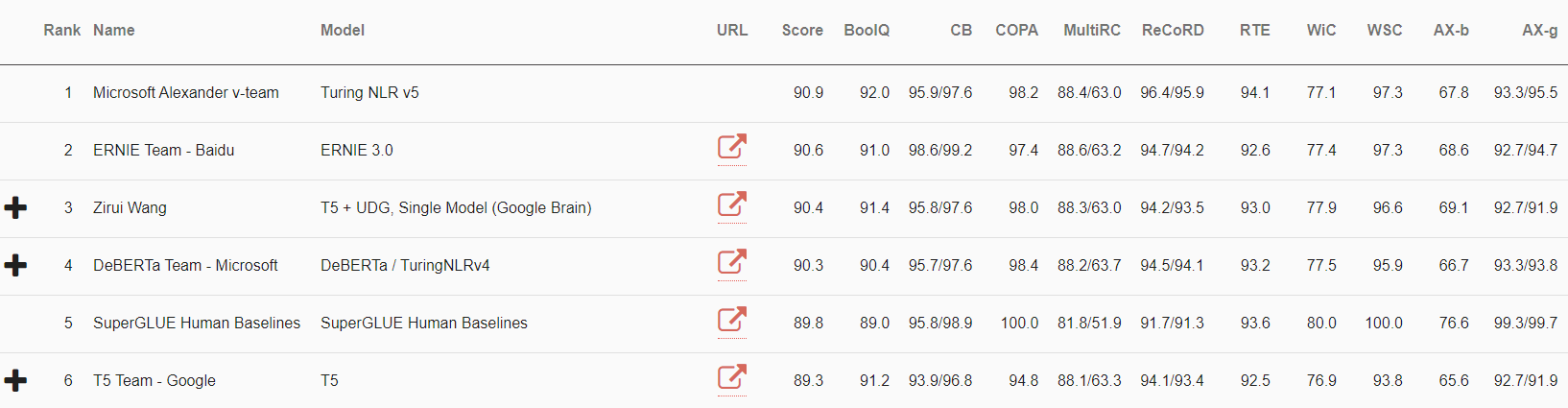
Como parte de Microsoft IA a escala, la familia Turing de modelos de PNL se está utilizando a escala en Microsoft para permitir la próxima generación de experiencias de inteligencia artificial. Hoy dia, nos complace anunciar que el último modelo de Microsoft Turing (T-NLRv5) es el estado del arte en la cima de las tablas de clasificación SuperGLUE y GLUE, superando aún más el desempeño humano y otros modelos. En particular, T-NLRv5 logró por primera vez la paridad humana en MNLI y RTE en el punto de referencia GLUE, las dos últimas tareas GLUE que la paridad humana aún no había cumplido. Además, T-NLRv5 es más eficiente que los modelos recientes de preentrenamiento, logrando una efectividad comparable con un 50% menos de parámetros y costos de cómputo de preentrenamiento.

