|
|
el año pasado en re: inventar, presentamos la versión preliminar de Amazon Redshift Serverless, una opción sin servidor de Amazon Redshift que le permite analizar datos a cualquier escala sin tener que administrar la infraestructura de almacenamiento de datos. Solo necesita cargar y consultar sus datos, y paga solo por lo que usa. Esto permite que más empresas construyan una estrategia de datos moderna, especialmente para casos de uso donde las cargas de trabajo de análisis no se ejecutan las 24 horas del día, los 7 días de la semana y el almacén de datos no está activo todo el tiempo. También es aplicable a empresas donde el uso de datos se expande dentro de la organización y los usuarios de nuevos departamentos desean ejecutar análisis sin tener que tomar posesión de la infraestructura del almacén de datos.
Hoy, me complace compartir que Amazon Redshift Serverless es generalmente disponible y que agregamos muchas capacidades nuevas. También estamos reduciendo los costos de cómputo sin servidor de Amazon Redshift en comparación con la versión preliminar.
Ahora puede crear varios puntos de enlace sin servidor por cuenta y región de AWS utilizando espacios de nombres y grupos de trabajo:
- A espacio de nombres es una colección de objetos y usuarios de la base de datos, como el nombre y la contraseña de la base de datos, los permisos y la configuración de cifrado. Aquí es donde se administran sus datos y donde puede ver cuánto almacenamiento se utiliza.
- A grupo de trabajo es una colección de recursos informáticos, incluida la configuración de red y seguridad. Cada grupo de trabajo tiene un punto final sin servidor al que puede conectar sus aplicaciones. Al configurar un grupo de trabajo, puede configurar puntos finales privados o de acceso público.
Cada espacio de nombres solo puede tener un grupo de trabajo asociado. Por el contrario, cada grupo de trabajo se puede asociar con un solo espacio de nombres. Puede tener un espacio de nombres sin ningún grupo de trabajo asociado, por ejemplo, para usarlo solo para compartir datos con otros espacios de nombres en la misma cuenta o región de AWS o en otra.
En la configuración de su grupo de trabajo, ahora puede usar reglas de monitoreo de consultas para ayudar a mantener sus costos bajo control. Además, la forma en que Amazon Redshift Serverless escala automáticamente la capacidad del almacén de datos es más inteligente para ofrecer un rendimiento rápido para cargas de trabajo exigentes e impredecibles.
Veamos cómo funciona esto con una demostración rápida. Luego, le mostraré lo que puede hacer con los espacios de nombres y los grupos de trabajo.
Uso de Amazon Redshift sin servidor
En la consola de Amazon Redshift, selecciono Redshift sin servidor en el panel de navegación. Para empezar, elijo Utilizar la configuración predeterminada para configurar un espacio de nombres y un grupo de trabajo con las opciones más comunes. Por ejemplo, podré conectarme usando mi VPC predeterminado y mi grupo de seguridad predeterminado.

