|
|
Las organizaciones enfrentan una difícil disyuntiva al adaptar los modelos de IA a sus necesidades comerciales específicas: conformarse con modelos genéricos que producen resultados promedio o abordar la complejidad y el costo de la personalización avanzada de modelos. Los enfoques tradicionales obligan a elegir entre un rendimiento deficiente con modelos más pequeños o los altos costos de implementar variantes de modelos más grandes y administrar una infraestructura compleja. El ajuste de refuerzo es una técnica avanzada que entrena modelos utilizando retroalimentación en lugar de conjuntos de datos etiquetados masivos, pero implementarlo generalmente requiere experiencia especializada en aprendizaje automático, infraestructura complicada y una inversión significativa, sin garantía de lograr la precisión necesaria para casos de uso específicos.
Hoy anunciamos un ajuste de refuerzo en Amazon Bedrock, una nueva capacidad de personalización de modelos que crea modelos más inteligentes y rentables que aprenden de los comentarios y ofrecen resultados de mayor calidad para necesidades comerciales específicas. El ajuste de refuerzo utiliza un enfoque basado en retroalimentación en el que los modelos mejoran de forma iterativa en función de señales de recompensa, lo que ofrece ganancias de precisión del 66 % en promedio con respecto a los modelos base.
Amazon Bedrock automatiza el flujo de trabajo de ajuste fino del refuerzo, haciendo que esta técnica avanzada de personalización de modelos sea accesible para los desarrolladores cotidianos sin requerir experiencia profunda en aprendizaje automático (ML) o grandes conjuntos de datos etiquetados.
Cómo funciona el ajuste del refuerzo
El ajuste del refuerzo se basa en los principios del aprendizaje por refuerzo para abordar un desafío común: lograr que los modelos produzcan resultados consistentes que se alineen con los requisitos comerciales y las preferencias del usuario.
Mientras que el ajuste tradicional requiere grandes conjuntos de datos etiquetados y costosas anotaciones humanas, el ajuste por refuerzo adopta un enfoque diferente. En lugar de aprender de ejemplos fijos, utiliza funciones de recompensa para evaluar y juzgar qué respuestas se consideran buenas para casos de uso empresarial particulares. Esto enseña a los modelos a comprender qué constituye una respuesta de calidad sin requerir cantidades masivas de datos de entrenamiento preetiquetados, lo que hace que la personalización avanzada del modelo en Amazon Bedrock sea más accesible y rentable.
Estos son los beneficios de utilizar el ajuste de refuerzo en Amazon Bedrock:
- Facilidad de uso – Amazon Bedrock automatiza gran parte de la complejidad, lo que hace que el ajuste de refuerzo sea más accesible para los desarrolladores que crean aplicaciones de IA. Los modelos se pueden entrenar utilizando registros de API existentes en Amazon Bedrock o cargando conjuntos de datos como datos de entrenamiento, lo que elimina la necesidad de conjuntos de datos etiquetados o configuración de infraestructura.
- Mejor rendimiento del modelo – El ajuste de refuerzo mejora la precisión del modelo en un 66 % en promedio con respecto a los modelos base, lo que permite la optimización del precio y el rendimiento al entrenar variantes de modelo más pequeñas, más rápidas y más eficientes. Esto funciona con el modelo Amazon Nova 2 Lite, lo que mejora la calidad y el precio para necesidades comerciales específicas, y pronto habrá soporte para modelos adicionales.
- Seguridad – Los datos permanecen dentro del entorno seguro de AWS durante todo el proceso de personalización, lo que mitiga los problemas de seguridad y cumplimiento.
La capacidad admite dos enfoques complementarios para proporcionar flexibilidad para optimizar modelos:
- Aprendizaje por refuerzo con recompensas verificables (RLVR) utiliza calificadores basados en reglas para tareas objetivas como generación de código o razonamiento matemático.
- Aprendizaje reforzado a partir de comentarios de IA (RLAIF) emplea jueces basados en inteligencia artificial para tareas subjetivas como seguir instrucciones o moderar contenidos.
Comenzando con el ajuste del refuerzo en Amazon Bedrock
Veamos cómo crear un trabajo de ajuste de refuerzo.
Primero, accedo a la consola de Amazon Bedrock. Luego, navego hasta el Modelos personalizados página. yo elijo Crear y luego elegir Trabajo de ajuste de refuerzo.
