
|
|
Hoy anunciamos la generación de conjuntos de datos sintéticos que mejoran la privacidad para AWS Clean Rooms, una nueva capacidad que las organizaciones y sus socios pueden utilizar para generar conjuntos de datos sintéticos que mejoran la privacidad a partir de sus datos colectivos para entrenar modelos de aprendizaje automático (ML) de regresión y clasificación. Puede utilizar esta característica para generar conjuntos de datos de entrenamiento sintéticos que conserven los patrones estadísticos de los datos originales, sin que el modelo tenga acceso a los registros originales, lo que abre nuevas oportunidades para el entrenamiento de modelos que antes no eran posibles debido a cuestiones de privacidad.
Al crear modelos de aprendizaje automático, los científicos y analistas de datos suelen enfrentarse a una tensión fundamental entre la utilidad de los datos y la protección de la privacidad. El acceso a datos granulares de alta calidad es esencial para entrenar modelos precisos que puedan reconocer tendencias, personalizar experiencias e impulsar resultados comerciales. Sin embargo, el uso de datos granulares, como datos de eventos a nivel de usuario de múltiples partes, plantea importantes preocupaciones sobre la privacidad y desafíos de cumplimiento. Las organizaciones quieren responder preguntas como “¿Qué características indican una conversión de cliente de alta probabilidad?”, pero la capacitación sobre las señales a nivel individual a menudo entra en conflicto con las políticas de privacidad y los requisitos regulatorios.
Generación de conjuntos de datos sintéticos que mejoran la privacidad para aprendizaje automático personalizado
Para abordar este desafío, estamos introduciendo la generación de conjuntos de datos sintéticos que mejoran la privacidad en AWS Clean Rooms ML, que las organizaciones pueden usar para crear versiones sintéticas de conjuntos de datos confidenciales que se pueden usar de manera más segura para el entrenamiento de modelos de ML. Esta capacidad utiliza técnicas avanzadas de aprendizaje automático para generar nuevos conjuntos de datos que mantienen las propiedades estadísticas de los datos originales y al mismo tiempo desidentifican a los sujetos de los datos de origen originales.
Técnicas tradicionales de anonimización como enmascaramiento Todavía conlleva el riesgo de volver a identificar a las personas en un conjunto de datos; conocer los atributos de una persona, como el código postal y la fecha de nacimiento, puede ser suficiente para identificarlos con los datos del censo. La generación de conjuntos de datos sintéticos que mejoran la privacidad aborda este riesgo mediante un enfoque fundamentalmente diferente. El sistema entrena un modelo que aprende los patrones estadísticos esenciales del conjunto de datos original, luego genera registros sintéticos muestreando valores del conjunto de datos original y usando el modelo para predecir la columna de valores predichos. En lugar de simplemente copiar o alterar los datos originales, el sistema utiliza una técnica de reducción de la capacidad del modelo para mitigar el riesgo de que el modelo memorice información sobre los individuos en los datos de entrenamiento. El conjunto de datos sintéticos resultante tiene el mismo esquema y características estadísticas que los datos originales, lo que lo hace adecuado para entrenar modelos de clasificación y regresión. Este enfoque reduce cuantificablemente el riesgo de reidentificación.
Las organizaciones que utilizan esta capacidad tienen control sobre los parámetros de privacidad, incluida la cantidad de ruido aplicado y el nivel de protección contra la membresía. ataques de inferenciadonde un adversario intenta determinar si los datos de un individuo específico se incluyeron en el conjunto de entrenamiento. Después de generar el conjunto de datos sintéticos, AWS Clean Rooms proporciona métricas detalladas para ayudar a los clientes y sus equipos de cumplimiento a comprender la calidad del conjunto de datos sintéticos en dos dimensiones críticas: fidelidad a los datos originales y preservación de la privacidad. La puntuación de fidelidad utiliza Divergencia KL para medir qué tan similares son los datos sintéticos al conjunto de datos original, y la puntuación de privacidad cuantifica la probabilidad de que el conjunto de datos esté protegido contra ataques de inferencia de membresía.
Trabajar con datos sintéticos en AWS Clean Rooms
Comenzar con la generación de conjuntos de datos sintéticos que mejoran la privacidad sigue el flujo de trabajo de modelos personalizados de AWS Clean Rooms ML establecido, con nuevos pasos para especificar los requisitos de privacidad y revisar las métricas de calidad. Las organizaciones comienzan creando tablas configuradas con reglas de análisis utilizando sus fuentes de datos preferidas, luego se unen o crean una colaboración con sus socios y asocian sus tablas con esa colaboración.