Con la configuración predeterminada, la única opción que queda por configurar es permisos. Aquí puedo especificar cómo Amazon Redshift puede interactuar con otros servicios como S3, Amazon CloudWatch Logs, Amazon SageMaker y AWS Glue. Para cargar datos más tarde, doy acceso a Amazon Redshift a un depósito S3. yo elijo Administrar roles de IAM y entonces Crear rol de IAM.
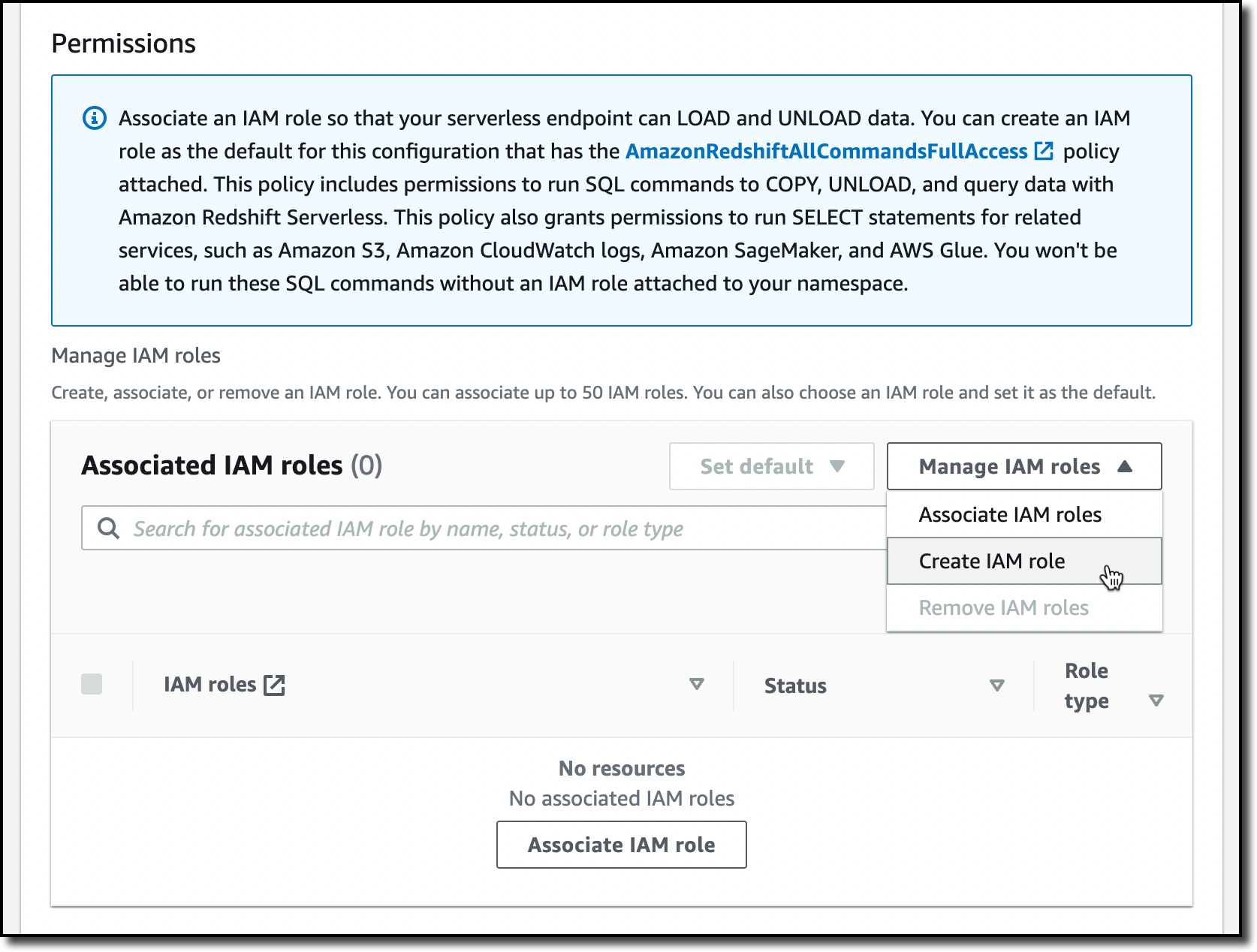
Al crear el rol de IAM, selecciono la opción para dar acceso a cubos S3 específicos y elija un depósito S3 en la misma región de AWS. Entonces, elijo Crear rol de IAM como predeterminado para completar la creación del rol y usarlo automáticamente como el rol predeterminado para el espacio de nombres.

