|
|
Hoy, anunciamos un conjunto de capacidades de personalización para Amazon Nova en Amazon Sagemaker AI. Los clientes ahora pueden personalizar Nova Micro, Nova Lite y Nova Pro en todo el ciclo de vida de capacitación modelo, que incluyen pre-entrenamiento, ajuste y alineación supervisados. Estas técnicas están disponibles como recetas de Amazon Sagemaker listas para usar con implementación perfecta en Amazon Bedrock, que admite la inferencia de rendimiento a pedido y aprovisionada.
Amazon Nova Foundation Models potencia diversos casos de uso generativo de IA generativo en todas las industrias. A medida que los clientes escalan las implementaciones, necesitan modelos que reflejen el conocimiento, los flujos de trabajo y los requisitos de la marca. Optimización rápida y generación de recuperación de la generación (RAG) funcionan bien para integrar modelos de base de uso general en aplicaciones, sin embargo, los flujos de trabajo críticos para el negocio requieren la personalización del modelo para cumplir con los requisitos específicos de precisión, costo y latencia.
Elegir la técnica de personalización correcta
Los modelos de Amazon Nova admiten una gama de técnicas de personalización que incluyen: 1) ajuste fino supervisado, 2) Alineación, 3) Prerreinamiento continuo y 4) Destilación del conocimiento. La elección óptima depende de los objetivos, la complejidad del caso de uso y la disponibilidad de datos y los recursos de calcular. También puede combinar múltiples técnicas para lograr los resultados deseados con la combinación preferida de rendimiento, costo y flexibilidad.
Ajuste de fino supervisado (SFT) Personaliza los parámetros del modelo utilizando un conjunto de datos de entrenamiento de pares de entrada-salida específicos para sus tareas y dominios de destino. Elija entre los siguientes dos enfoques de implementación en función del volumen de datos y las consideraciones de costos:
- Ajuste fino de los parámetros (PEFT) -Actualiza solo un subconjunto de parámetros del modelo a través de capas de adaptador livianas como Lora (adaptación de bajo rango). Ofrece una capacitación más rápida y costos de cómputo más bajos en comparación con el ajuste completo. Los modelos Nova adaptados a PEFT se importan a la roca madre de Amazon y se invocan utilizando inferencia a pedido.
- Ajuste completo (FFT) – Actualiza todos los parámetros del modelo y es ideal para escenarios cuando tiene extensos conjuntos de datos de capacitación (decenas de miles de registros). Los modelos Nova personalizados a través de FFT también se pueden importar a Amazon Bedrock e invocarse para inferencia con el rendimiento aprovisionado.
Alineación Made la salida del modelo hacia las preferencias deseadas para las necesidades y el comportamiento específicos del producto, como los requisitos de la marca de la empresa y la experiencia del cliente. Estas preferencias pueden codificarse de múltiples maneras, incluidos ejemplos y políticas empíricas. Los modelos NOVA admiten dos técnicas de alineación de preferencias:
- Optimización de preferencias directas (DPO) – Ofrece una forma directa de sintonizar las salidas del modelo utilizando pares de respuesta preferidos/no preferidos. DPO aprende de las preferencias comparativas para optimizar los resultados para requisitos subjetivos como el tono y el estilo. DPO ofrece una versión eficiente de parámetros y una versión de actualización de modelo completo. La versión eficiente de parámetros admite inferencia a pedido.
- Optimización de políticas proximales (PPO) – utiliza el aprendizaje de refuerzo para mejorar el comportamiento del modelo mediante la optimización de las recompensas deseadas, como la ayuda, la seguridad o el compromiso. Un modelo de recompensa guía la optimización al calificar las salidas, ayudando al modelo a aprender comportamientos efectivos mientras mantiene capacidades previamente aprendidas.
Precinificación continua (CPT) Amplía el conocimiento del modelo fundamental a través del aprendizaje auto-supervisado en grandes cantidades de datos patentados no etiquetados, incluidos documentos internos, transcripciones y contenido específico del negocio. CPT seguido de SFT y alineación a través de DPO o PPO proporciona una forma integral de personalizar los modelos Nova para sus aplicaciones.