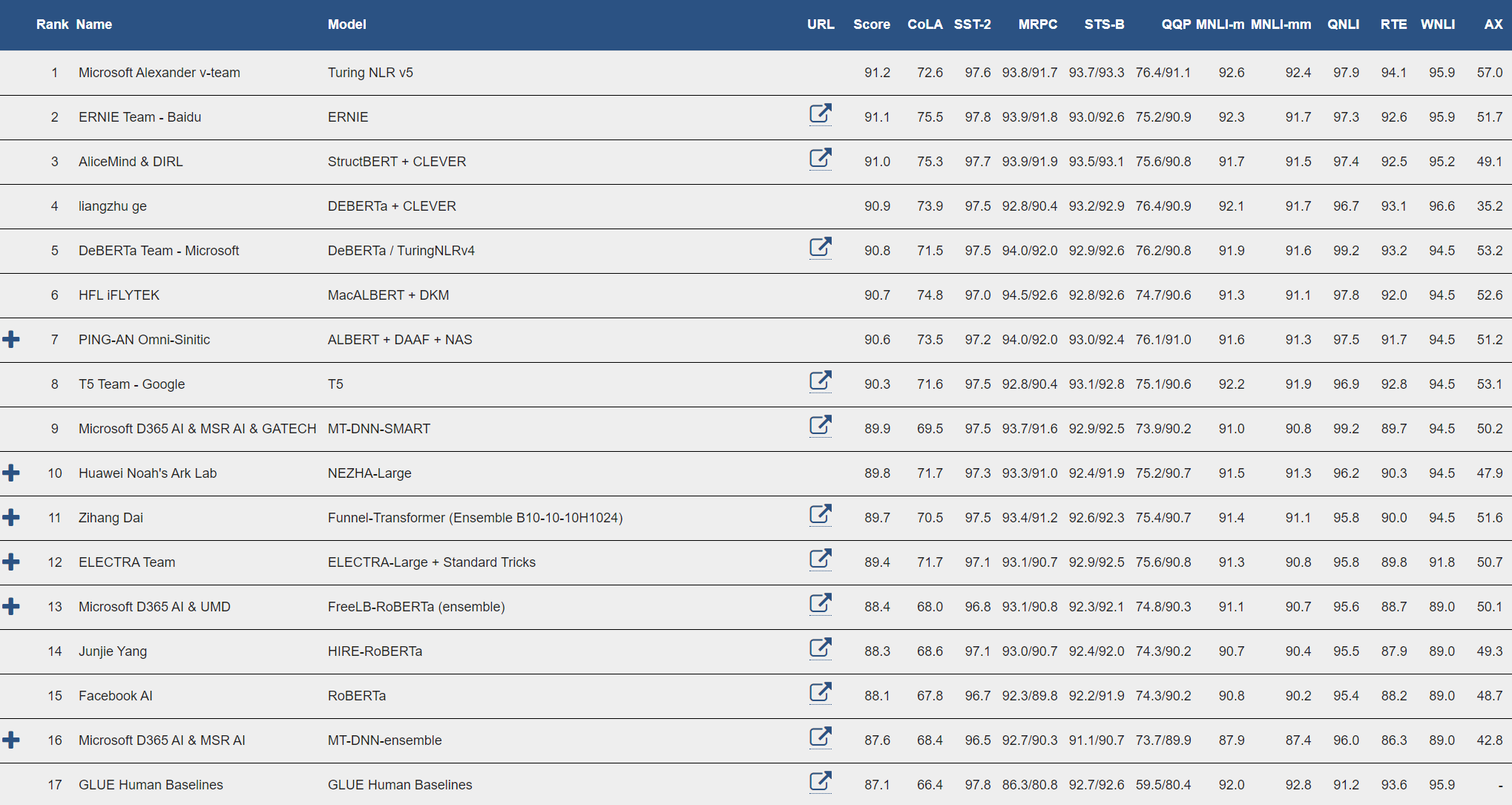
La representación del lenguaje natural de Turing (T-NLRv5) integra algunas de las mejores técnicas de modelado desarrolladas por Microsoft Research, Azure AI y Microsoft Turing. Los modelos se entrenan previamente a gran escala utilizando un marco de entrenamiento eficiente basado en FastPT y DeepSpeed. Estamos entusiasmados de traer nuevas mejoras de inteligencia artificial a los productos de Microsoft utilizando estas técnicas de vanguardia.
Arquitectura del modelo y tarea de preentrenamiento
T-NLRv5 se basa en gran medida en nuestro trabajo reciente, COCO-LM, una evolución natural del paradigma de preentrenamiento que converge los beneficios de los modelos de estilo ELECTRA y el preentrenamiento del modelo de lenguaje correctivo. Como se ilustra en la Figura 2, T-NLRv5 emplea un modelo de lenguaje de transformador auxiliar para corromper una secuencia de texto de entrada, y el modelo de transformador principal se entrena previamente usando el modelo de lenguaje correctivo tarea, que consiste en detectar y corregir tokens reemplazados por el modelo auxiliar. Esto aumenta la familia de modelos ELECTRA con capacidad de modelado del lenguaje, reuniendo los beneficios del preentrenamiento con señales adversas generadas a partir del modelo auxiliar y la capacidad de modelado del lenguaje, que es útil para el aprendizaje basado en pautas.