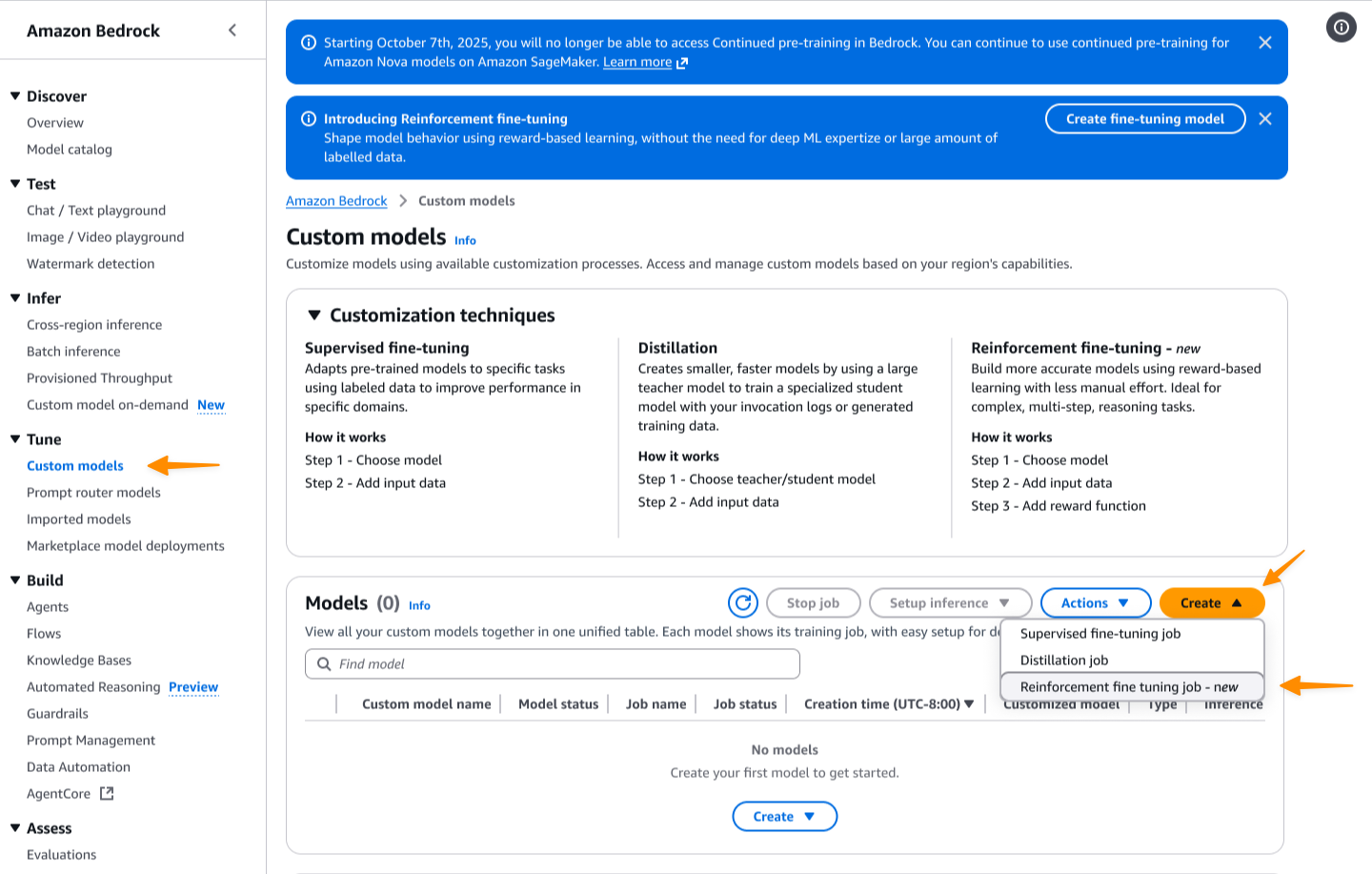
Empiezo ingresando el nombre de este trabajo de personalización y luego selecciono mi modelo base. En el lanzamiento, el ajuste de refuerzo es compatible con Amazon Nova 2 Lite, y próximamente se admitirán modelos adicionales.