Destilación de conocimiento Transfiere el conocimiento de un modelo de «maestro» más grande a un modelo de «alumno» más pequeño, más rápido y más rentable. La destilación es útil en escenarios en los que los clientes no tienen muestras de entrada-salida de referencia adecuadas y pueden aprovechar un modelo más potente para aumentar los datos de capacitación. Este proceso crea un modelo personalizado de precisión a nivel de maestro para casos de uso específicos y rentabilidad y velocidad a nivel de alumno.
Aquí hay una tabla que resume las técnicas de personalización disponibles en diferentes modalidades y opciones de implementación. Cada técnica ofrece capacidades específicas de capacitación e inferencia dependiendo de sus requisitos de implementación.
| Receta | Modalidad | Capacitación | Inferencia | ||
|---|---|---|---|---|---|
| Roca madre de Amazon | Amazon Sagemaker | Amazon Bedrock a pedido | Amazon Bedrock Provisado por rumbo | ||
| Tonte fino supervisado | Texto, imagen, video | ||||
| Ajuste fino de los parámetros (PEFT) | ✅ | ✅ | ✅ | ✅ | |
| Ajuste completo | ✅ | ✅ | |||
| Optimización de preferencias directas (DPO) | Texto, imagen | ||||
| DPO de bajo consumo de parámetros | ✅ | ✅ | ✅ | ||
| Modelo completo DPO | ✅ | ✅ | |||
| Optimización de políticas proximales (PPO) | Solo texto | ✅ | ✅ | ||
| Pre-entrenamiento continuo | Solo texto | ✅ | ✅ | ||
| Destilación | Solo texto | ✅ | ✅ | ✅ | ✅ |
Los clientes de acceso temprano, incluyendo Cosine AI, Massachusetts Institute of Technology (MIT) informática e inteligencia artificial Laboratorio de inteligencia (CSAIL), Volkswagen, Amazon Customer Service y Amazon Catalog Systems, ya utilizan con éxito las capacidades de personalización de Amazon Nova.
