Los sistemas de IA se vuelven cada vez más complejos a medida que pasamos de la investigación visionaria a tecnologías implementables como automóviles autónomos, modelos predictivos clínicos y dispositivos de accesibilidad novedosos. A diferencia de los modelos de IA singulares, es más difícil evaluar si estos sistemas de IA más complejos están funcionando de manera consistente y según lo previsto para lograr el beneficio humano.
-
- Contextos del mundo real para los que los datos pueden ser ruidosos o diferentes de los datos de entrenamiento;
- Múltiples componentes de IA interactúan entre sí, creando dependencias y comportamientos inesperados;
- Bucles de retroalimentación humano-IA que provienen de compromisos repetidos entre personas y el sistema de IA.
- Modelos de IA muy grandes (p. ej., modelos de transformadores)
- Modelos de IA que interactúan con otras partes de un sistema (p. ej., interfaz de usuario o algoritmo heurístico)
¿Cómo sabemos cuándo estos sistemas más avanzados son «suficientemente buenos» para su uso previsto? Al evaluar el rendimiento de los modelos de IA, a menudo nos basamos en métricas de rendimiento agregadas como el porcentaje de precisión. Pero esto ignora los muchos elementos, a menudo humanos, que componen un sistema de IA.
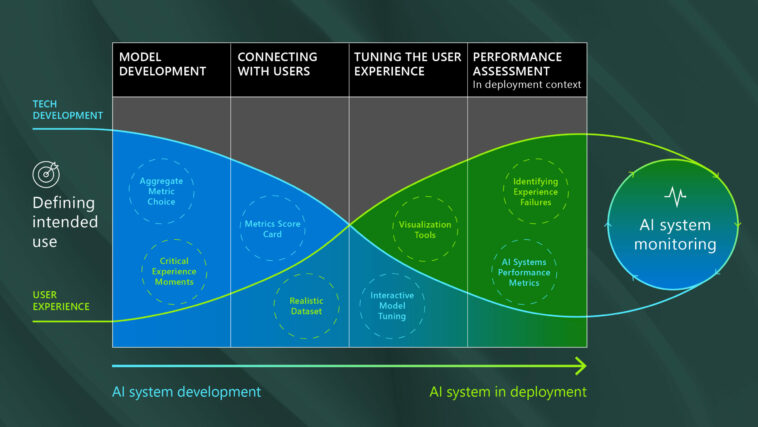
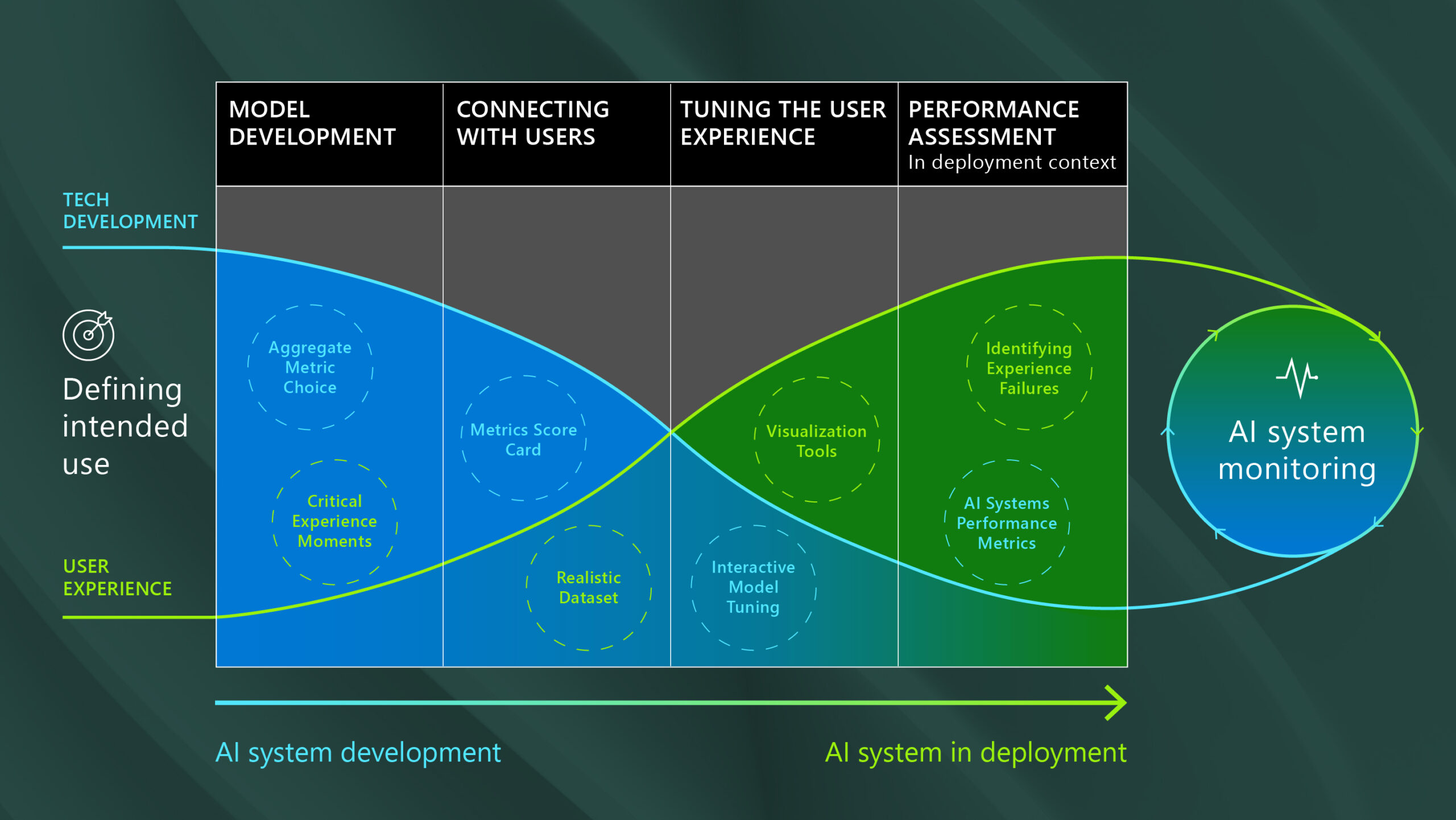
Nuestra investigación sobre lo que se necesita para crear experiencias de IA inclusivas y con visión de futuro ha demostrado que llegar a «lo suficientemente bueno» requiere múltiples enfoques de evaluación del desempeño en diferentes etapas del ciclo de vida del desarrollo, en función de datos realistas y necesidades clave de los usuarios (figura 1).
Cambiar gradualmente el énfasis de los ajustes iterativos en los propios modelos de IA hacia enfoques que mejoren el sistema de IA en su conjunto tiene implicaciones no solo en términos de cómo se evalúa el rendimiento, pero quién debe participar en el proceso de evaluación del desempeño. Involucrar (y capacitar) a expertos en dominios no técnicos antes (es decir, para elegir datos de prueba o definir métricas de experiencia) y en una mayor capacidad a lo largo del ciclo de vida del desarrollo puede mejorar la relevancia, la usabilidad y la confiabilidad del sistema de IA.
