
|
|
Hoy anunciamos una nueva capacidad de metadatos para Amazon Simple Storage Service (Amazon S3) llamada anotaciones, que le permite adjuntar un contexto empresarial rico y a gran escala directamente a sus objetos. Puede almacenar hasta 1000 anotaciones con nombre por objeto, cada una de hasta 1 MB de tamaño, con un total de hasta 1 GB por objeto, en formatos flexibles como JSON, XML, YAML o texto sin formato. Puede modificar o eliminar una anotación en cualquier momento, sin tener que volver a escribir sus objetos, lo que facilita mantener actualizado el contexto de su objeto.
Las organizaciones están creando agentes de IA y flujos de trabajo autónomos que necesitan encontrar, comprender y actuar sobre los datos sin intervención humana. Para respaldar estos flujos de trabajo agentes, necesita metadatos que puedan evolucionar junto con los datos, escalar a petabytes de objetos y seguir siendo consultables sin una recuperación costosa.
Con las anotaciones de S3, puede almacenar contexto como transcripciones generadas por IA, clasificaciones de contenido o especificaciones técnicas directamente junto a sus objetos. Su contexto se mueve automáticamente con el objeto durante la copia, la replicación y las transferencias entre regiones, y S3 lo elimina cuando elimina el objeto. Cuando habilita los metadatos de S3, las anotaciones fluyen automáticamente hacia tablas de anotaciones totalmente administradas que puede consultar con Amazon Athena y otros motores de análisis.
Casos de uso comunes
Las anotaciones resuelven desafíos complejos de metadatos en todas las industrias:
- Medios y entretenimiento: Realice un seguimiento de las transcripciones, los resultados de la moderación de contenido, los archivos de subtítulos y los metadatos de licencias como anotaciones separadas en los recursos de video, lo que elimina la necesidad de sincronizar los metadatos entre múltiples sistemas de administración de activos multimedia.
- Servicios financieros: Adjunte resúmenes de inversiones y análisis de sentimientos generados por IA a los documentos de investigación, lo que permite a los agentes de investigación autónomos descubrir conjuntos de datos relevantes a través de consultas en lenguaje natural sin mantener bases de datos de metadatos separadas.
- Ciencias de la vida: Anote los datos de los ensayos clínicos con el estado regulatorio, los detalles de la cohorte de pacientes y las cadenas de aprobación, lo que agiliza las auditorías de cumplimiento y, al mismo tiempo, mantiene el contexto completo accesible para los datos archivados en las clases de almacenamiento de Amazon S3 Glacier sin cargos por recuperación.
Cómo las anotaciones abordan los desafíos de los metadatos
Amazon S3 ya admite varias formas de describir sus objetos. Los metadatos definidos por el sistema capturan propiedades como el tamaño y la clase de almacenamiento. Las etiquetas de objetos respaldan tareas operativas como el control de acceso y la gestión del ciclo de vida. Los metadatos definidos por el usuario le permiten agregar pequeñas cantidades de información personalizada en el momento de la carga.
Si bien estas capacidades funcionan bien para los fines previstos, tienen limitaciones cuando es necesario adjuntar un contexto mucho más rico sin crear y mantener sistemas de metadatos separados. Las anotaciones abordan estas necesidades al proporcionar capacidades de metadatos en una escala y flexibilidad fundamentalmente diferentes, ofreciendo contexto mutable y consultable por objeto en comparación con 10 etiquetas inmutables o 2 KB de encabezados.
| Capacidad | tamaño máximo | ¿Mudable? | Lo mejor para |
| Metadatos definidos por el sistema | Fijado | No | Propiedades del objeto (tamaño, clase de almacenamiento, hora de creación) |
| Metadatos definidos por el usuario | 2 KB | No (establecido al cargar) | Pequeños pares clave-valor personalizados |
| Etiquetas de objetos | 10 etiquetas, 128/256 caracteres por clave/valor | Sí | Control de acceso, reglas de ciclo de vida, asignación de costos. |
| Anotaciones | 1 GB (1000 × 1 MB) | Sí | Contexto empresarial enriquecido (JSON, XML, YAML, texto sin formato) |
Hoy en día, los metadatos que describen objetos S3 a menudo se encuentran en bases de datos separadas o archivos secundarios, lo que requiere flujos de trabajo de sincronización complejos que pueden exceder los costos de almacenamiento de datos. Cuando habilita las tablas de anotaciones de metadatos de S3, este contexto se puede consultar a escala a través de Amazon Athena. Los agentes de IA pueden descubrir sus datos a través del lenguaje natural con el servidor MCP de S3 Tables, que proporciona una interfaz estandarizada para que los modelos de IA consulten sus anotaciones. Puede consultar anotaciones de objetos en cualquier clase de almacenamiento, sin restaurar los objetos ni pagar cargos de recuperación.