Personalización de modelos Nova en acción
A continuación se lo lleva a cabo a través de un ejemplo de personalización del modelo nova micro utilizando la optimización de preferencias directas en un conjunto de datos de preferencias existente. Para hacer esto, puede usar Amazon Sagemaker Studio.
Inicie su estudio de Sagemaker en la consola AI de Amazon Sagemaker y elija Salpicarun centro de aprendizaje automático (ML) con modelos de base, algoritmos incorporados y soluciones ML prebuiladas que puede implementar con unos pocos clics.
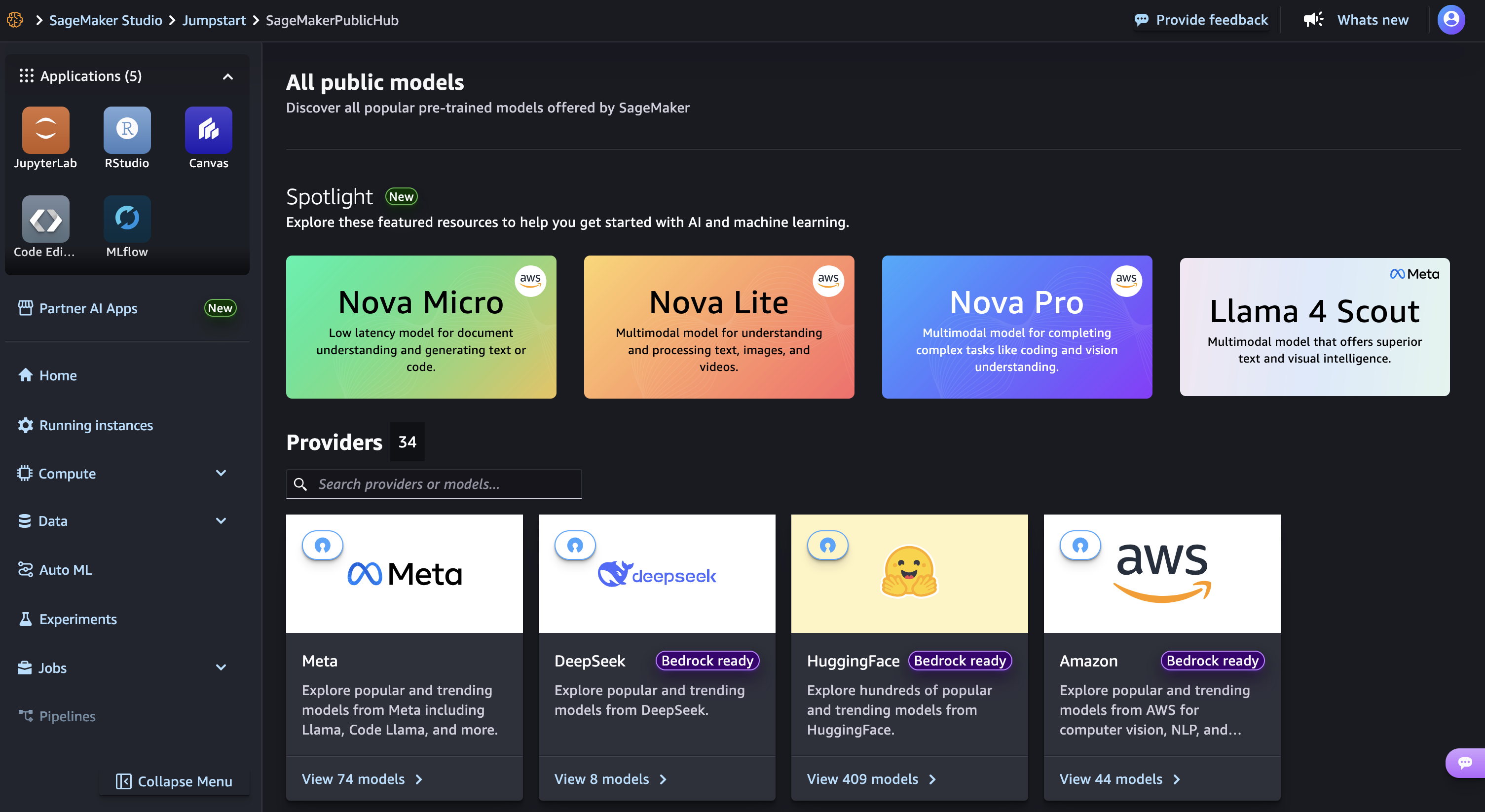
Entonces, elige Nova Microun modelo solo de texto que ofrece las respuestas de latencia más bajas al menor costo por inferencia entre la familia del modelo Nova, y luego elegir Tren.
