
|
|
Desde que lanzamos la personalización de Amazon Nova en Amazon SageMaker AI en AWS NY Summit 2025, los clientes han estado solicitando las mismas capacidades con Amazon Nova que cuando personalizan modelos de pesos abiertos en Amazon SageMaker Inference. También querían tener más control y flexibilidad en la inferencia de modelos personalizados sobre tipos de instancias, políticas de escalado automático, duración del contexto y configuraciones de simultaneidad que exigen las cargas de trabajo de producción.
Hoy anunciamos la disponibilidad general de soporte para modelos Nova personalizados en Amazon SageMaker Inference, un servicio de inferencia administrado de nivel de producción, configurable y rentable para implementar y escalar modelos Nova personalizados de rango completo. Ahora puede experimentar un viaje de personalización de extremo a extremo para entrenar modelos Nova Micro, Nova Lite y Nova 2 Lite con capacidades de razonamiento utilizando Amazon SageMaker Training Jobs o Amazon HyperPod e implementarlos sin problemas con la infraestructura de inferencia administrada de Amazon SageMaker AI.
Con Amazon SageMaker Inference para modelos Nova personalizados, puede reducir el costo de inferencia mediante la utilización optimizada de GPU utilizando instancias G5 y G6 de Amazon Elastic Compute Cloud (Amazon EC2) en lugar de instancias P5, escalado automático basado en patrones de uso de 5 minutos y parámetros de inferencia configurables. Esta característica permite la implementación de modelos Nova personalizados con capacitación previa continua, ajuste fino supervisado o ajuste fino de refuerzo para sus casos de uso. También puede establecer configuraciones avanzadas sobre la longitud del contexto, la simultaneidad y el tamaño del lote para optimizar la relación entre latencia, costo y precisión para sus cargas de trabajo específicas.