La nueva capacidad introduce una plantilla de análisis mejorada donde los propietarios de datos definen no sólo la consulta SQL que crea el conjunto de datos sino que también especifican que el conjunto de datos resultante debe ser sintético. Dentro de esta plantilla, las organizaciones clasifican columnas para indicar qué columna predecirá el modelo de ML y qué columnas contienen valores categóricos versus numéricos. Fundamentalmente, la plantilla también incluye umbrales de privacidad que los datos sintéticos generados deben cumplir para estar disponibles para la capacitación. Estos incluyen un valor épsilon que especifica cuánto ruido debe estar presente en los datos sintéticos para proteger contra reidentificacióny una puntuación de protección mínima contra ataques de inferencia de membresía. Establecer estos umbrales de manera adecuada requiere comprender los requisitos de cumplimiento y privacidad específicos de su organización, y recomendamos interactuar con sus equipos legales y de cumplimiento durante este proceso.
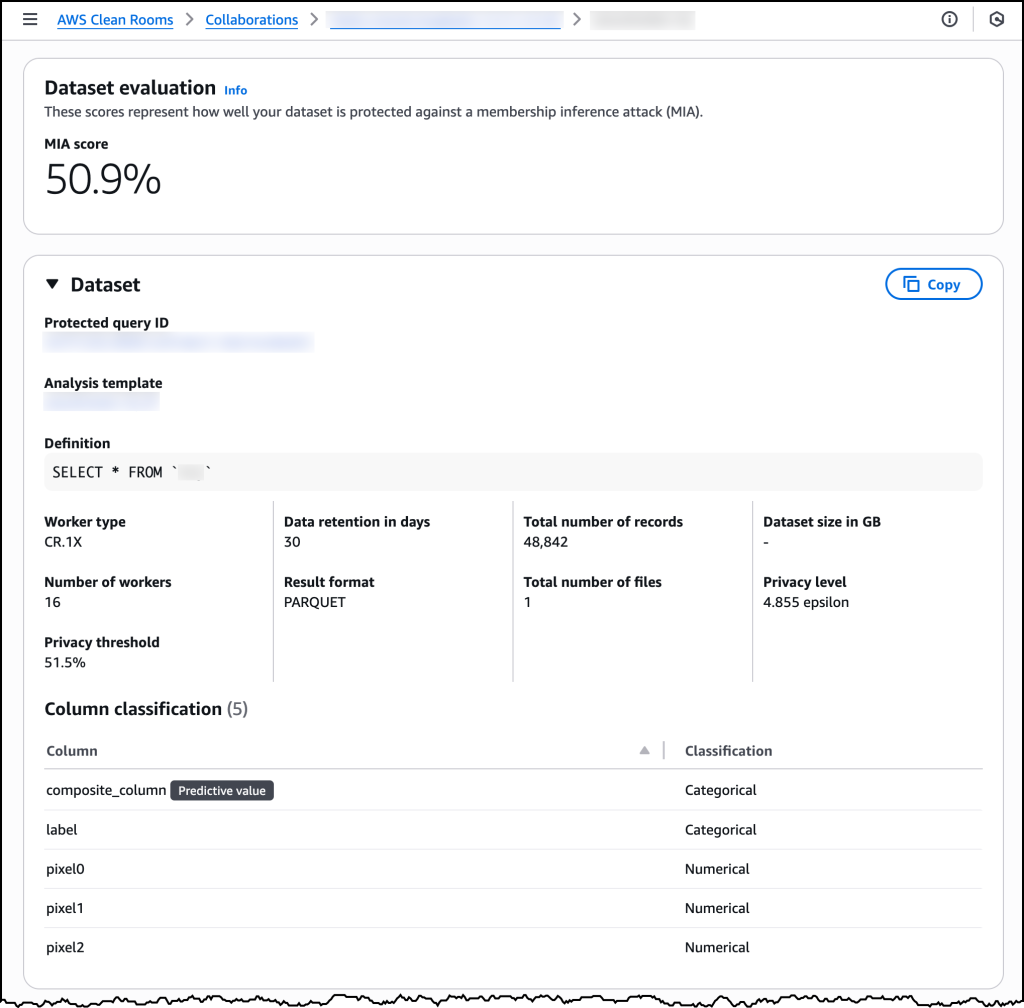
Después de que todos los propietarios de datos revisen y aprueben la plantilla de análisis, un miembro de la colaboración crea un canal de entrada de aprendizaje automático que hace referencia a la plantilla. Luego, AWS Clean Rooms comienza el proceso de generación del conjunto de datos sintéticos, que normalmente se completa en unas pocas horas, según el tamaño y la complejidad del conjunto de datos. Si el conjunto de datos sintéticos generado cumple con los umbrales de privacidad requeridos definidos en la plantilla de análisis, un canal de entrada de aprendizaje automático sintético estará disponible junto con métricas de calidad detalladas. Los científicos de datos pueden revisar el puntaje de protección real logrado contra un ataque de inferencia de membresía simulado.