También aprovechamos el conjunto de datos de capacitación y la canalización de procesamiento de datos optimizada para desarrollar versiones anteriores de T-NLR, incluidas DeBERTa y UniLM, así como las optimizaciones de implementación de otros esfuerzos de investigación de preentrenamiento de Microsoft, como TUPE.
Otra propiedad clave de T-NLRv5 es que mantiene la efectividad del modelo en tamaños más pequeños, por ejemplo, base y tamaño grande con unos pocos cientos de millones de parámetros, a tamaños más grandes con miles de millones de parámetros. Esto se logra mediante una cuidadosa selección de técnicas para mantener la simplicidad del modelo y la estabilidad de la optimización. Deshabilitamos la deserción en el modelo auxiliar para que el preentrenamiento del modelo auxiliar y la generación de los datos de entrenamiento del modelo principal se realicen en una sola pasada. También deshabilitamos la tarea de aprendizaje contrastivo secuencial en COCO-LM para reducir el costo de computación. Esto nos permite ceñirnos a la arquitectura de transformadores de norma posterior a la capa que nos permite entrenar redes de transformadores más profundas de manera más completa.
Ampliación eficiente de la formación previa del modelo de lenguaje
El entrenamiento de modelos neuronales de mil millones de parámetros puede ser prohibitivamente costoso tanto en tiempo como en costos de computación. Esto produce un ciclo experimental largo que ralentiza los desarrollos científicos y plantea preocupaciones de costo-beneficio. Al hacer T-NLRv5, aprovechamos dos enfoques para mejorar su eficiencia de escala para garantizar un uso óptimo de los parámetros del modelo y el cálculo previo al entrenamiento.
Núcleos CUDA personalizados para una precisión mixta. Aprovechamos los kernels CUDA personalizados desarrollados para Fast PreTraining (FastPT), que están personalizados para la arquitectura del transformador y optimizados para la velocidad en el preentrenamiento de precisión mixta (FP16). Esto no solo mejora significativamente la eficiencia del entrenamiento del transformador y la inferencia en un 20%, sino que también proporciona una mejor estabilidad numérica en el entrenamiento de precisión mixta. Esta última es una de las necesidades más importantes a la hora de entrenar modelos de representación lingüística con miles de millones de parámetros.
Optimizador ZeRO. Al escalar T-NLRv5 a miles de millones de parámetros, incorporamos nuestro Cero técnica optimizadora de DeepSpeed, descrita en una publicación de blog anterior, para reducir la huella de memoria de la GPU de los modelos de preentrenamiento en procesos de preentrenamiento en paralelo de varias máquinas. Específicamente, la versión T-NLRv5 XXL (5.400 millones) utiliza la etapa 1 del optimizador ZeRO (partición de la etapa del optimizador), que reduce cinco veces la huella de memoria de la GPU.
Lograr la mejor efectividad y eficiencia simultáneamente
Al combinar las técnicas de modelado y las mejoras de infraestructura anteriores, T-NLRv5 proporciona la mejor efectividad y eficiencia simultáneamente en varios puntos de compensación. Según nuestro leal saber y entender, T-NLRv5 logra una eficacia de vanguardia en varios tamaños de modelo y costos de computación previos a la capacitación.