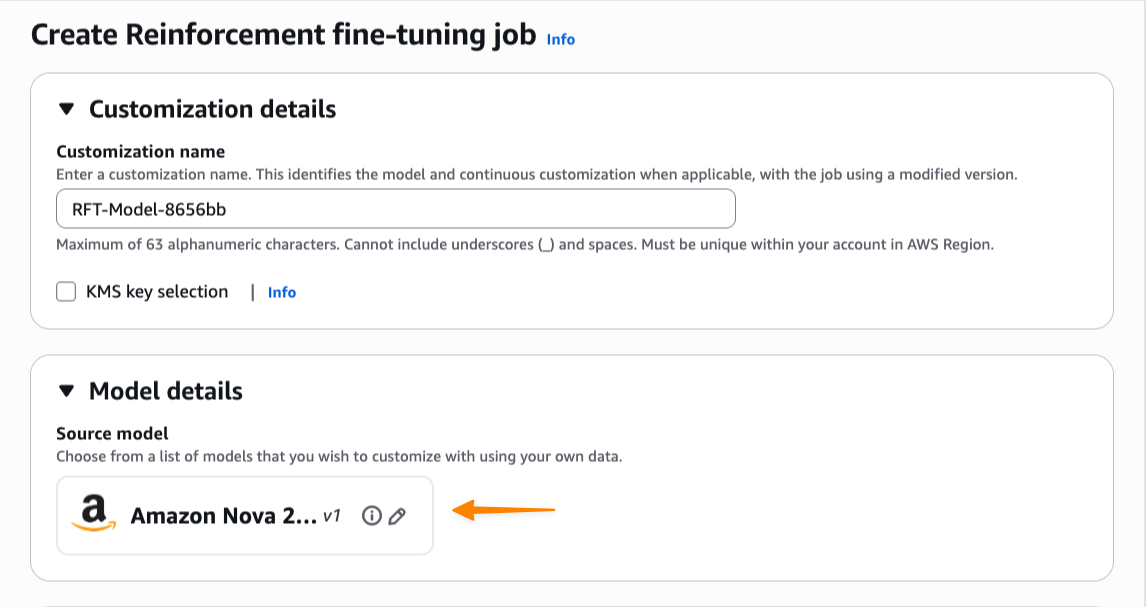
A continuación, necesito proporcionar datos de entrenamiento. Puedo usar mis registros de invocación almacenados directamente, eliminando la necesidad de cargar conjuntos de datos separados. También puedo cargar nuevos archivos JSONL o seleccionar conjuntos de datos existentes de Amazon Simple Storage Service (Amazon S3). El ajuste de refuerzo valida automáticamente mi conjunto de datos de entrenamiento y admite el formato de datos de OpenAI Chat Completions. Si proporciono registros de invocación en el formato de invocación o conversación de Amazon Bedrock, Amazon Bedrock los convierte automáticamente al formato de finalización de chat.