Comenzando con las anotaciones
Para comenzar a utilizar anotaciones, asegúrese de que su política de AWS Identity and Access Management (IAM) o su política de depósito otorgue permisos para las s3:PutObjectAnnotation y s3:GetObjectAnnotation comportamiento. Luego puede agregar anotaciones a cualquier objeto S3 nuevo o existente usando el PutObjectAnnotation API.
Por ejemplo, una empresa de medios puede adjuntar especificaciones técnicas y resúmenes producidos por IA a un recurso de vídeo mediante la interfaz de línea de comandos de AWS (AWS CLI):
# Create a JSON file with technical metadata
cat > mediainfo.json << 'EOF'
{"codec":"H.265","resolution":"3840x2160","audio_tracks":8,"frame_rate":29.97}
EOF
# Attach it as an annotation
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
--annotation-payload ./mediainfo.json
# Attach a plain-text AI-generated summary as a separate annotation
echo "A 90-minute nature documentary covering wildlife migration patterns across three continents, featuring aerial footage and underwater sequences. Languages: English, Spanish, Portuguese." > ai_summary.txt
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name ai_summary \
--annotation-payload ./ai_summary.txt
Estos comandos adjuntan dos anotaciones independientes al mismo objeto de vídeo. El mediainfo La anotación almacena especificaciones técnicas estructuradas como JSON, mientras que la ai_summary La anotación almacena una descripción de texto. Cada anotación se identifica con un nombre único y puedes leer y modificar cada una de forma independiente. Con nombres únicos para cada anotación, puede utilizar diferentes anotaciones para admitir múltiples flujos de trabajo de enriquecimiento simultáneos, por ejemplo, un equipo agrega metadatos técnicos mientras otro equipo agrega clasificaciones de contenido, sin interferir entre sí.
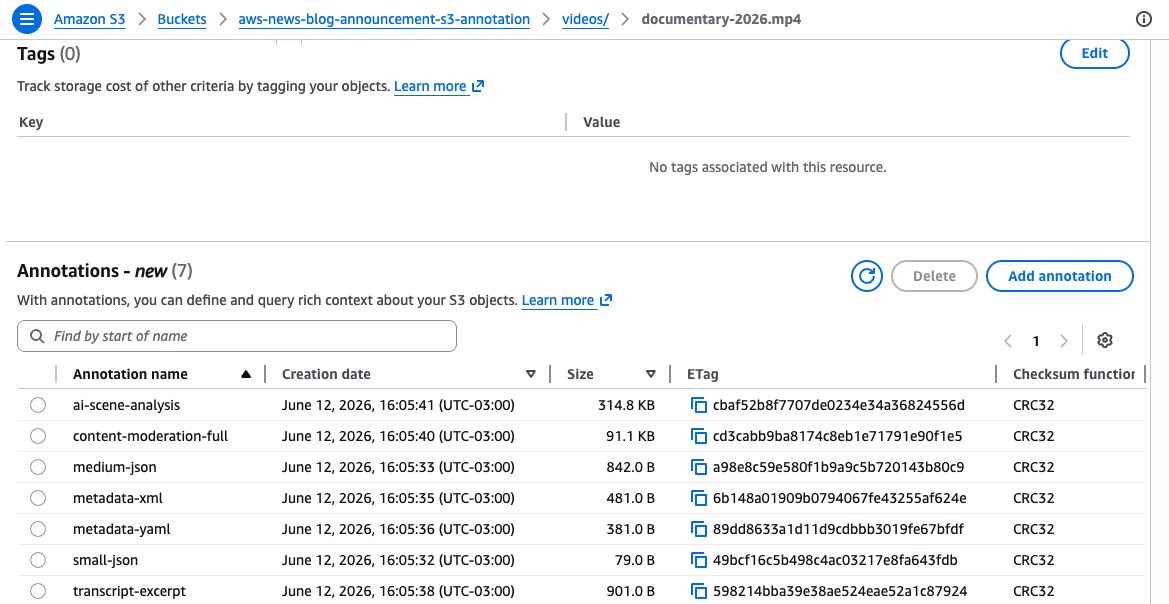
Recuperar una anotación específica usando el GetObjectAnnotation API:
aws s3api get-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
./mediainfo-output.json
Para ver todas las anotaciones adjuntas a un objeto, utilice el ListObjectAnnotations API:
aws s3api list-object-annotations \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4
Cuando ya no necesite una anotación específica, elimínela usando el DeleteObjectAnnotation API:
aws s3api delete-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo
Puede actualizar una anotación existente en cualquier momento llamando PutObjectAnnotation nuevamente con el mismo nombre de anotación. Para objetos grandes cargados mediante carga multiparte, adjunte anotaciones después de completar la carga multiparte usando el PutObjectAnnotation API.
