la computación en clúster, donde varias computadoras están configuradas en un clúster para proporcionar la potencia informática para los modelos AI/ML».
El conjunto de datos utilizado para realizar la investigación no está disponible públicamente, pero Gurbani dice que un adversario podría recopilar un conjunto de datos similar capturando datos a través de puntos de acceso Wi-Fi públicos o atacando la infraestructura informática de los proveedores de servicios.
«Como mencionamos en nuestro artículo, lamentablemente tales ataques ocurren y no son raros», dice Gurbani. «El proceso para recopilar estos datos no sería fácil, pero tampoco sería imposible».
El objetivo del documento es iniciar un diálogo que examine críticamente el impacto que las técnicas emergentes de aprendizaje automático e IA tienen en las regulaciones de privacidad. No existen regulaciones de privacidad a nivel nacional en los Estados Unidos, por lo que los investigadores observaron cómo estas técnicas socavan los artículos del Reglamento General de Protección de Datos de la Unión Europea, que están diseñados para proteger a los consumidores de la amenaza inminente de violaciones de la privacidad.
«El aprendizaje automático y la toma de decisiones automatizada serán la corriente principal de los procesos comerciales, y no hay forma de escapar de esa realidad», dice Gurbani. «El tema en cuestión es cómo proteger la privacidad individual, así como los intereses sociales y económicos del fraude utilizando el marco regulatorio apropiado».
Una forma de hacerlo, dice Mansury, es brindarles a los consumidores la «opción de exclusión voluntaria» para mantener su información personal privada al instalar una aplicación.
Las recomendaciones incluyen el uso de datos sintéticos en lugar de la observación del usuario para los modelos de aprendizaje automático, que los titulares de datos trabajen con especialistas en aprendizaje automático para desarrollar mejores prácticas, crear un marco regulatorio que permita a los usuarios optar por no compartir datos para mantener la privacidad de la información personal y actualizar los protocolos de incumplimiento existentes. En otras palabras, hay mucho más trabajo por hacer para abordar las lagunas de las políticas, así como la ética de la IA.
Un modelo para clasificar textos financieros protegiendo la privacidad de los usuarios
Lida Kuang et al, Predecir la edad y el sexo a partir de la telemetría de red: Implicaciones para la privacidad e impacto en la política, MÁS UNO (2022). DOI: 10.1371/journal.pone.0271714
Citación: Extracción de información personal de datos anónimos de teléfonos celulares mediante aprendizaje automático (12 de octubre de 2022) consultado el 12 de octubre de 2022 en https://techxplore.com/news/2022-10-personal-anonymous-cell-machine.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.