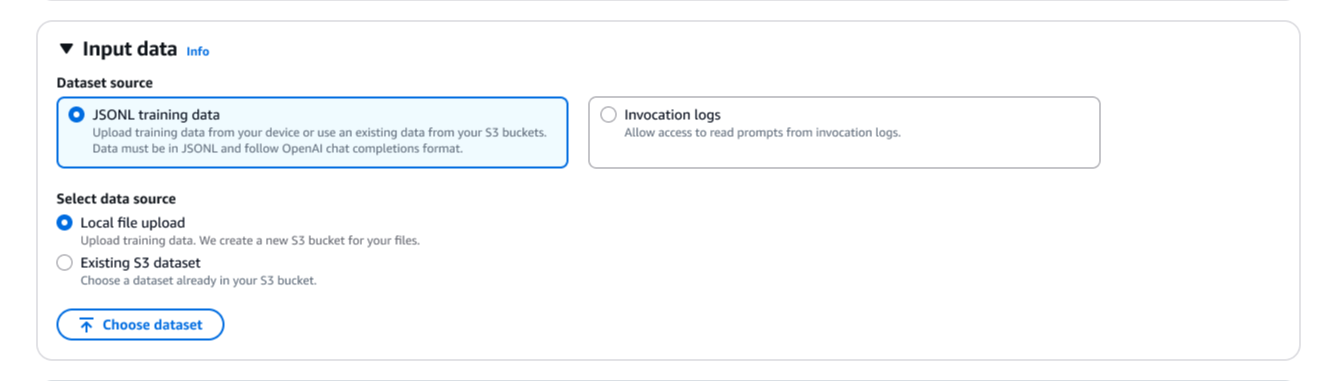
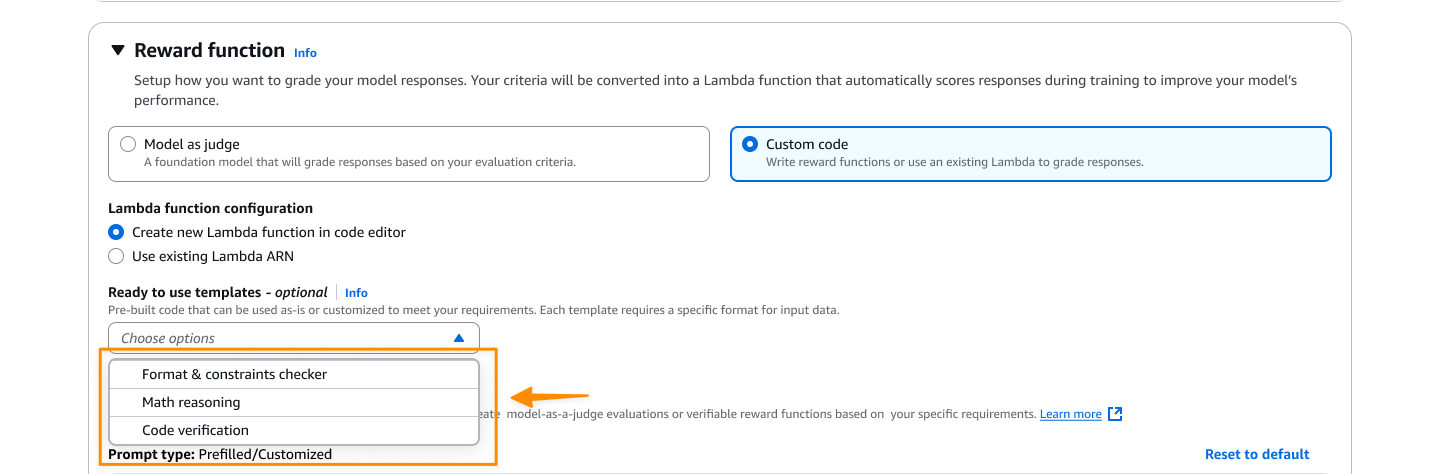
La configuración de la función de recompensa es donde defino lo que constituye una buena respuesta. Tengo dos opciones aquí. Para tareas objetivas, puedo seleccionar código personalizado y escriba código Python personalizado que se ejecute a través de funciones de AWS Lambda. Para evaluaciones más subjetivas, puedo seleccionar Modelo como juez utilizar modelos básicos (FM) como jueces proporcionando instrucciones de evaluación.
Aquí selecciono código personalizadoy creo una nueva función Lambda o uso una existente como función de recompensa. Puedo comenzar con una de las plantillas proporcionadas y personalizarla según mis necesidades específicas.