Mejores prácticas de evaluación del desempeño de PeopleLens
PeopleLens (figura 2) es una nueva tecnología de Microsoft diseñada para permitir que los niños ciegos de nacimiento experimenten la agencia social y desarrollen la gama de habilidades de atención social necesarias para iniciar y mantener interacciones sociales. Al funcionar con gafas inteligentes, brinda al usuario información continua y en tiempo real sobre las personas que lo rodean a través de audio espacial, ayudándolo a construir un mapa dinámico del paradero de los demás. Su tecnología subyacente es un sistema de inteligencia artificial complejo que utiliza varios algoritmos de visión por computadora para calcular, posar, identificar a las personas registradas y rastrear esas entidades a lo largo del tiempo.
PeopleLens ofrece una ilustración útil de la amplia gama de métodos de evaluación del desempeño y las personas necesarias para medir de manera integral su eficacia.

Primeros pasos: ¿modelo de IA o rendimiento del sistema de IA?
El cálculo de métricas de rendimiento agregadas en conjuntos de datos de referencia de código abierto puede demostrar la capacidad de una IA individual modelopero puede ser insuficiente cuando se aplica a una IA completa sistema. Puede ser tentador creer que una sola métrica de rendimiento agregada (como la precisión) puede ser suficiente para validar varios modelos de IA individualmente. Pero el rendimiento de dos modelos de IA en un sistema no se puede medir de manera integral mediante la simple suma de la métrica de rendimiento agregado de cada modelo.
Usamos dos modelos de IA para probar la precisión de PeopleLens para ubicar e identificar personas: el primero fue un modelo de pose de última generación que se usó para indicar la ubicación de las personas en una imagen. El segundo fue un novedoso algoritmo de reconocimiento facial que previamente demostró tener una precisión superior al 90%. A pesar del sólido desempeño histórico de estos dos modelos, cuando se aplicó a PeopleLens, el sistema de IA reconoció solo al 10 % de las personas de un conjunto de datos realista en el que las personas no siempre miraban a la cámara.
Este hallazgo ilustra que los sistemas de algoritmos múltiples son más que la suma de sus partes, lo que requiere enfoques específicos de evaluación del desempeño.