yo elijo Guardar configuración y después de unos minutos la base de datos está lista para usar. En el Tablero sin servidorYo elijo Consulta de datos para abrir el Editor de consultas Redshift v2. Allí, sigo las instrucciones de la guía para desarrolladores de bases de datos de Amazon Redshift para cargar una base de datos de muestra. Si desea hacer una prueba rápida, algunas bases de datos de muestra (incluida la que estoy usando aquí) ya están disponibles en el sample_data_dev base de datos. Tenga en cuenta también que no es necesario cargar datos en Amazon Redshift para ejecutar consultas. Puedo usar datos de un lago de datos S3 en mis consultas creando un esquema externo y una tabla externa.
La base de datos de muestra consta de siete tablas y rastrea la actividad de ventas para un sitio web ficticio «TICKIT», donde los usuarios compran y venden entradas para eventos deportivos, espectáculos y conciertos.
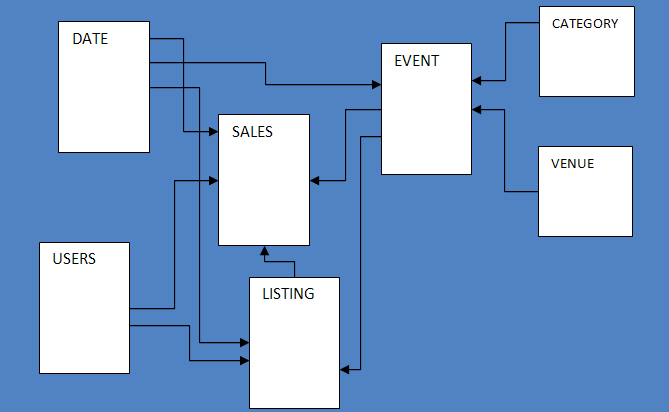
Para configurar el esquema de la base de datos, ejecuto algunos comandos SQL para crear el users, venue, category, date, event, listingy sales mesas.

Luego descargo el tickitdb.zip archivo que contiene los datos de muestra para las tablas de la base de datos. Descomprimo y cargo los archivos en un tickit carpeta en el mismo depósito de S3 que usé al configurar el rol de IAM.
Ahora, puedo usar el comando COPY para cargar los datos del depósito S3 en mi base de datos. Por ejemplo, para cargar datos en el users mesa:
copy users from 's3://MYBUCKET/tickit/allusers_pipe.txt' iam_role default;
El archivo que contiene los datos de la sales la tabla usa valores separados por tabulaciones:
copy sales from 's3://MYBUCKET/tickit/sales_tab.txt' iam_role default delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS';Después de cargar datos en todas las tablas, empiezo a ejecutar algunas consultas. Por ejemplo, la siguiente consulta une cinco tablas para encontrar los cinco principales vendedores de eventos en California (tenga en cuenta que los datos de muestra corresponden al año 2008):
select sellerid, username, (firstname ||' '|| lastname) as sellername, venuestate, sum(qtysold)
from sales, date, users, event, venue
where sales.sellerid = users.userid
and sales.dateid = date.dateid
and sales.eventid = event.eventid
and event.venueid = venue.venueid
and year = 2008
and venuestate="CA"
group by sellerid, username, sellername, venuestate
order by 5 desc
limit 5;
Ahora que mi base de datos está lista, veamos qué puedo hacer configurando espacios de nombres y grupos de trabajo sin servidor de Amazon Redshift.
Uso y configuración de espacios de nombres
Los espacios de nombres son colecciones de datos de bases de datos y sus configuraciones de seguridad. En el panel de navegación de la consola de Amazon Redshift, elijo Configuración del espacio de nombres. En la lista, elijo el default espacio de nombres que acabo de crear.
En el Copias de seguridad pestaña, puedo crear o restaurar una instantánea o restaurar datos desde uno de los puntos de recuperación que se crean automáticamente cada 30 minutos y se conservan durante 24 horas. Eso puede ser útil para recuperar datos en caso de escrituras o eliminaciones accidentales.

En el Seguridad y cifrado pestaña, puedo actualizar los permisos y la configuración de cifrado, incluida la clave de AWS Key Management Service (AWS KMS) utilizada para cifrar y descifrar mis recursos. En esta pestaña, también puedo habilitar el registro de auditoría y exportar los registros de usuario, conexión y actividad del usuario a CloudWatch Logs.

En el Compartir datos pestaña, puedo crear un recurso compartido de datos para compartir datos con otros espacios de nombres y cuentas de AWS en la misma región o en regiones diferentes. En esta pestaña, también puedo crear una base de datos a partir de un recurso compartido que recibo de otros espacios de nombres o cuentas de AWS, y puedo ver las suscripciones para los recursos compartidos de datos administrados por AWS Data Exchange.

Cuando creo un recurso compartido de datos, puedo seleccionar qué objetos incluir. Por ejemplo, aquí quiero compartir solo el date y event tablas porque no contienen datos confidenciales.