Veamos cómo implementar modelos Nova personalizados en puntos finales en tiempo real de SageMaker AI, configurar parámetros de inferencia e invocar sus modelos para realizar pruebas.
Implementar modelos Nova personalizados en SageMaker Inference
En AWS re:Invent 2025, presentamos una nueva personalización sin servidor en Amazon SageMaker AI para modelos de IA populares, incluidos los modelos Nova. Con unos pocos clics, puede seleccionar sin problemas un modelo y una técnica de personalización, y gestionar la evaluación y la implementación del modelo. Si ya tiene un artefacto de modelo Nova personalizado entrenado, puede implementar los modelos en SageMaker Inference a través de SageMaker Studio o SageMaker AI SDK.
En SageMaker Studio, elija un modelo Nova entrenado en Modelos en sus modelos en el Modelos menú. Puede implementar el modelo eligiendo Desplegar botón, SageMaker IA y Crear nuevo punto final.
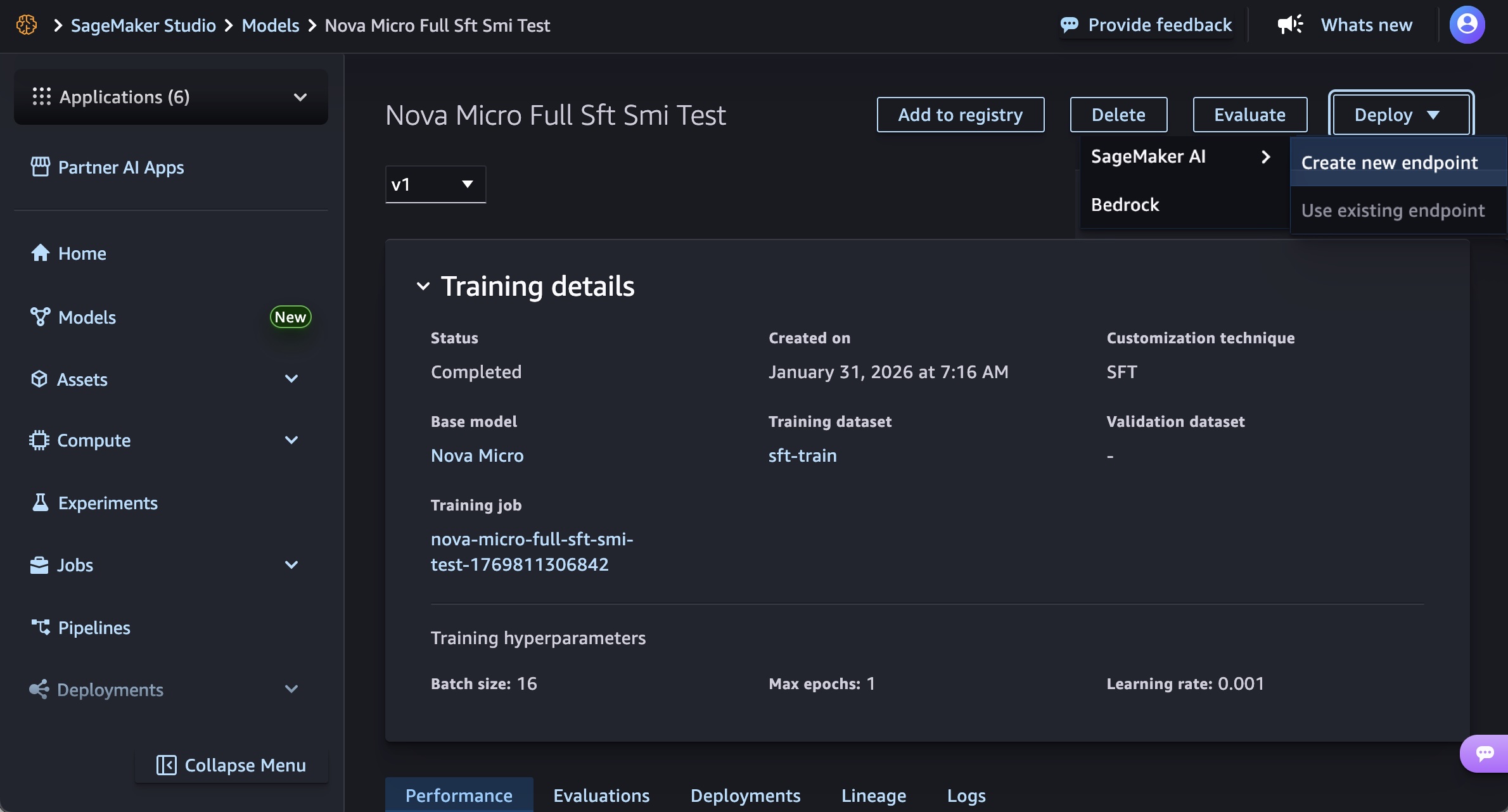
Elija el nombre del punto final, el tipo de instancia y las opciones avanzadas, como el recuento de instancias, el recuento máximo de instancias, el permiso y la red, y Desplegar botón. En el lanzamiento de GA, puedes usar g5.12xlarge, g5.24xlarge, g5.48xlarge, g6.12xlarge, g6.24xlarge, g6.48xlargey p5.48xlarge tipos de instancia para el modelo Nova Micro, g5.24xlarge, g5.48xlarge, g6.24xlarge, g6.48xlargey p5.48xlarge para el modelo Nova Lite, y p5.48xlarge para el modelo Nova 2 Lite.