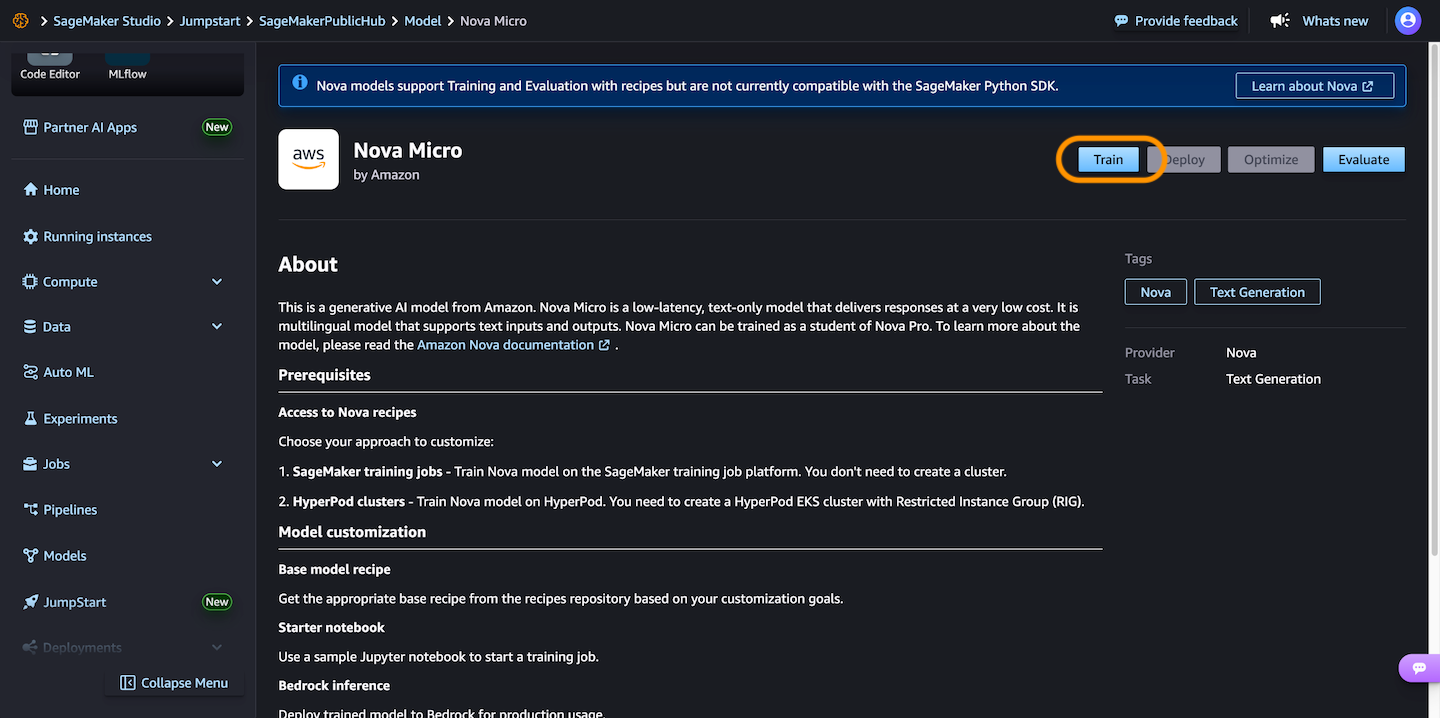
A continuación, puedes elegir un sintonia FINA Receta para entrenar el modelo con datos etiquetados para mejorar el rendimiento en tareas específicas y alinearse con los comportamientos deseados. Elegir el Optimización de preferencias directas Ofrece una forma directa de ajustar las salidas de modelos con sus preferencias.
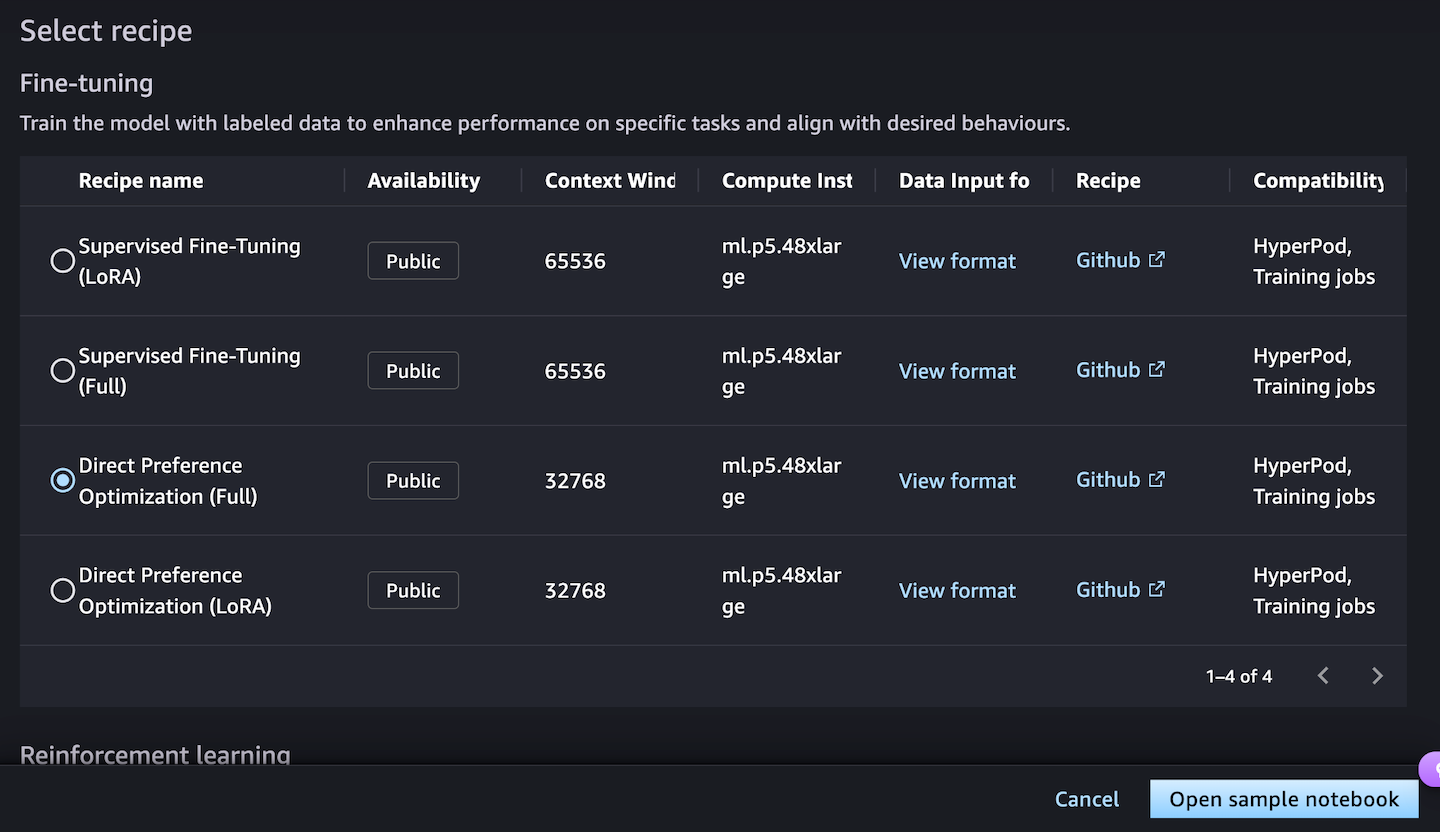
Cuando elijas Abrir cuaderno de muestratiene dos opciones de entorno para ejecutar la receta: ya sea en los trabajos de capacitación de Sagemaker o Sagemaker Hyperpod:
Elegir Ejecutar receta en Trabajos de capacitación de Sagemaker Cuando no necesita crear un clúster y entrenar el modelo con el cuaderno de muestra seleccionando su espacio jupyterlab.
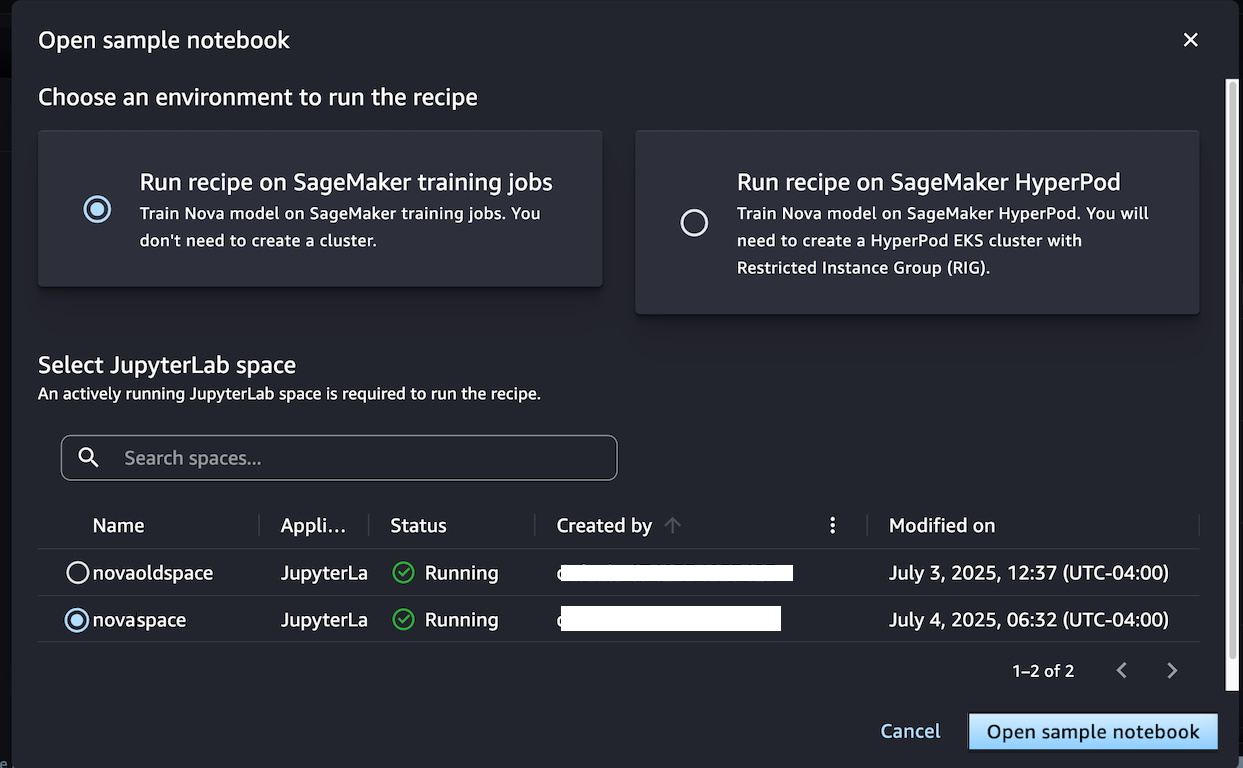