Consulta de anotaciones a escala con tablas de metadatos de S3
Adjuntar anotaciones a objetos individuales es útil, pero el verdadero poder surge cuando consulta todas sus anotaciones a escala. Cuando habilita las tablas de anotaciones de metadatos de S3 en su depósito, S3 indexa automáticamente sus anotaciones en un archivo totalmente administrado. Iceberg apache tabla, llamada tabla de anotaciones. Puede consultar tablas de anotaciones con Amazon Athena o cualquier motor compatible con Iceberg.
Para habilitar las tablas de anotaciones, use la consola S3 o el CreateBucketMetadataConfiguration API. El siguiente ejemplo crea una nueva configuración de metadatos con tablas de anotaciones habilitadas mientras mantiene tablas de diario para el seguimiento de cambios y deshabilita la tabla de inventario en vivo:
{
"JournalTableConfiguration": {
"RecordExpiration": { "Expiration": "DISABLED" }
},
"InventoryTableConfiguration": { "ConfigurationState": "DISABLED" },
"AnnotationTableConfiguration": {
"ConfigurationState": "ENABLED",
"Role": "arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"
}
}
Esta configuración le dice a S3 que capture automáticamente todas sus anotaciones en una tabla consultable. Una vez aplicada, cualquier anotación que adjunte a los objetos de este depósito aparecerá en la tabla en aproximadamente una hora.
Si el depósito ya tiene una configuración de metadatos, utilice el UpdateBucketMetadataAnnotationTableConfiguration API:
aws s3api update-bucket-metadata-annotation-table-configuration \
--bucket my-media-bucket \
--annotation-table-configuration '{"ConfigurationState":"ENABLED","Role":"arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"}'
Una vez habilitadas, sus anotaciones fluyen automáticamente a la tabla de anotaciones. Las tablas de diario se actualizan casi en tiempo real, mientras que las tablas de anotaciones se actualizan en una hora. A diferencia de las tablas de metadatos tradicionales que requieren esquemas predefinidos, las tablas de anotaciones se adaptan automáticamente a cualquier estructura JSON, XML o YAML que escriba. Cada anotación se convierte en una fila de la tabla con su contenido almacenado en un text_value columna, lo que le permite consultar todas las anotaciones sin migraciones de esquema.
Si habilita las tablas de anotaciones en un depósito que ya tiene objetos anotados, S3 rellena automáticamente las anotaciones existentes en la tabla. El proceso de reposición se ejecuta en segundo plano y puede tardar desde varias horas hasta días dependiendo de la cantidad de objetos.
Por ejemplo, para buscar todos los recursos de vídeo con más de 8 pistas de audio en todo su segmento utilizando Amazon Athena:
SELECT DISTINCT bucket, object_key
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation"
WHERE name="mediainfo"
AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8
Esta consulta escanea la tabla de anotaciones en busca de todas las anotaciones denominadas mediainfoextrae el audio_tracks campo del contenido JSON y devuelve objetos donde el recuento excede 8.
O para buscar todos los objetos que recibieron nuevas anotaciones en las últimas 24 horas a través de la tabla de diario:
SELECT bucket, key, version_id, record_timestamp, annotation.name
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."journal"
WHERE record_timestamp >= (current_date - interval '1' day)
AND annotation.name IS NOT NULL
AND record_type IN ('CREATE_ANNOTATION', 'DELETE_ANNOTATION')
Esta consulta utiliza la tabla de diario para realizar un seguimiento de los cambios de anotaciones casi en tiempo real, lo que es ideal para crear flujos de trabajo basados en eventos que respondan a anotaciones nuevas o eliminadas.
También puede utilizar lenguaje natural para buscar objetos por sus anotaciones utilizando agentes en Amazon SageMaker Unified Studio o cualquier IDE con el servidor MCP de S3 Tables. Por ejemplo, preguntar «buscar todas las películas con clasificación PG y subtítulos en español de 2023» arroja resultados en segundos en lugar de las horas que llevaría consultar varios sistemas desconectados.
Comience hoy
Puede comenzar a utilizar las anotaciones de Amazon S3 hoy en todas las regiones de AWS, incluidas las regiones de AWS China. Las tablas de anotaciones están disponibles en todas las regiones de AWS donde los metadatos de S3 están disponibles.
Ya sea que esté creando agentes de IA que necesitan descubrir datos de forma autónoma, administrando petabytes de activos multimedia con metadatos complejos o rastreando el contexto de cumplimiento para conjuntos de datos archivados, las anotaciones le brindan la escala y la flexibilidad para adjuntar metadatos enriquecidos directamente a sus objetos sin administrar sistemas separados.
El almacenamiento de anotaciones siempre se factura según las tarifas estándar de S3, incluso si el objeto principal está en S3 Glacier u otra clase de almacenamiento. Para obtener detalles completos sobre los precios, visite la página de precios de Amazon S3.
Para obtener más información y comenzar, visite la página de descripción general de metadatos de Amazon S3 y la documentación de Amazon S3. Enviar comentarios a AWS re: Publicación para S3 o a través de sus contactos habituales de AWS Support.
Daniel Abib

