. Doi: 10.3390/electronics13234683")
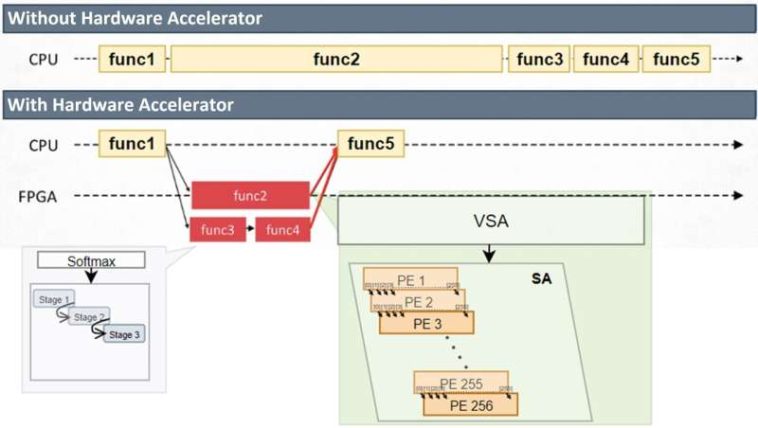
Diferencias en los procesos con y sin aceleradores de hardware. Crédito: Electrónica (2024). Doi: 10.3390/electronics13234683
Los modelos de idiomas grandes (LLM) como Bert y GPT están impulsando los importantes avances en la inteligencia artificial, pero su tamaño y complejidad generalmente requieren poderosos servidores e infraestructura en la nube. Ejecutar estos modelos directamente en los dispositivos, sin depender del cálculo externo, ha seguido siendo un desafío técnico difícil.
Un equipo de investigación de la Universidad de Sejong ha desarrollado una nueva solución de hardware que puede ayudar a cambiar eso. El trabajo es publicado en el diario Electrónica.
Su unidad de acelerador de transformador escalable (STAU) está diseñada para ejecutar varios modelos de lenguaje basados en transformadores de manera eficiente en los sistemas integrados. Se adapta dinámicamente a diferentes tamaños de entrada y estructuras de modelos, lo que lo hace especialmente adecuado para la IA en el dispositivo en tiempo real.
En el corazón del Stau hay una arquitectura variable de matriz sistólica (VSA), que realiza operaciones de matriz, la carga de trabajo central en los modelos de transformadores, de una manera que escala con la longitud de la secuencia de entrada. Al alimentar los datos de entrada fila por fila y cargando pesos en paralelo, el sistema reduce los puestos de memoria y mejora el rendimiento. Esto es particularmente importante para los LLM, donde las longitudes de las oraciones y las secuencias de tokens varían ampliamente entre las tareas.
En las pruebas de referencia publicadas en Electronics, el acelerador demostró una aceleración de 3.45 × sobre la ejecución de solo CPU mientras mantenía más del 97% de precisión numérica. También redujo el tiempo de cálculo total en más del 68% cuando se procesa secuencias más largas.
Desde entonces, las optimizaciones continuas han mejorado aún más el rendimiento del sistema: según el equipo, las pruebas internas recientes lograron una aceleración de hasta 5.18 ×, destacando la escalabilidad a largo plazo de la arquitectura.
-

Arquitectura del módulo superior. Crédito: Electrónica (2024). Doi: 10.3390/electronics13234683
-

Elemento de procesamiento (PE) y arquitectura variable de matriz sistólica (VSA). Crédito: Electrónica (2024). Doi: 10.3390/electronics13234683
Los investigadores también rediseñaron una parte crítica de la tubería del transformador: la función Softmax. Por lo general, un cuello de botella debido a su dependencia de la exponenciación y la normalización, se rediseñó utilizando un enfoque liviano Radix-2 que se basa en las operaciones de cambio y agregado. Esto reduce la complejidad del hardware sin comprometer la calidad de la salida.
Para simplificar aún más el cálculo, el sistema utiliza un formato de punto flotante personalizado de 16 bits específicamente adaptado para las cargas de trabajo del transformador. Este formato elimina la necesidad de la normalización de la capa, otro cuello de botella de rendimiento común, y contribuye a un data de datos más eficiente y optimizado.
STAU se implementó en un FPGA Xilinx (VMK180) y se controló por un procesador Cortex-R5 de brazo integrado. Este diseño híbrido permite a los desarrolladores admitir una gama de modelos de transformadores, incluidos los utilizados en LLM, simplemente actualizando el software que se ejecuta en el procesador, sin requerido modificaciones de hardware.
El equipo ve su trabajo como un paso para hacer que los modelos de lenguaje avanzados sean más accesibles y desplegables en una gama más amplia de plataformas, incluidos dispositivos móviles, dispositivos portátiles y sistemas informáticos de borde, donde la ejecución de IA en tiempo real, la privacidad y la respuesta de baja latencia son esenciales.
«La arquitectura de Stau muestra que los modelos de transformadores, incluso los grandes, pueden hacerse prácticos para aplicaciones en el dispositivo», dijo el autor principal Seok-Woo Chang. «Proporciona una base para construir sistemas inteligentes que sean escalables y eficientes».
Más información:
Seok-woo Chang et al, acelerador de transformador escalable con matriz sistólica variable para múltiples modelos en aplicaciones de asistente de voz, Electrónica (2024). Doi: 10.3390/electronics13234683
Citación: El acelerador de transformador escalable permite la ejecución en el dispositivo de modelos de idiomas grandes (2025, 21 de julio) Recuperado el 25 de julio de 2025 de https://techxplore.com/news/2025-07-scalable-lables-device-large-language.html
Este documento está sujeto a derechos de autor. Además de cualquier trato justo con el propósito de estudio o investigación privada, no se puede reproducir ninguna parte sin el permiso por escrito. El contenido se proporciona solo para fines de información.

