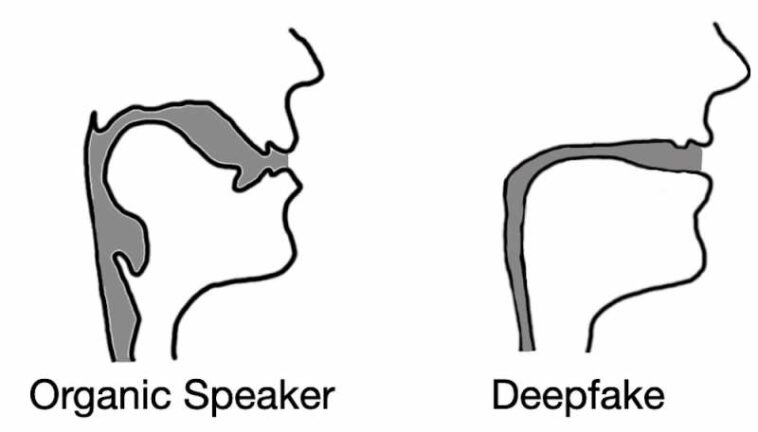

El audio falso a menudo da como resultado reconstrucciones del tracto vocal que se asemejan a pajitas para beber en lugar de tractos vocales biológicos. Crédito: Logan Blue et al., CC BY-ND
Imagina el siguiente escenario. Suena un teléfono. Un oficinista responde y escucha a su jefe, presa del pánico, decirle que olvidó transferir dinero al nuevo contratista antes de irse y necesita que él lo haga. Ella le da la información de la transferencia bancaria y, con el dinero transferido, se ha evitado la crisis.
El trabajador se recuesta en su silla, respira hondo y observa cómo su jefe entra por la puerta. La voz al otro lado de la llamada no era su jefe. De hecho, ni siquiera era un humano. La voz que escuchó fue la de un audio falso, una muestra de audio generada por una máquina diseñada para sonar exactamente como su jefe.
Ataques como este usando audio grabado ya han ocurridoy las falsificaciones profundas de audio conversacional podrían no estar muy lejos.
Deepfakes, tanto de audio como de video, solo han sido posibles con el desarrollo de tecnologías sofisticadas de aprendizaje automático en los últimos años. Deepfakes ha traído consigo un nuevo nivel de incertidumbre en torno a los medios digitales. Para detectar falsificaciones profundas, muchos investigadores han recurrido al análisis de artefactos visuales (fallas mínimas e inconsistencias) que se encuentran en las falsificaciones profundas de video.
Las falsificaciones profundas de audio potencialmente representan una amenaza aún mayor, porque las personas a menudo se comunican verbalmente sin video, por ejemplo, a través de llamadas telefónicas, radio y grabaciones de voz. Estas comunicaciones de solo voz amplían en gran medida las posibilidades de que los atacantes utilicen deepfakes.
Para detectar falsificaciones profundas de audio, nosotros y nuestros colegas investigadores en la Universidad de Florida han desarrollado una técnica que mide las diferencias acústicas y dinámicas de fluidos entre muestras de voz creadas orgánicamente por hablantes humanos y aquellas generadas sintéticamente por computadoras.
Voces orgánicas vs sintéticas
Los seres humanos vocalizan forzando el aire sobre las diversas estructuras del tracto vocal, incluidas las cuerdas vocales, la lengua y los labios. Al reorganizar estas estructuras, altera las propiedades acústicas de su tracto vocal, lo que le permite crear más de 200 sonidos o fonemas distintos. Sin embargo, la anatomía humana limita fundamentalmente el comportamiento acústico de estos diferentes fonemas, lo que da como resultado una gama relativamente pequeña de sonidos correctos para cada uno.
Por el contrario, las falsificaciones profundas de audio se crean permitiendo primero que una computadora escuche las grabaciones de audio de un hablante de la víctima objetivo. Dependiendo de las técnicas exactas utilizadas, la computadora Es posible que necesite escuchar tan solo de 10 a 20 segundos de audio.. Este audio se utiliza para extraer información clave sobre los aspectos únicos de la voz de la víctima.
El atacante selecciona una frase para que hable el deepfake y luego, utilizando un algoritmo modificado de texto a voz, genera una muestra de audio que suena como si la víctima dijera la frase seleccionada. Este proceso de creación de una sola muestra de audio falsificada se puede lograr en cuestión de segundos, lo que potencialmente permite a los atacantes suficiente flexibilidad para usar la voz falsa en una conversación.
Detección de falsificaciones profundas de audio
El primer paso para diferenciar el habla producida por humanos del habla generada por deepfakes es comprender cómo modelar acústicamente el tracto vocal. Afortunadamente, los científicos tienen técnicas para estimar lo que alguien, o algún ser, como un dinosaurio— sonaría basado en las medidas anatómicas de su tracto vocal.
Hicimos al revés. Al invertir muchas de estas mismas técnicas, pudimos extraer una aproximación del tracto vocal de un hablante durante un segmento del habla. Esto nos permitió observar de manera efectiva la anatomía del hablante que creó la muestra de audio.
A partir de aquí, planteamos la hipótesis de que las muestras de audio deepfake no estarían limitadas por las mismas limitaciones anatómicas que tienen los humanos. En otras palabras, el análisis de muestras de audio falsificadas simulaba formas del tracto vocal que no existen en las personas.
Los resultados de nuestras pruebas no solo confirmaron nuestra hipótesis, sino que revelaron algo interesante. Al extraer estimaciones del tracto vocal de un audio falso, descubrimos que las estimaciones a menudo eran cómicamente incorrectas. Por ejemplo, era común que el audio deepfake diera como resultado tractos vocales con el mismo diámetro relativo y la misma consistencia que una pajilla para beber, en contraste con los tractos vocales humanos, que son mucho más anchos y de forma más variable.
Esta realización demuestra que el audio deepfake, incluso cuando convence a los oyentes humanos, está lejos de ser indistinguible del habla generada por humanos. Al estimar la anatomía responsable de crear el discurso observado, es posible identificar si el audio fue generado por una persona o una computadora.
por qué esto importa
El mundo de hoy está definido por el intercambio digital de medios e información. Todo, desde noticias hasta entretenimiento y conversaciones con seres queridos, generalmente ocurre a través de intercambios digitales. Incluso en su infancia, los videos y audios falsos socavan la confianza que las personas tienen en estos intercambios, limitando efectivamente su utilidad.
Si el mundo digital va a seguir siendo un recurso crítico para la información en la vida de las personas, las técnicas efectivas y seguras para determinar la fuente de una muestra de audio son cruciales.
Identificar grabaciones de voz falsas
Este artículo se vuelve a publicar de La conversación bajo una licencia Creative Commons. Leer el artículo original.![]()
Citación: Deepfake audio tiene una clave: los investigadores usan dinámica de fluidos para detectar voces de impostores artificiales (21 de septiembre de 2022) recuperado el 21 de septiembre de 2022 de https://techxplore.com/news/2022-09-deepfake-audio-fluid-dynamics-artificial .html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.