Una vez satisfechas con las métricas de calidad, las organizaciones pueden proceder a entrenar sus modelos de aprendizaje automático utilizando el conjunto de datos sintéticos dentro de la colaboración de AWS Clean Rooms. Dependiendo del caso de uso, pueden exportar los pesos del modelo entrenado o continuar ejecutando trabajos de inferencia dentro de la propia colaboración.
Probemoslo
Al crear una nueva colaboración con AWS Clean Rooms, ahora puedo establecer quién paga por la generación de conjuntos de datos sintéticos.
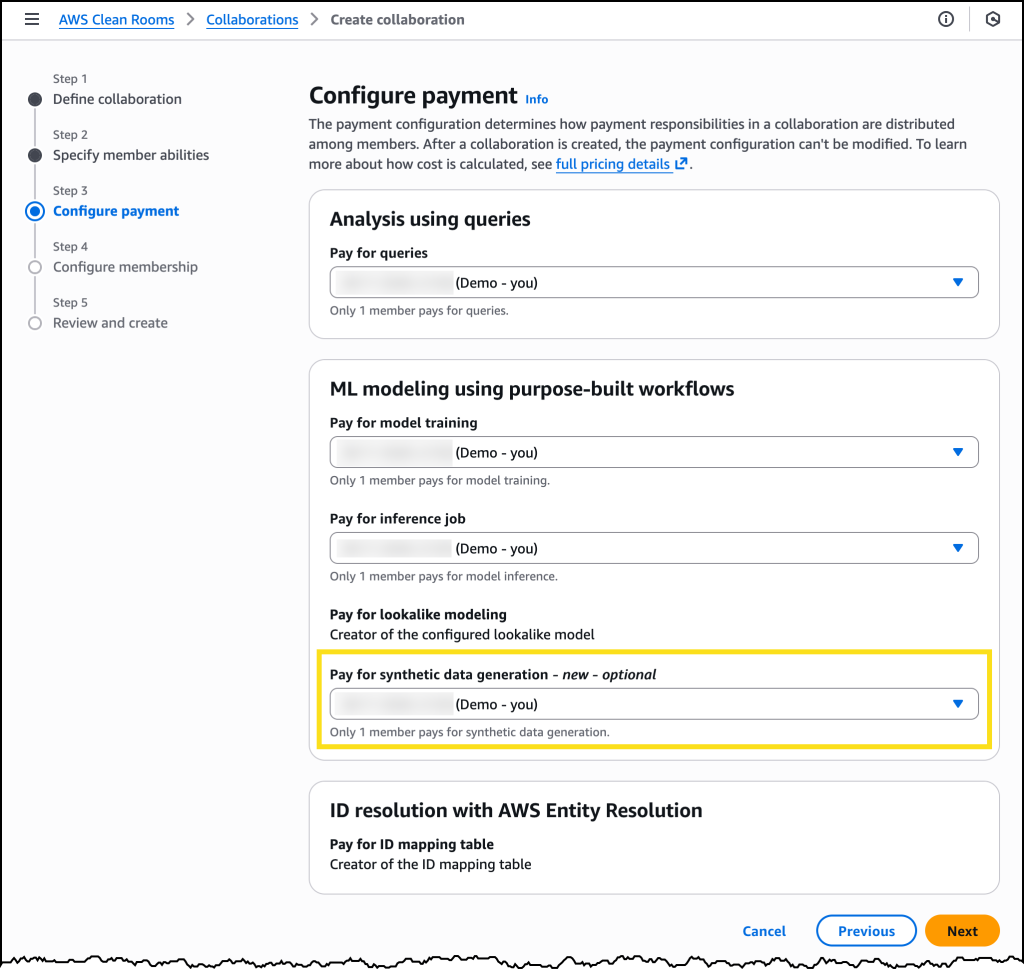
Una vez configurada mi colaboración, puedo elegir Requerir que la salida de la plantilla de análisis sea sintética al crear una nueva plantilla de análisis.