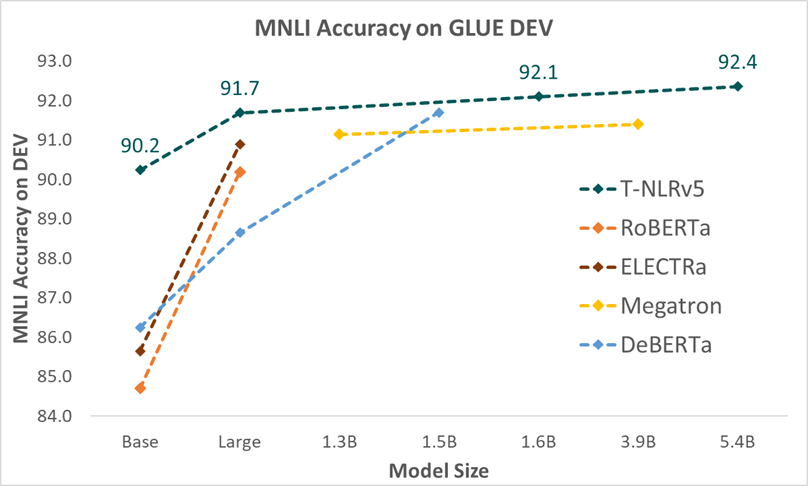
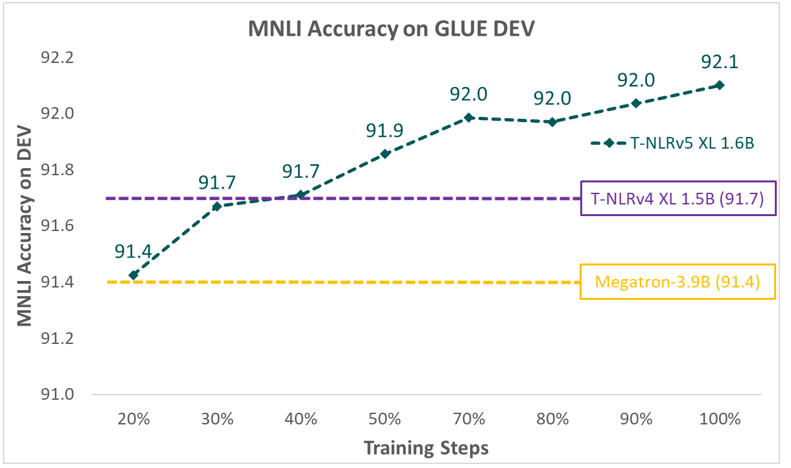
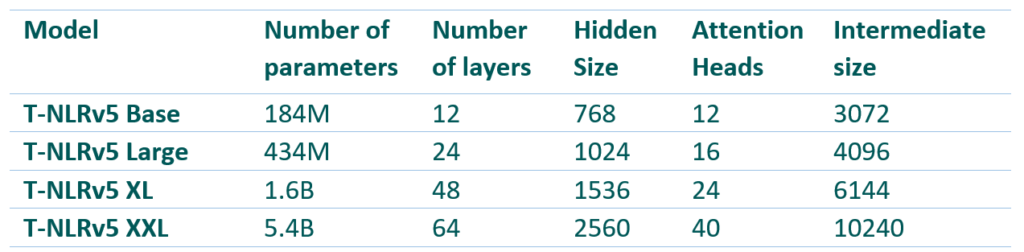
Las configuraciones del modelo para las variantes de T-NLRv5 se muestran en la Tabla 1. Como se muestra en la Figura 4 y la Figura 5, cuando se mide en MNLI, una de las tareas más estables en GLUE, variantes de T-NLRv5 con sustancialmente menos parámetros o pasos de computación a menudo significativamente supere los modelos previos de formación previa con mayores costes de formación previa. La versión base de T-NLRv5 supera a RoBERTa Large utilizando el 50% de los parámetros. Usando 434 millones de parámetros, T-NLRv5 Large funciona a la par con DeBERTa XL (1.5 mil millones de parámetros) y supera al codificador Megatron con 3.9 mil millones de parámetros. T-NLRv5 también mejora significativamente la eficiencia de preentrenamiento: alcanza la precisión de nuestro último modelo XL, T-NLRv4-1.5B, con solo un 40% de pasos de preentrenamiento utilizando los mismos corpus de formación y entornos informáticos.
Adaptación robusta del modelo
La solidez es importante para que un modelo funcione bien en muestras de prueba, que son dramáticamente diferentes de los datos de entrenamiento. En este trabajo, utilizamos dos métodos para mejorar la solidez de la adaptación de T-NLRv5 a las tareas posteriores. El primer método mejora la robustez del modelo a través de PDR (regularización diferencial posterior), que regulariza la diferencia posterior del modelo entre entradas limpias y ruidosas durante el entrenamiento del modelo. El segundo método es el aprendizaje multitarea, como en la red neuronal profunda multitarea (MT-DNN), que mejora la solidez del modelo al aprender representaciones en múltiples tareas NLU. MT-DNN no solo aprovecha grandes cantidades de datos entre tareas, sino que también se beneficia de un efecto de regularización que conduce a representaciones más generales para adaptarse a nuevas tareas y dominios.