Alternativamente, si desea tener un entorno de clúster persistente optimizado para los procesos de capacitación iterativa, elija Ejecutar receta en Sagemaker Hyperpod. Puede elegir un clúster EKS Hyperpod con al menos un grupo de instancias restringido (RIG) para proporcionar un entorno aislado especializado, que se requiere para dicha capacitación en modelo NOVA. Luego, elija su JupyterLabspace y Abrir cuaderno de muestra.
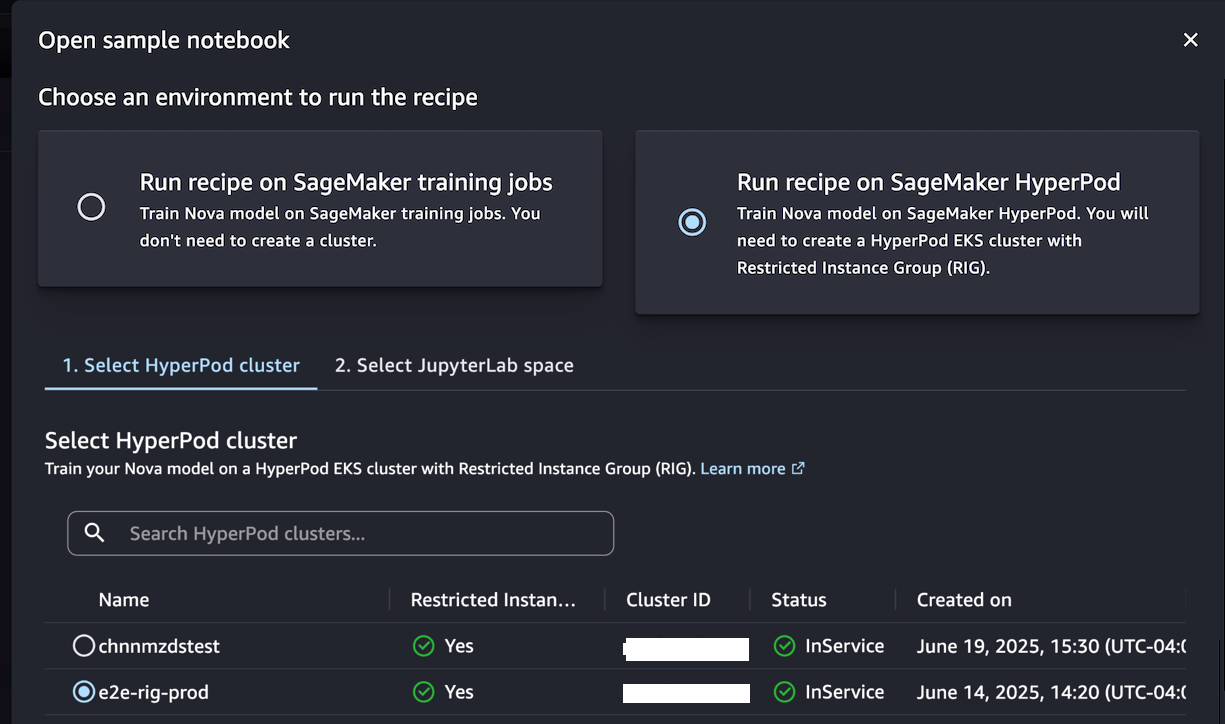
Este cuaderno proporciona un tutorial de extremo a extremo para crear un trabajo de Sagemaker HyperPod utilizando un modelo Sagemaker Nova con una receta e implementarla para inferencia. Con la ayuda de una receta de Sagemaker HyperPod, puede optimizar las configuraciones complejas e integrar sin problemas conjuntos de datos para trabajos de capacitación optimizados.