Uso y configuración de grupos de trabajo
Los grupos de trabajo son colecciones de recursos informáticos y su configuración de red y seguridad. Proporcionan el punto final sin servidor para el espacio de nombres para el que están configurados. En el panel de navegación de la consola de Amazon Redshift, elijo Configuración del grupo de trabajo. En la lista, elijo el default espacio de nombres que acabo de crear.
En el Acceso a los datos pestaña, puedo actualizar la red y la configuración de seguridad (por ejemplo, cambiar la VPC, las subredes o el grupo de seguridad) o hacer que el punto final sea de acceso público. En esta pestaña, también puedo habilitar Enrutamiento de VPC mejorado para enrutar el tráfico de red entre mi base de datos sin servidor y los repositorios de datos que uso (por ejemplo, los depósitos S3 que se usan para cargar o descargar datos) a través de una VPC en lugar de Internet. Para acceder a puntos finales sin servidor que están en otra VPC o subred, puedo crear un punto de enlace de la VPC administrado por Amazon Redshift.

En el Límites pestaña, puedo configurar la capacidad base (expresada en unidades de procesamiento Redshift o RPU) utilizada para procesar mis consultas. Amazon Redshift Serverless escala la capacidad para tratar con una mayor cantidad de usuarios. Aquí también tengo la opción de aumentar la capacidad base para agilizar mis consultas o disminuirla para reducir costos.
En esta pestaña, también puedo establecer Límites de uso para configurar umbrales diarios, semanales y mensuales para mantener mis costos predecibles. Por ejemplo, configuré un límite diario de 200 RPU-horas y un límite mensual de 2000 RPU-horas para mis recursos informáticos. Para controlar los costos de transferencia de datos para los recursos compartidos de datos entre regiones, configuré un límite diario de 3 TB y un límite semanal de 10 TB. Finalmente, para limitar los recursos utilizados por cada consulta, uso Límites de consulta para agotar el tiempo de espera de las consultas que se ejecutan durante más de 60 segundos.

Disponibilidad y precios
Amazon Redshift Serverless está generalmente disponible hoy en EE. UU. Este (Ohio), EE. UU. Este (Norte de Virginia), EE. UU. Este (Oregón), Europa (Fráncfort), Europa (Irlanda), Europa (Londres), Europa (Estocolmo) y Regiones de AWS de Asia Pacífico (Seúl), Asia Pacífico (Singapur), Asia Pacífico (Sídney) y Asia Pacífico (Tokio).
Puede conectarse a un punto de enlace de grupo de trabajo utilizando sus herramientas de cliente favoritas a través de JDBC/ODBC o con el editor de consultas v2 de Amazon Redshift, una aplicación de cliente SQL basada en web disponible en la consola de Amazon Redshift. Al utilizar aplicaciones basadas en servicios web (como las funciones de AWS Lambda o los cuadernos de Amazon SageMaker), puede acceder a su base de datos y realizar consultas mediante la API de datos integrada de Amazon Redshift.
Con Amazon Redshift Serverless, solo paga por la capacidad informática que consume su base de datos cuando está activa. La capacidad de cómputo aumenta o disminuye automáticamente según su carga de trabajo y se apaga durante los períodos de inactividad para ahorrar tiempo y costos. Tus datos se almacenan en un almacenamiento administrado y pagas una tarifa por GB al mes.
Para brindarle un rendimiento de precios mejorado y la flexibilidad de usar Amazon Redshift Serverless para un conjunto aún más amplio de casos de uso, estamos bajando el precio de $ 0,5 a $ 0,375 por hora de RPU para la región EE. UU. Este (Norte de Virginia). Del mismo modo, estamos bajando el precio en otras regiones en un promedio del 25 por ciento del precio de vista previa. Para obtener más información, consulte la página de precios de Amazon Redshift.
Para ayudarlo a practicar con sus propios casos de uso, también ofrecemos $300 en créditos de AWS durante 90 días para probar Amazon Redshift Serverless. Estos créditos se utilizan para cubrir los costos de computación, almacenamiento y uso de instantáneas de Amazon Redshift Serverless únicamente.
Obtenga información de sus datos en segundos con Amazon Redshift Serverless.
— Danilo