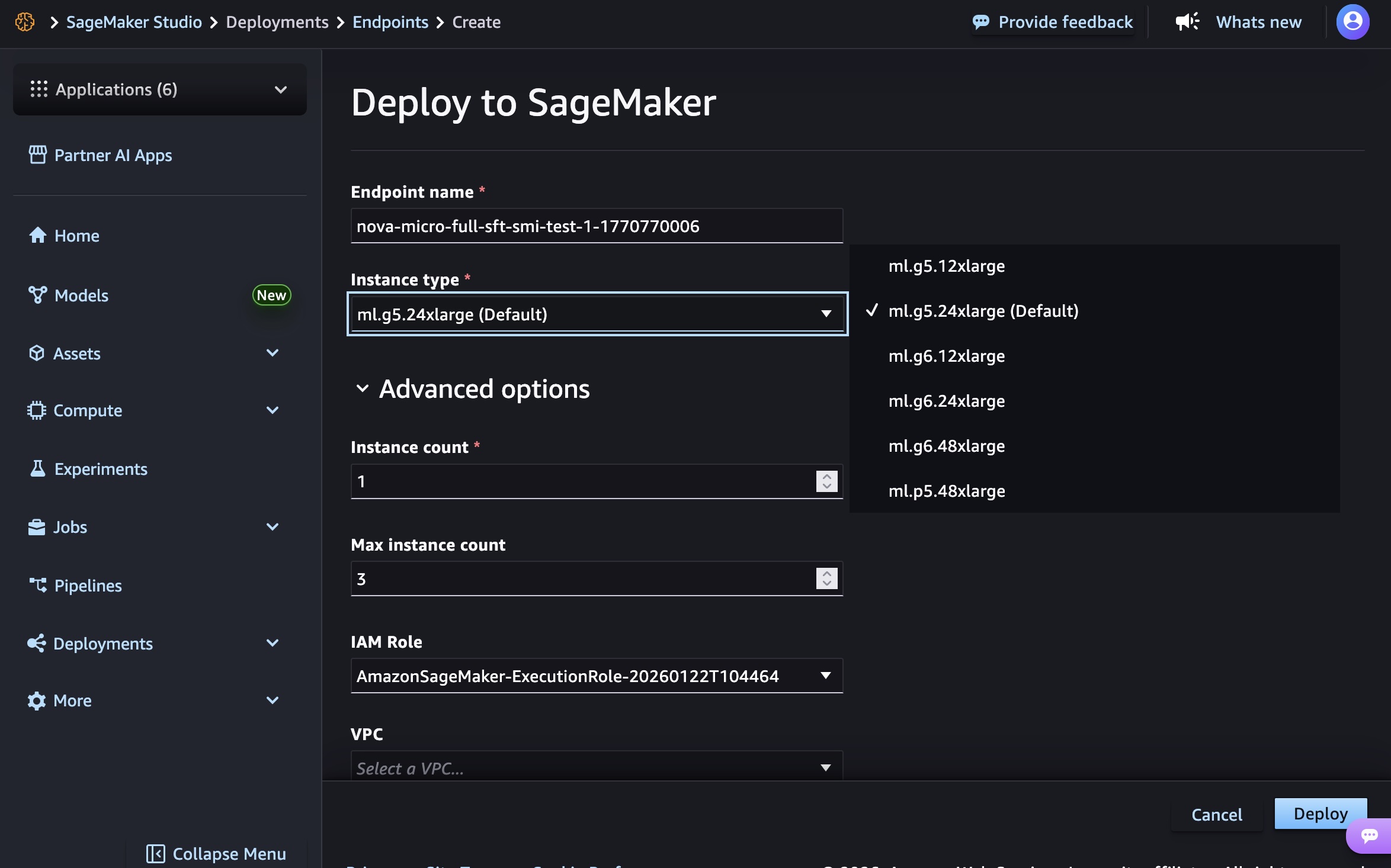
La creación de su punto final requiere tiempo para aprovisionar la infraestructura, descargar los artefactos de su modelo e inicializar el contenedor de inferencia.
Una vez que se completa la implementación del modelo y se muestra el estado del terminal En serviciopuede realizar inferencias en tiempo real utilizando el nuevo punto final. Para probar el modelo, elija el Patio de juegos pestaña e ingrese su mensaje en el Charlar modo.