Opcionalmente, puedo modificar los hiperparámetros predeterminados, como la tasa de aprendizaje, el tamaño del lote y las épocas.

Para mejorar la seguridad, puedo configurar los ajustes de la nube privada virtual (VPC) y el cifrado de AWS Key Management Service (AWS KMS) para cumplir con los requisitos de cumplimiento de mi organización. Entonces elijo Crear para iniciar el trabajo de personalización del modelo.
Durante el proceso de capacitación, puedo monitorear métricas en tiempo real para comprender cómo está aprendiendo el modelo. El panel de métricas de capacitación muestra indicadores clave de rendimiento que incluyen puntuaciones de recompensa, curvas de pérdida y mejoras de precisión a lo largo del tiempo. Estas métricas me ayudan a comprender si el modelo converge correctamente y si la función de recompensa guía eficazmente el proceso de aprendizaje.

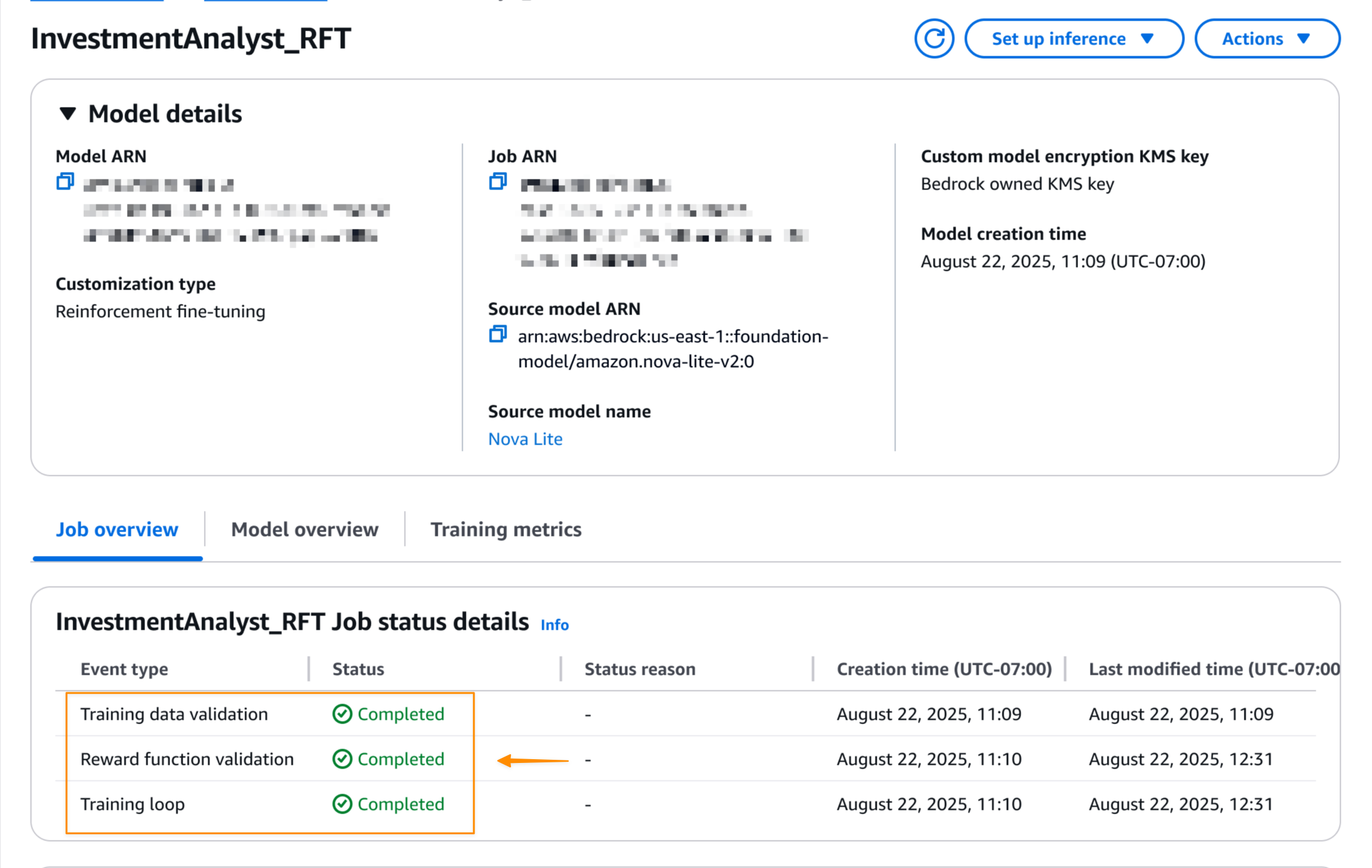
Cuando se completa el trabajo de ajuste fino del refuerzo, puedo ver el estado final del trabajo en la Detalles del modelo página.
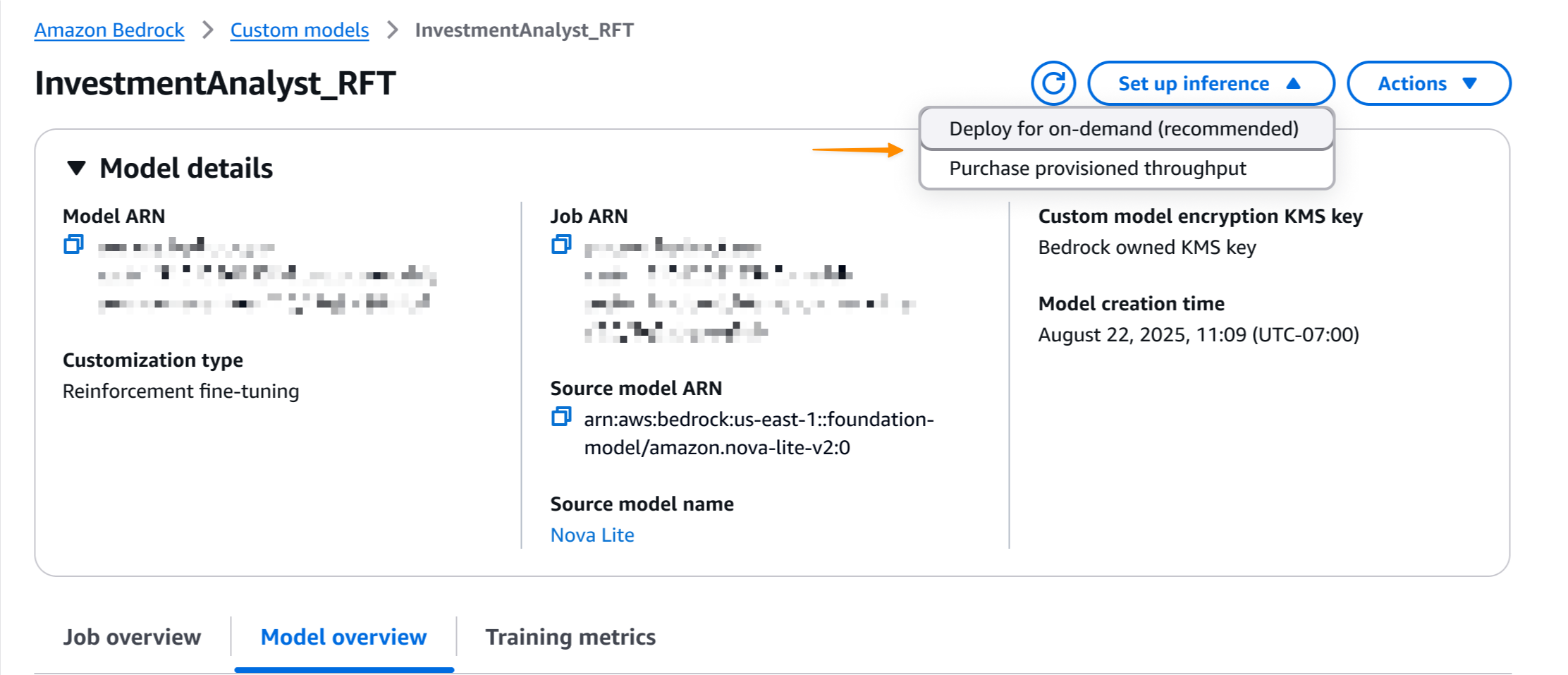
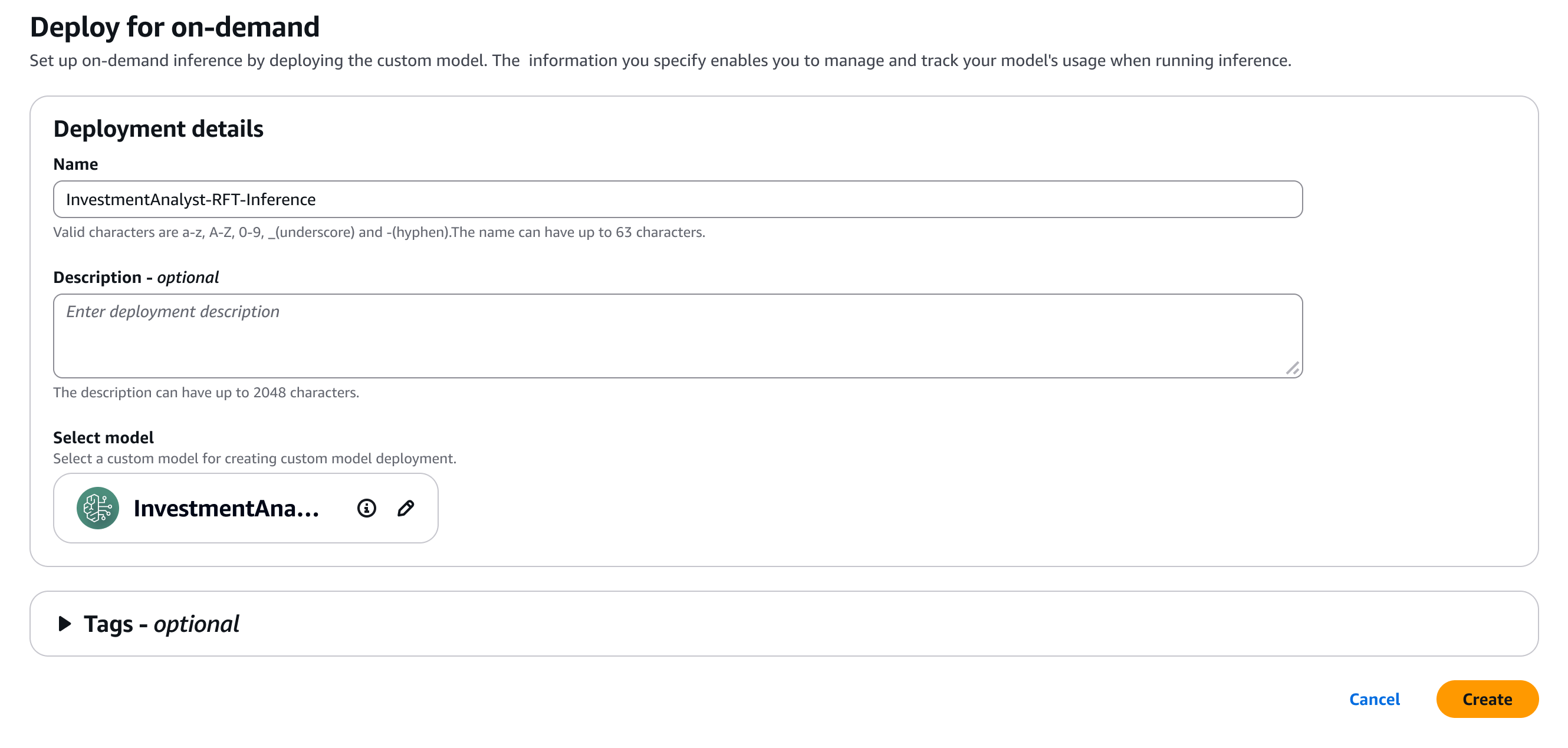
Una vez completado el trabajo, puedo implementar el modelo con un solo clic. yo selecciono Configurar la inferencialuego elige Implementación bajo demanda.