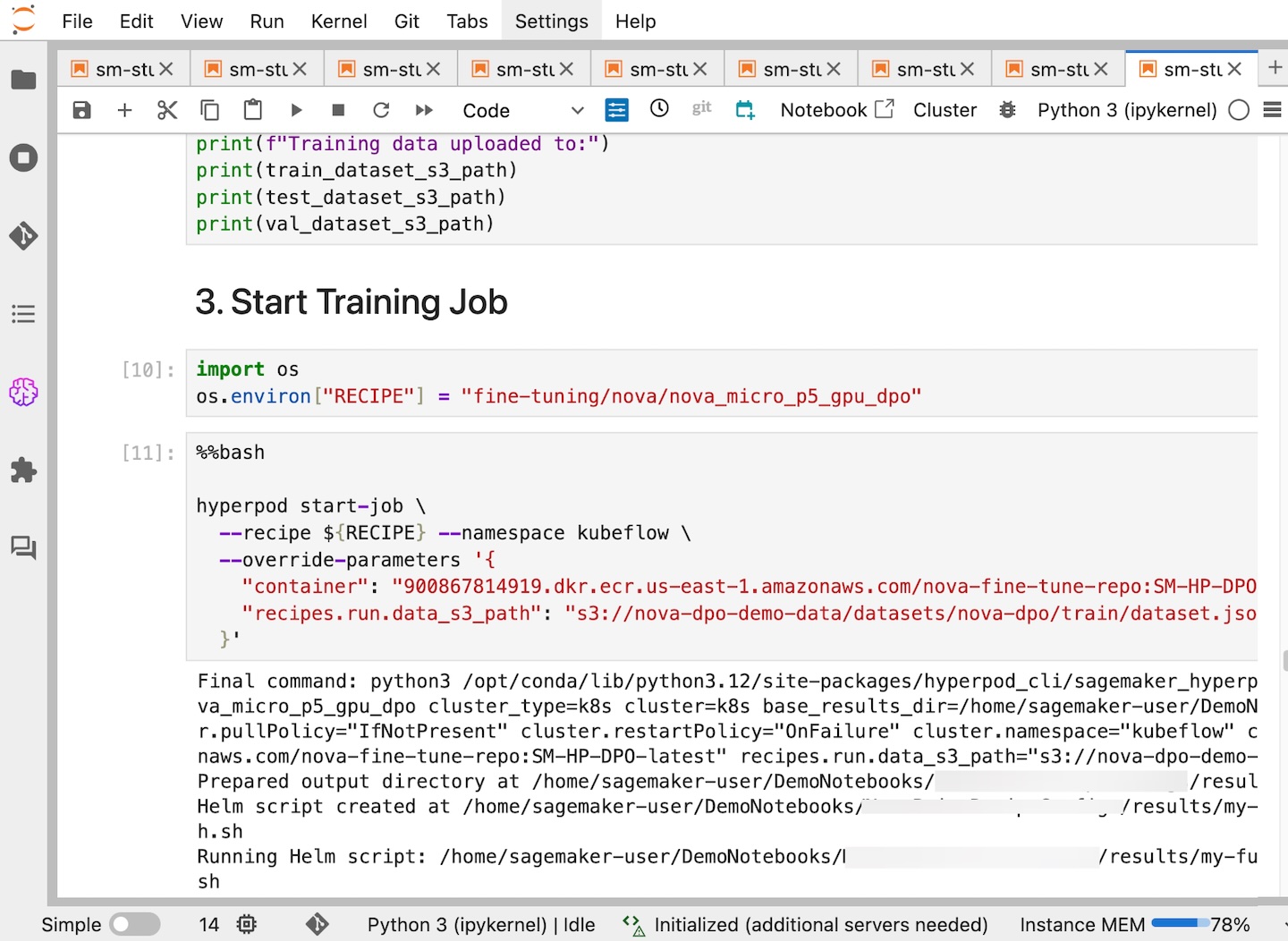
En Sagemaker Studio, puede ver que su trabajo de Sagemaker HyperPod se ha creado con éxito y puede monitorearlo para un progreso adicional.