Con estas robustas técnicas de adaptación de modelos, nuestro modelo T-NLRv5 XXL es el primero en alcanzar la paridad humana en MNLI en precisión de prueba (92.5 versus 92.4), la tarea más informativa en GLUE, mientras que solo usa un solo modelo y una sola tarea de ajuste fino , es decir, sin conjunto.
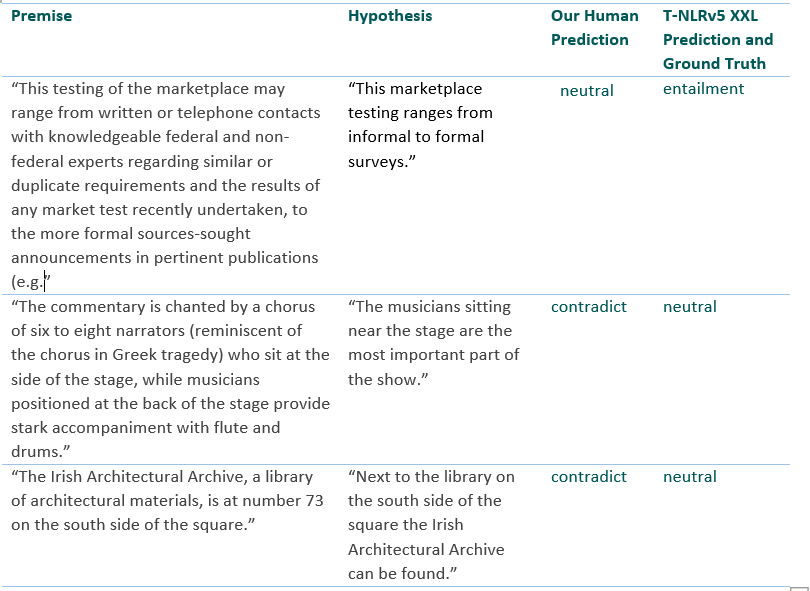
La Tabla 2 presenta algunos ejemplos del conjunto de errores de coincidencia de desarrollo de MNLI donde el modelo T-NLRv5 XXL puede predecir la etiqueta correcta, pero uno de nuestros autores hizo una predicción incorrecta. Estos son ejemplos bastante difíciles y nos complace ver que T-NLRv5 XXL puede completar la tarea con precisión.
T-NLRv5: Información de publicación
Haremos que T-NLRv5 y sus capacidades estén disponibles de la misma manera que con otros modelos de Microsoft Turing.
Aprovecharemos sus capacidades mejoradas para mejorar aún más la ejecución de tareas de lenguaje populares en AServicios cognitivos de zure. Los clientes se beneficiarán automáticamente de estos.
Los clientes interesados en utilizar modelos de Turing para su propia tarea específica pueden enviar una solicitud para unirse al Vista previa privada de Turing. Finalmente, pondremos T-NLRv5 a disposición de los investigadores para proyectos colaborativos a través del Programa Académico Microsoft Turing.
Aprende más:
Explore una demostración interactiva con modelos de IA a escala
Obtenga más información sobre las capas de tecnología que impulsan los modelos de IA a escala
Conclusión: construir y democratizar una IA más inclusiva
La familia de modelos de Microsoft Turing juega un papel importante en la entrega de experiencias de inteligencia artificial basadas en el lenguaje en los productos de Microsoft. T-NLRv5, que supera aún más el desempeño humano en las tablas de clasificación de SuperGLUE y GLUE, reafirma nuestro compromiso de seguir superando los límites de la PNL y de mejorar continuamente estos modelos para que, en última instancia, podamos brindar experiencias de productos de inteligencia artificial más inteligentes y responsables a nuestros clientes.
Agradecemos sus comentarios y esperamos poder compartir más novedades en el futuro.