Conexión con la experiencia humana: cuadros de mando métricos y datos realistas
Los cuadros de mando de métricas, calculados en un conjunto de datos de referencia realista, ofrecen una forma de conectarse con la experiencia humana mientras el sistema de IA aún está experimentando una iteración técnica significativa. Un cuadro de mando de métricas puede combinar varias métricas para medir los aspectos del sistema que son más importantes para los usuarios.
Utilizamos diez métricas en el desarrollo de PeopleLens. Las dos métricas más valiosas fueron tiempo hasta la primera identificaciónque midió el tiempo que transcurrió desde que se vio a una persona en un marco hasta que el usuario escuchó el nombre de esa persona, y número de falsos positivos repetidosque midió la frecuencia con la que se producía un falso positivo en tres fotogramas o más seguidos dentro del conjunto de datos de referencia.
La primera métrica capturó la propuesta de valor central para el usuario: hacer que la agencia social sea la primera en saludar cuando alguien se acerca. El segundo era importante porque el sistema de IA autocorregiría las identificaciones erróneas individuales, mientras que los errores repetidos conducirían a una experiencia de usuario deficiente. Esto midió las ramificaciones de esa precisión en todo el sistema, en lugar de solo por cuadro.
Más allá de las métricas: uso de herramientas de visualización para afinar la experiencia del usuario
Si bien las métricas desempeñan un papel fundamental en el desarrollo de los sistemas de IA, se necesita una gama más amplia de herramientas para afinar la experiencia del usuario previsto. Es esencial que los equipos de desarrollo realicen pruebas en conjuntos de datos realistas para comprender cómo el sistema de IA genera la experiencia real del usuario. Esto es especialmente importante con sistemas complejos, donde múltiples modelos, bucles de retroalimentación humano-IA o datos impredecibles (p. ej., captura de datos controlada por el usuario) pueden hacer que el sistema de IA responda de manera impredecible.
Las herramientas de visualización pueden mejorar las herramientas estadísticas de arriba hacia abajo de los científicos de datos, ayudando a los expertos del dominio a contribuir al desarrollo del sistema. En PeopleLens, utilizamos herramientas de visualización personalizadas para comparar representaciones de la experiencia en paralelo con diferentes parámetros del modelo (figura 3). Aprovechamos estas visualizaciones para permitir que los expertos del dominio (en este caso, padres y maestros) detecten patrones de comportamiento extraño del sistema en los datos.
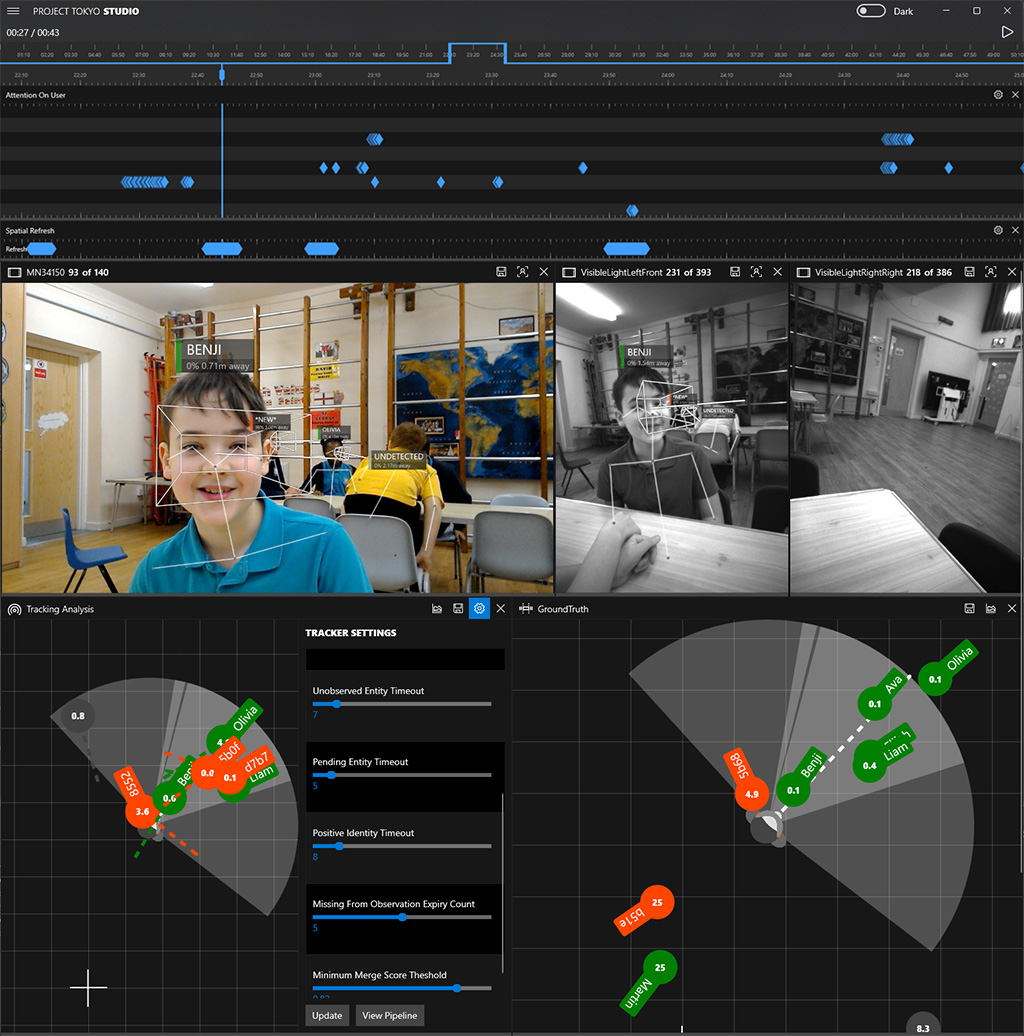
Rendimiento del sistema de IA en el contexto de la experiencia del usuario
Una experiencia de usuario solo puede ser tan buena como el sistema de IA subyacente. Probar el sistema de IA en un contexto realista, midiendo las cosas que son importantes para los usuarios, es una etapa crítica antes de una implementación generalizada. Sabemos, por ejemplo, que mejorar el rendimiento del sistema de IA no necesariamente se corresponde con un mejor rendimiento de los equipos de IA (referencia).
