
Un ejemplo de un modelo de lenguaje grande. Los investigadores de UTSA completaron recientemente uno de los estudios más completos hasta la fecha sobre los riesgos de usar modelos de IA para desarrollar software. En un nuevo artículo, demuestran cómo un tipo específico de error podría representar una seria amenaza para los programadores que usan IA para ayudar a escribir código. Crédito: la Universidad de Texas en San Antonio
Los investigadores de UTSA completaron recientemente uno de los estudios más completos hasta la fecha sobre los riesgos de usar modelos de IA para desarrollar software. En un nuevo artículo, demuestran cómo un tipo específico de error podría representar una seria amenaza para los programadores que usan IA para ayudar a escribir código.
Joe Spracklen, un estudiante de doctorado de UTSA en informática, dirigió el estudio sobre cómo los modelos de idiomas grandes (LLM) generan con frecuencia un código inseguro.
El papel de su equipo, publicado en el arxiv Preprint Server, también ha sido aceptado para su publicación en el Simposio de seguridad de USENIX 2025una conferencia de ciberseguridad y privacidad.
La colaboración multiinstitucional contó con tres investigadores adicionales de UTSA: el estudiante doctoral AHM Nazmus Sakib, el investigador postdoctoral Raveen Wijewickrama y el profesor asociado Dr. Murtuza Jadliwala, director de Spritelab (seguridad, privacidad, confianza y ética en el laboratorio de investigación informática).
Los colaboradores adicionales fueron Anindya Maita de la Universidad de Oklahoma (ex investigador postdoctoral de UTSA) y Bimal Viswanath de Virginia Tech.
Las alucinaciones en LLM se producen cuando el modelo produce contenido que es fácticamente incorrecto, sin sentido o completamente no relacionado con la tarea de entrada. La mayoría de las investigaciones actuales hasta ahora se han centrado principalmente en las alucinaciones en tareas clásicas de generación de lenguajes naturales y predicción, como la traducción automática, el resumen y la IA conversacional.
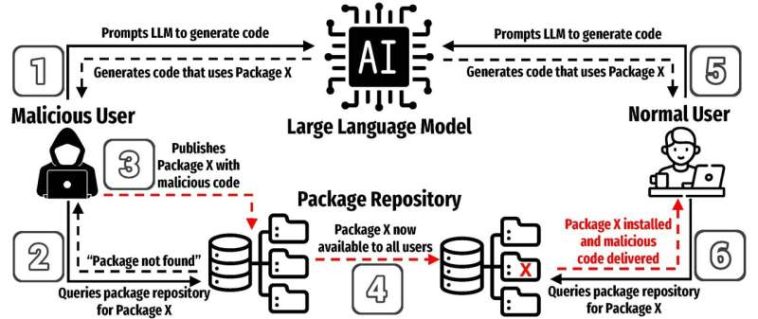
El equipo de investigación se centró en el fenómeno de la alucinación del paquete, que ocurre cuando un LLM genera o recomienda el uso de una biblioteca de software de terceros que realmente no existe.
Lo que hace que las alucinaciones del paquete sean un área de investigación fascinante es cómo algo tan simple, un comando único y cotidiano, puede conducir a serios riesgos de seguridad.
«No requiere un conjunto enrevesado de circunstancias o algo oscuro para suceder», dijo Spracklen. «Es solo escribir un comando que la mayoría de las personas que trabajan en esos lenguajes de programación escriben todos los días. Eso es todo lo que se necesita. Es muy directo y muy simple».
«También es ubicuo», agregó. «Puede hacer muy poco con su lenguaje de codificación de Python básico. Le tomaría mucho tiempo escribir el código usted mismo, por lo que es universal confiar en el software de código abierto para extender las capacidades de su lenguaje de programación para realizar tareas específicas».
Los LLM se están volviendo cada vez más populares entre los desarrolladores, que usan los modelos de IA para ayudar a ensamblar programas.
Según el estudio, hasta el 97% de los desarrolladores de software incorporan IA generativa en su flujo de trabajo, y el 30% del código escrito hoy está generado por IA.
