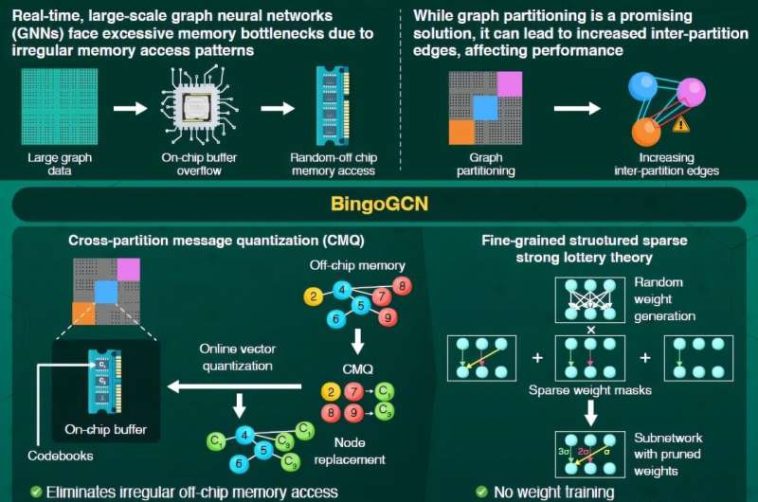

BingOCGN emplea la cuantización de mensajes de partición cruzada para resumir el flujo de mensajes entre partiticiones, que elimina la necesidad de acceso irregular de memoria fuera del chip y utiliza un algoritmo de entrenamiento basado en la teoría de la lotería fuerte estructurada de grano fino para mejorar la eficiencia computacional. Crédito: Instituto de Ciencias Tokio, Japón
Bingocgn, un acelerador de red neuronal de gráficos escalable y eficiente que permite la inferencia de gráficos a gran escala en tiempo real a través de la partición gráfica, ha sido desarrollada por investigadores del Instituto de Ciencias Tokio, Japón. Este marco innovador utiliza una innovadora técnica de cuantificación de mensajes de partición cruzada y un nuevo algoritmo de capacitación para reducir significativamente las demandas de memoria y aumentar la eficiencia computacional y energética.
Las redes neuronales Graph (GNN) son potentes modelos de inteligencia artificial (AI) diseñados para analizar datos de gráficos complejos y no estructurados. En tales datos, las entidades se representan como nodos y relaciones entre ellos son los bordes. Los GNN se han empleado con éxito en muchas aplicaciones del mundo real, incluidas las redes sociales, el descubrimiento de medicamentos, la conducción autónoma y los sistemas de recomendación. A pesar de su potencial, alcanzar la inferencia de GNN en tiempo real, a gran escala, crítico para tareas como la conducción autónoma, sigue siendo desafiante.
Los gráficos grandes requieren una memoria extensa, a menudo desbordando buffers en chip, que son regiones de memoria integradas en un chip. Esto obliga al sistema a confiar en la memoria fuera de chip más lenta. Dado que los datos de los gráficos se almacenan de manera irregular, esto conduce a patrones de acceso de memoria irregular, degradando la eficiencia computacional y el aumento del consumo de energía.
Una solución prometedora es la partición de gráficos, donde los gráficos grandes se dividen en gráficos más pequeños, cada uno asignó su propio búfer en chip. Esto da como resultado patrones de acceso de memoria más localizados y requisitos de tamaño de búfer más pequeños a medida que aumenta el número de particiones.
Sin embargo, esto es solo parcialmente efectivo. A medida que crece el número de particiones, los vínculos entre las particiones y los bordes interpartitionados crecen sustancialmente. Esto requiere un mayor acceso de memoria fuera del chip, limitando la escalabilidad.
Para abordar este problema, un equipo de investigación dirigido por el profesor asociado Daichi Fujiki del Instituto de Ciencia Tokio, Japón, desarrolló un acelerador de GNN novedoso, escalable y eficiente llamado Bingocgn. «Bingocgn emplea una nueva técnica llamada cuantificación de mensajes de partición cruzada (CMQ) que resume el flujo de mensajes entre partiticiones, eliminando el acceso irregular fuera de la memoria fuera del chip y un nuevo algoritmo de capacitación que aumenta significativamente la eficiencia computacional», explica Fujiki. Su recomendaciones se presentará en los procedimientos del 52º Simposio Internacional Anual sobre Arquitectura de Computadora (ISCA ’25) Del 21 al 25 de junio de 2025.
CMQ utiliza una técnica llamada cuantización de vectores, que agrupa los nodos entre partiticiones y los representa utilizando puntos llamados centroides. Los nodos se agrupan según su distancia, con cada nodo asignado a su centroide más cercano. Para una partición dada, estos centroides reemplazan los nodos interpartición, comprimiendo efectivamente los datos de nodo. Los centroides se almacenan en tablas llamadas libros de códigos, que residen directamente en el búfer en chip.
CMQ, por lo tanto, permite la comunicación entre participaciones sin la necesidad de acceso irregular y costoso fuera del chip. Además, dado que este método requiere una lectura y escritura frecuentes de nodos y centroides para la memoria, este método emplea una estructura jerárquica similar a un árbol para libros de códigos, con centroides de padres e hijos, reduciendo las demandas de cálculo mientras mantiene la precisión.
Si bien CMQ resuelve el cuello de botella de memoria, cambia la carga a la cálculo. Para contrarrestar esto, los investigadores desarrollaron un nuevo algoritmo de entrenamiento basado en una fuerte teoría de boletos de lotería. En este método, el GNN se inicializa con pesos aleatorios, se genera en chip usando generadores de números aleatorios.
Luego, los pesos innecesarios se podan usando una máscara, formando una sub-red más pequeña, menos densa o escasa que tiene una precisión comparable a la GNN completa pero es significativamente más eficiente para calcular. Además, este método incorpora la poda estructurada de grano fino (FG), que utiliza múltiples máscaras con diferentes niveles de escasez, para construir una sub-red aún más pequeña y más eficiente.
«A través de estas técnicas, Bingocgn logra una inferencia de GNN de alto rendimiento incluso en datos de gráficos finamente divididos, que anteriormente se consideraban difíciles», comenta Fujiki. «Nuestra implementación de hardware, probada en siete conjuntos de datos del mundo real, logra hasta 65 veces la aceleración y un aumento de hasta 107 veces en la eficiencia energética en comparación con el acelerador de última generación Flowgnn».
Este avance abre la puerta al procesamiento en tiempo real de datos de gráficos a gran escala, allanando el camino para diversas aplicaciones del mundo real de GNN.
Más información:
Jialle Yan et al, Bingogcn: Hacia la aceleración de GNN escalable y eficiente con partición de grano fino y SLT, Actas del 52º Simposio Internacional Anual sobre Arquitectura de Computadora (2025). Doi: 10.1145/3695053.3731115
Citación: El nuevo marco reduce el uso de la memoria y aumenta la eficiencia energética para el análisis de gráficos AI a gran escala (2025, 23 de junio) recuperado el 25 de julio de 2025 de https://techxplore.com/news/2025-06-framework-memory-usage-boosts-energy.html
Este documento está sujeto a derechos de autor. Además de cualquier trato justo con el propósito de estudio o investigación privada, no se puede reproducir ninguna parte sin el permiso por escrito. El contenido se proporciona solo para fines de información.