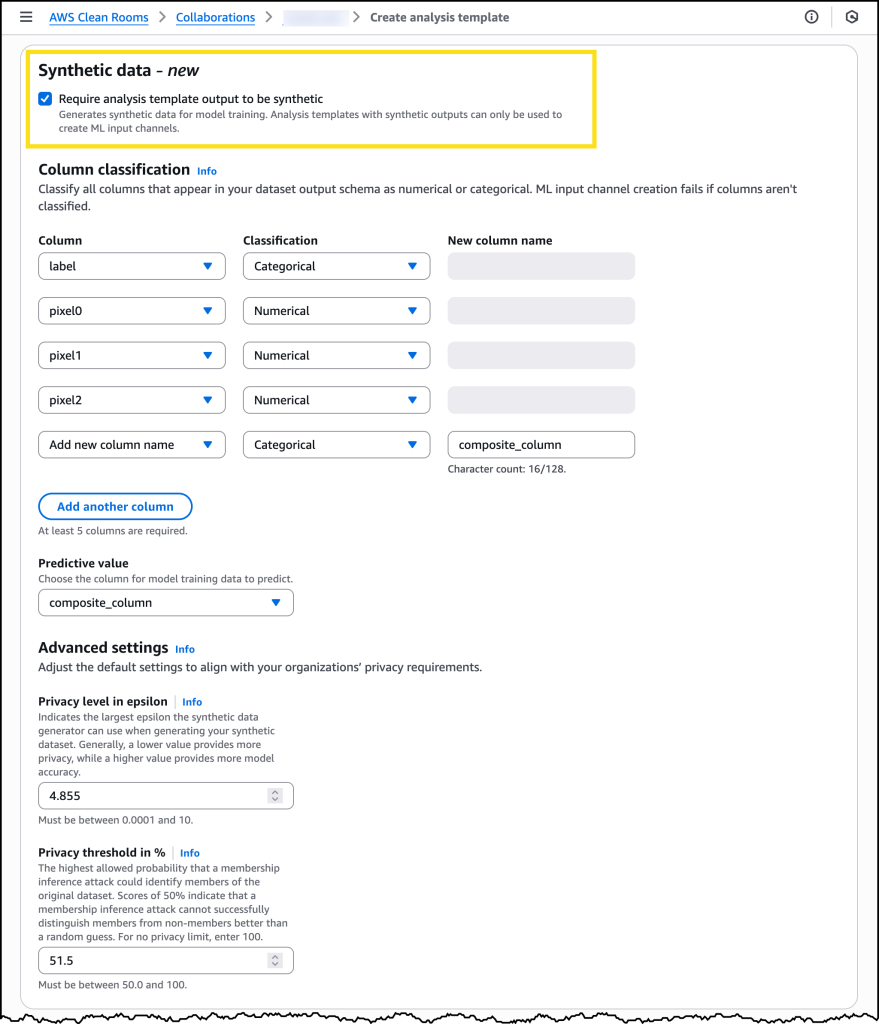
Una vez que mi plantilla de análisis sintético esté lista, puedo usarla cuando ejecuto consultas protegidas y ver todos los detalles relevantes del canal de entrada de ML.
Ahora disponible
Puede comenzar a utilizar la generación de conjuntos de datos sintéticos que mejoran la privacidad a través de AWS Clean Rooms hoy. La función está disponible en todas las regiones comerciales de AWS donde AWS Clean Rooms está disponible. Obtenga más información al respecto en la documentación de AWS Clean Rooms.
La generación de conjuntos de datos sintéticos que mejoran la privacidad se factura por separado según el uso. Solo paga por el cálculo utilizado para generar su conjunto de datos sintéticos, cobrado como Unidades de generación de datos sintéticos (SDGU). La cantidad de SDGU varía según el tamaño y la complejidad de su conjunto de datos original. Esta tarifa se puede configurar como una opción de pago, lo que significa que cualquier miembro de la colaboración puede aceptar pagar los costos. Para obtener más información sobre los precios, consulte la página de precios de AWS Clean Rooms.
La versión inicial admite el entrenamiento de modelos de clasificación y regresión en datos tabulares. Los conjuntos de datos sintéticos funcionan con marcos de aprendizaje automático estándar y se pueden integrar en procesos de desarrollo de modelos existentes sin requerir cambios en sus flujos de trabajo.
Esta capacidad representa un avance significativo en el aprendizaje automático con privacidad mejorada. Las organizaciones pueden aprovechar el valor de los datos confidenciales a nivel de usuario para la capacitación de modelos y, al mismo tiempo, mitigar el riesgo de que se filtre información confidencial sobre usuarios individuales. Ya sea que esté optimizando campañas publicitarias, personalizando cotizaciones de seguros o mejorando los sistemas de detección de fraude, la generación de conjuntos de datos sintéticos que mejoran la privacidad permite entrenar modelos más precisos a través de la colaboración de datos respetando al mismo tiempo la privacidad individual.