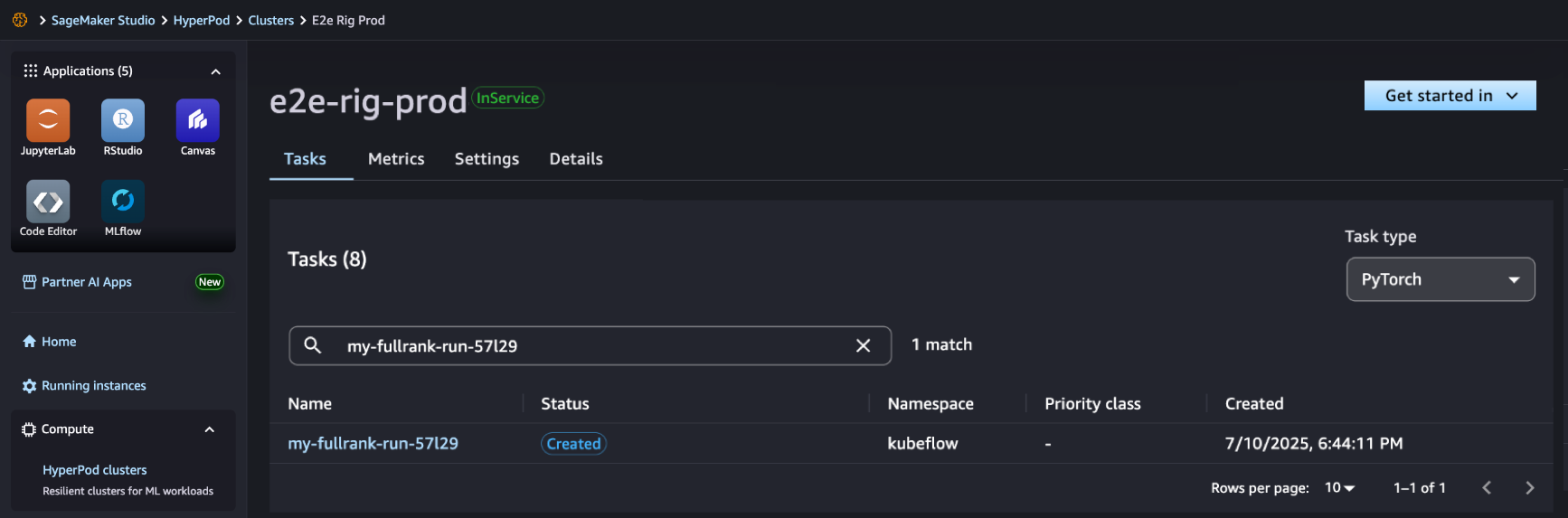
Una vez que se completa su trabajo, puede usar una receta de referencia para evaluar si el modelo personalizado funciona mejor en las tareas de agente.
Para una documentación integral e implementaciones de ejemplo adicionales, visite el Sagemaker Repositorio de recetas HyperPod en GitHub. Continuamos expandiendo las recetas en función de los comentarios de los clientes y las tendencias de ML emergentes, asegurando que tenga las herramientas necesarias para una personalización exitosa del modelo de IA.
Disponibilidad y comenzar
Las recetas de Amazon Nova en Amazon Sagemaker AI están disponibles en US East (N. Virginia). Obtenga más información sobre esta función visitando la página web de personalización de Amazon Nova y la Guía del usuario de Amazon Nova y comience en la consola AI de Amazon Sagemaker.
Actualizado el 16 de julio de 2025: revisó los datos de la tabla y la captura de pantalla de la consola.