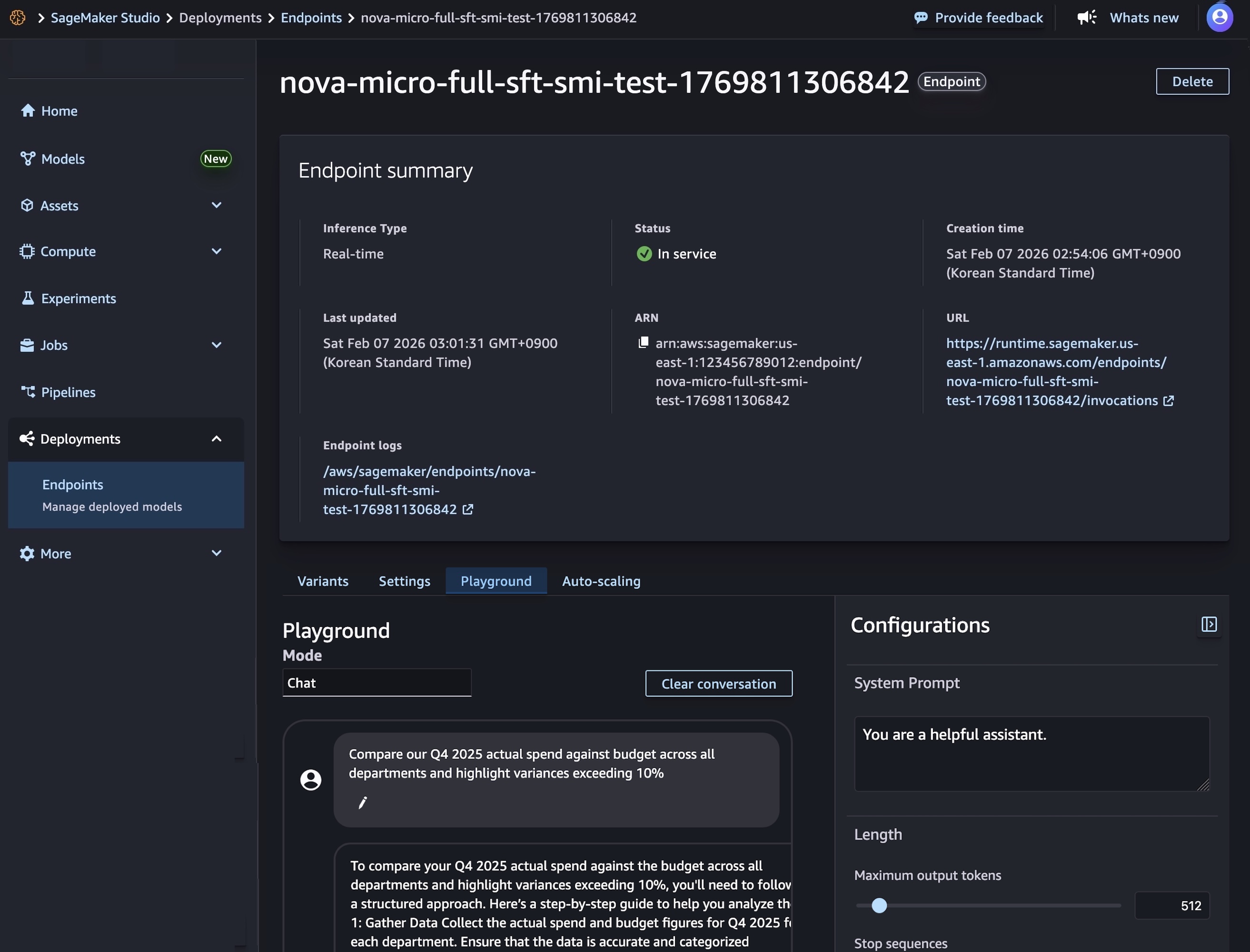
También puede utilizar el SDK de SageMaker AI para crear dos recursos: un objeto de modelo de SageMaker AI que hace referencia a los artefactos de su modelo Nova y una configuración de punto final que define cómo se implementará el modelo.
El siguiente código crea un modelo de IA de SageMaker que hace referencia a los artefactos de su modelo Nova:
# Create a SageMaker AI model
model_response = sagemaker.create_model(
ModelName="Nova-micro-ml-g5-12xlarge",
PrimaryContainer={
'Image': '123456789012.dkr.ecr.us-east-1.amazonaws.com/nova-inference-repo:v1.0.0',
'ModelDataSource': {
'S3DataSource': {
'S3Uri': 's3://your-bucket-name/path/to/model/artifacts/',
'S3DataType': 'S3Prefix',
'CompressionType': 'None'
}
},
# Model Parameters
'Environment': {
'CONTEXT_LENGTH': 8000,
'CONCURRENCY': 16,
'DEFAULT_TEMPERATURE': 0.0,
'DEFAULT_TOP_P': 1.0
}
},
ExecutionRoleArn=SAGEMAKER_EXECUTION_ROLE_ARN,
EnableNetworkIsolation=True
)
print("Model created successfully!")A continuación, cree una configuración de punto final que defina su infraestructura de implementación e implemente su modelo Nova creando un punto final de SageMaker AI en tiempo real. Este punto final alojará su modelo y proporcionará un punto final HTTPS seguro para realizar solicitudes de inferencia.