Además, muchos lenguajes de programación populares, como Pypi para Python y NPM para JavaScript, dependen del uso de un repositorio de paquetes centralizado. Debido a que los repositorios a menudo son de código abierto, los malos actores pueden cargar código malicioso disfrazado de paquetes legítimos.
Durante años, los atacantes han empleado varios trucos para que los usuarios instalaran su malware. Las alucinaciones de paquetes son la última táctica.
«So, let’s say I ask ChatGPT to help write some code for me and it writes it. Now, let’s say in the generated code it includes a link to some package, and I trust it and run the code, but the package does not exist, it’s some hallucinated package. An astute adversary/hacker could see this behavior (of the LLM) and realize that the LLM is telling people to use this non-existent package, this hallucinated package,» Jadliwala explicó.
«El adversario puede simplemente crear trivialmente un nuevo paquete con el mismo nombre que el paquete alucinado (recomendado por el LLM) e inyectar algún código malo en él.
«Ahora, la próxima vez que el LLM recomienda el mismo paquete en el código generado y un usuario desprevenido ejecuta el código, este paquete malicioso ahora se descarga y ejecuta en la máquina del usuario».
Los investigadores de la UTSA evaluaron la aparición de alucinaciones de paquetes en diferentes lenguajes de programación, configuraciones y parámetros, explorando la probabilidad de recomendaciones erróneas de paquetes e identificando causas raíz.
En 30 pruebas diferentes realizadas por los investigadores de UTSA, 440,445 de 2.23 millones de muestras de código que generaron en Python y JavaScript utilizando modelos LLM referían paquetes alucinados.
De los investigadores de LLMS probados, «los modelos de la serie GPT se encontraron cuatro veces menos probabilidades de generar paquetes alucinados en comparación con los modelos de código abierto, con una tasa de alucinación del 5,2% en comparación con el 21,7%», declaró el estudio. Los investigadores encontraron que el código Python era menos susceptible a las alucinaciones que JavaScript.
Estos ataques a menudo implican nombrar un paquete malicioso para imitar uno legítimo, una táctica conocida como un ataque de confusión. En un ataque de alucinación de paquetes, un usuario de LLM desprevenido se recomendaría que el paquete en su código generado, y confiar en el LLM, descargaría el paquete malicioso creado por el adversario, lo que resulta en un compromiso.
El elemento insidioso de esta vulnerabilidad es que explota una creciente confianza en LLM. A medida que continúan siendo más competentes en las tareas de codificación, los usuarios tendrán más probabilidades de confiar ciegamente en su producción y potencialmente son víctimas de este ataque.
«Si codifica mucho, no es difícil ver cómo sucede esto. Hablamos con mucha gente y casi todos dicen que han notado que les sucedió una alucinación de paquetes mientras están codificando, pero nunca consideraron cómo podría usarse maliciosamente», explicó Spracklen.
«Está fijando mucha confianza implícita en el editor de paquetes que el código que han compartido es legítimo y no malicioso. Pero cada vez que descarga un paquete, está descargando un código potencialmente malicioso y le da acceso completo a su máquina».
Si bien los paquetes generados por referencias cruzadas con una lista maestra pueden ayudar a mitigar las alucinaciones, los investigadores de UTSA dijeron que la mejor solución es abordar la base de LLM durante su propio desarrollo. El equipo ha revelado sus hallazgos a los proveedores de modelos, incluidos OpenAi, Meta, Deepseek y Mistral AI.
Más información:
Joseph Spracklen et al, ¡tenemos un paquete para ti! Un análisis exhaustivo de las alucinaciones de paquetes mediante el código generador de LLMS, arxiv (2024). Doi: 10.48550/arxiv.2406.10279
Citación: AI amenazas en el desarrollo de software reveladas en un nuevo estudio (2025, 8 de abril) Consultado el 8 de abril de 2025 de https://techxplore.com/news/2025-04-ai-threats-software-revealed.html
Este documento está sujeto a derechos de autor. Además de cualquier trato justo con el propósito de estudio o investigación privada, no se puede reproducir ninguna parte sin el permiso por escrito. El contenido se proporciona solo para fines de información.


GIPHY App Key not set. Please check settings