También sabemos que los bucles de retroalimentación de humano a IA pueden dificultar la medición del rendimiento de un sistema de IA. Esencialmente interacciones repetidas entre el sistema de IA y el usuario, estos bucles de retroalimentación pueden revelar (e intensificar) errores. También pueden, a través de una buena inteligibilidad, ser reparados por el usuario.
El sistema PeopleLens les dio a los usuarios comentarios sobre las ubicaciones de las personas y sus rostros. Una identificación perdida (p. ej., porque la persona está mirando un cofre en lugar de una cara) se puede resolver una vez que el usuario responde a la retroalimentación (p. ej., mirando hacia arriba). Este ejemplo nos muestra que no necesitamos centrarnos en la identificación perdida, ya que se resolverá mediante el circuito de retroalimentación humano-IA. Sin embargo, los usuarios estaban muy perplejos por la identificación de personas que ya no estaban presentes y, por lo tanto, las evaluaciones de desempeño debían centrarse en estas identificaciones erróneas de falsos positivos.
-
- Se deben utilizar múltiples métodos de evaluación del desempeño en el desarrollo del sistema de IA. En contraste con el desarrollo de modelos de IA individuales, las métricas de rendimiento agregadas generales son un componente pequeño, relevante principalmente en las primeras etapas de desarrollo.
- La documentación del rendimiento del sistema de IA debe incluir una variedad de enfoques, desde cuadros de mando de métricas hasta métricas de rendimiento del sistema para una experiencia de usuario implementada, hasta herramientas de visualización.
- Los expertos de dominio juegan un papel importante en la evaluación del desempeño, comenzando temprano en el ciclo de vida del desarrollo. Los expertos en dominios a menudo no están preparados o capacitados para la participación profunda óptima en el desarrollo de sistemas de IA.
- Las herramientas de visualización son tan importantes como las métricas a la hora de crear y documentar un sistema de IA para un uso específico previsto. Es fundamental que los expertos del dominio tengan acceso a estas herramientas como tomadores de decisiones clave en la implementación del sistema de IA.
Reuniéndolo todo
Para los sistemas de IA complejos, los métodos de evaluación del desempeño cambian a lo largo del ciclo de vida de desarrollo de maneras que difieren de los modelos de IA individuales. Cambiar las técnicas de evaluación del desempeño de una innovación técnica rápida que requiere métricas agregadas fáciles de calcular al comienzo del proceso de desarrollo, a las métricas de desempeño que reflejan los atributos críticos del sistema de IA que conforman la experiencia del usuario hacia el final del desarrollo ayuda a cada tipo de parte interesada definir de manera precisa y colectiva lo que es ‘suficientemente bueno’ para lograr el uso previsto.
Es útil que los desarrolladores recuerden que la evaluación del desempeño no es un objetivo final en sí mismo; es un proceso que define cómo el sistema ha alcanzado su mejor estado y si ese estado está listo para su implementación. El proceso de evaluación del desempeño debe incluir una amplia gama de partes interesadas, incluidos expertos en el dominio, que pueden necesitar nuevas herramientas para cumplir funciones críticas (a veces inesperadas) en el desarrollo y la implementación de un sistema de IA.