Aquí, proporciono algunos detalles para mi modelo.
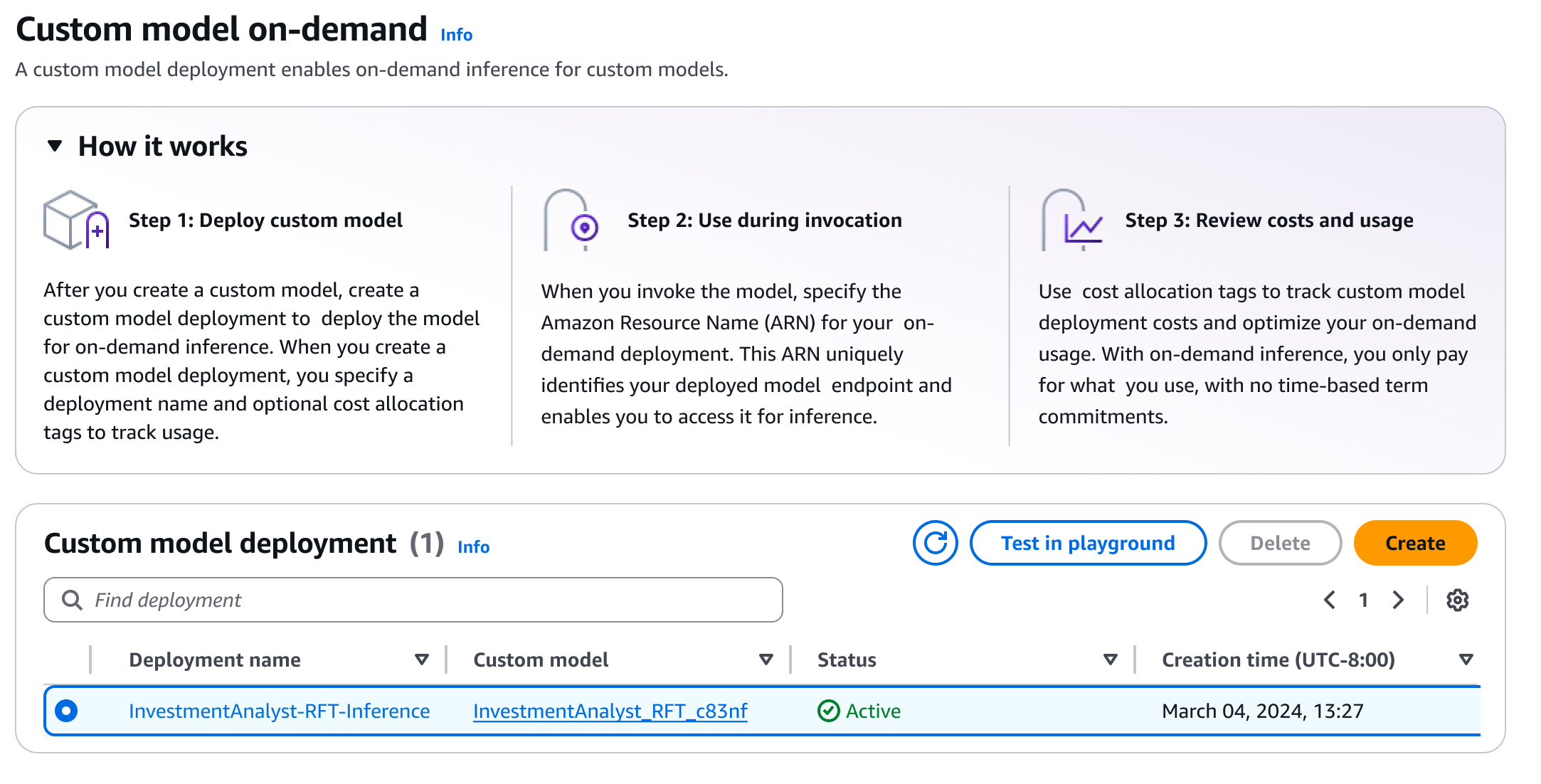
Después de la implementación, puedo evaluar rápidamente el rendimiento del modelo utilizando el área de juegos de Amazon Bedrock. Esto me ayuda a probar el modelo ajustado con indicaciones de muestra y comparar sus respuestas con el modelo base para validar las mejoras. yo selecciono Prueba en el patio de recreo.