# Create Endpoint Configuration
production_variant = {
'VariantName': 'primary',
'ModelName': 'Nova-micro-ml-g5-12xlarge',
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.12xlarge',
}
config_response = sagemaker.create_endpoint_config(
EndpointConfigName="Nova-micro-ml-g5-12xlarge-Config",
ProductionVariants= production_variant
)
print("Endpoint configuration created successfully!")
# Deploy your Noval model
endpoint_response = sagemaker.create_endpoint(
EndpointName="Nova-micro-ml-g5-12xlarge-endpoint",
EndpointConfigName="Nova-micro-ml-g5-12xlarge-Config"
)
print("Endpoint creation initiated successfully!")
Una vez creado el punto final, puede enviar solicitudes de inferencia para generar predicciones a partir de su modelo Nova personalizado. Amazon SageMaker AI admite puntos finales sincrónicos en tiempo real con modos de transmisión/no transmisión y puntos finales asíncronos para procesamiento por lotes.
Por ejemplo, el siguiente código crea un formato de finalización de transmisión para la generación de texto:
# Streaming chat request with comprehensive parameters
streaming_request = {
"messages": [
{"role": "user", "content": "Compare our Q4 2025 actual spend against budget across all departments and highlight variances exceeding 10%"}
],
"max_tokens": 512,
"stream": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"logprobs": True,
"top_logprobs": 2,
"reasoning_effort": "low", # Options: "low", "high"
"stream_options": {"include_usage": True}
}
invoke_nova_endpoint(streaming_request)
def invoke_nova_endpoint(request_body):
"""
Invoke Nova endpoint with automatic streaming detection.
Args:
request_body (dict): Request payload containing prompt and parameters
Returns:
dict: Response from the model (for non-streaming requests)
None: For streaming requests (prints output directly)
"""
body = json.dumps(request_body)
is_streaming = request_body.get("stream", False)
try:
print(f"Invoking endpoint ({'streaming' if is_streaming else 'non-streaming'})...")
if is_streaming:
response = runtime_client.invoke_endpoint_with_response_stream(
EndpointName=ENDPOINT_NAME,
ContentType="application/json",
Body=body
)
event_stream = response['Body']
for event in event_stream:
if 'PayloadPart' in event:
chunk = event['PayloadPart']
if 'Bytes' in chunk:
data = chunk['Bytes'].decode()
print("Chunk:", data)
else:
# Non-streaming inference
response = runtime_client.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType="application/json",
Accept="application/json",
Body=body
)
response_body = response['Body'].read().decode('utf-8')
result = json.loads(response_body)
print("✅ Response received successfully")
return result
except ClientError as e:
error_code = e.response['Error']['Code']
error_message = e.response['Error']['Message']
print(f"❌ AWS Error: {error_code} - {error_message}")
except Exception as e:
print(f"❌ Unexpected error: {str(e)}")Para utilizar ejemplos de código completo, visite Personalización de modelos de Amazon Nova en Amazon SageMaker AI. Para obtener más información sobre las mejores prácticas para implementar y administrar modelos, visite Mejores prácticas para SageMaker AI.
Ahora disponible
Amazon SageMaker Inference para modelos Nova personalizados está disponible hoy en las regiones de AWS Este de EE. UU. (Norte de Virginia) y Oeste de EE. UU. (Oregón). Para conocer la disponibilidad regional y una hoja de ruta futura, visite el Capacidades de AWS por región.
La función es compatible con los modelos Nova Micro, Nova Lite y Nova 2 Lite con capacidades de razonamiento, que se ejecutan en instancias EC2 G5, G6 y P5 con soporte de escalado automático. Paga solo por las instancias informáticas que utiliza, con facturación por hora y sin compromisos mínimos. Para obtener más información, visite la página de precios de IA de Amazon SageMaker.
Pruébelo en la consola de Amazon SageMaker AI y envíe sus comentarios a AWS re: Publicación para SageMaker o a través de sus contactos habituales de AWS Support.
— chany