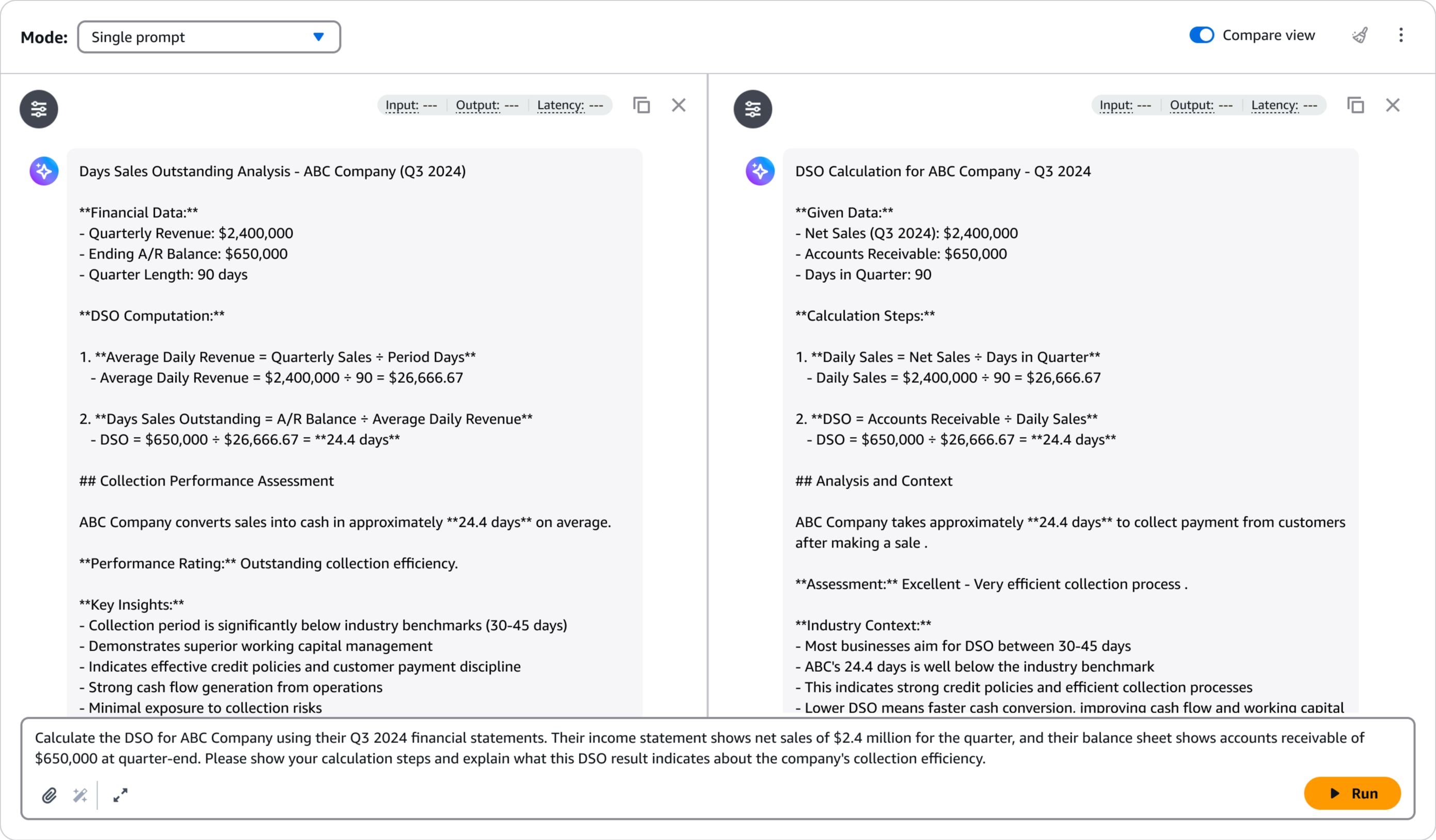
El área de juegos proporciona una interfaz intuitiva para pruebas e iteraciones rápidas, lo que me ayuda a confirmar que el modelo cumple con mis requisitos de calidad antes de integrarlo en las aplicaciones de producción.
Demostración interactiva
Obtenga más información navegando por una demostración interactiva de Ajuste del refuerzo de Amazon Bedrock en acción.

Cosas adicionales que debes saber
Aquí hay puntos clave a tener en cuenta:
- Plantillas — Hay siete plantillas de funciones de recompensa listas para usar que cubren casos de uso comunes para tareas tanto objetivas como subjetivas.
- Precios – Para obtener más información sobre los precios, consulte la página de precios de Amazon Bedrock.
- Seguridad – Los datos de entrenamiento y los modelos personalizados permanecen privados y no se utilizan para mejorar los FM para uso público. Admite cifrado VPC y AWS KMS para mayor seguridad.
Comience con el ajuste de refuerzo visitando la documentación de ajuste de refuerzo y accediendo a la consola de Amazon Bedrock.
¡Feliz edificio!
— donnie

