
|
El pasado diciembre, Sébastien Stormacq escribió sobre la disponibilidad de un estado de mapa distribuido para AWS Step Functions, una nueva característica que le permite orquestar cargas de trabajo paralelas a gran escala en la nube. Fue entonces cuando Charles Burton, un ingeniero de sistemas de datos de una empresa llamada CiberGRX, se enteró y refactorizó su flujo de trabajo, reduciendo el tiempo de procesamiento para su trabajo de procesamiento de aprendizaje automático (ML) de 8 días a 56 minutos. Antes, ejecutar el trabajo requería que un ingeniero lo monitoreara constantemente; ahora, se ejecuta en menos de una hora sin necesidad de soporte. Además, la nueva implementación con AWS Step Functions Distributed Map cuesta menos que lo que costaba originalmente.
Lo que CyberGRX logró con esta solución es un ejemplo perfecto de lo que abarcan las tecnologías sin servidor: permitir que la nube haga la mayor parte posible del trabajo pesado indiferenciado para que los ingenieros y científicos de datos tengan más tiempo para concentrarse en lo que es importante para el negocio. En este caso, eso significa continuar mejorando el modelo y los procesos para una de las ofertas clave de CyberGRX, una evaluación de riesgo cibernético de terceros que utiliza información de ML de su base de datos grande y en crecimiento.
¿Cuál es el desafío empresarial?
CyberGRX comparte datos de riesgo cibernético de terceros (TPCRM) con sus clientes. Predicen, con gran confianza, cómo una empresa de terceros responderá a un cuestionario de evaluación de riesgos. Para ello, deben ejecutar su modelo predictivo en todas las empresas de su plataforma; actualmente cuentan con datos predictivos de más de 225.000 empresas. Cada vez que hay una nueva empresa o los datos cambian para una empresa, regeneran su modelo predictivo procesando todo su conjunto de datos. Con el tiempo, los científicos de datos de CyberGRX mejoran el modelo o le agregan nuevas funciones, lo que también requiere que el modelo se regenere.
El desafío es ejecutar este trabajo para 225 000 empresas de manera oportuna, con la menor cantidad posible de recursos prácticos. El trabajo ejecuta un conjunto de operaciones para cada empresa y cada cálculo de empresa es independiente de otras empresas. Esto significa que, en el caso ideal, todas las empresas pueden procesarse al mismo tiempo. Sin embargo, implementar una paralelización tan masiva es un problema difícil de resolver.
Primera iteración
Con eso en mente, la empresa construyó su primera iteración de la canalización usando Kubernetes y Flujos de trabajo de Argo, un motor de flujo de trabajo nativo de contenedor de código abierto para orquestar trabajos paralelos en Kubernetes. Estas eran herramientas con las que estaban familiarizados, ya que ya las estaban usando en su infraestructura.
Pero tan pronto como intentaron ejecutar el trabajo para todas las empresas en la plataforma, se toparon con los límites de lo que su sistema podía manejar de manera eficiente. Debido a que la solución dependía de un controlador centralizado, Argo Workflows, no era sólida y el controlador se amplió a su capacidad máxima durante este tiempo. En ese momento, solo tenían 150.000 empresas. Y ejecutar el trabajo con todas las empresas tomó alrededor de 8 días, durante los cuales el sistema fallaba y necesitaba reiniciarse. Requería mucha mano de obra y siempre requería un ingeniero de guardia para monitorear y solucionar los problemas del trabajo.
El punto de inflexión se produjo cuando Charles se unió al equipo de Analytics a principios de 2022. Una de sus primeras tareas fue realizar un modelo completo en aproximadamente 170 000 empresas en ese momento. La ejecución del modelo duró toda la semana y finalizó a las 2:00 a. m. de un domingo. Fue entonces cuando decidió que su sistema necesitaba evolucionar.
Segunda iteración
Con el dolor de la última vez que ejecutó el modelo fresco en su mente, Charles pensó en cómo podría reescribir el flujo de trabajo. Su primer pensamiento fue usar AWS Lambda y SQS, pero se dio cuenta de que necesitaba un orquestador en esa solución. Por eso eligió Step Functions, un servicio sin servidor que lo ayuda a automatizar procesos, orquestar microservicios y crear canalizaciones de datos y aprendizaje automático; además, se escala según sea necesario.
Charles obtuvo la nueva versión del flujo de trabajo con Step Functions en aproximadamente 2 semanas. El primer paso que tomó fue adaptar su imagen de Docker existente para que se ejecutara en Lambda utilizando el formato de empaquetado de imágenes de contenedor de Lambda. Debido a que el contenedor ya funcionaba para sus tareas de procesamiento de datos, esta actualización fue simple. Programó la simultaneidad aprovisionada de Lambda para asegurarse de que todas las funciones que necesitaba estuvieran listas cuando comenzara el trabajo. También configuró la simultaneidad reservada para asegurarse de que Lambda pudiera manejar esta cantidad máxima de ejecuciones simultáneas a la vez. Para admitir tantas funciones que se ejecutan al mismo tiempo, aumentó la cuota de ejecución simultánea de Lambda por cuenta.
Y para asegurarse de que los pasos se ejecutaran en paralelo, utilizó funciones de pasos y el estado del mapa. El estado del mapa permitió a Charles ejecutar un conjunto de pasos de flujo de trabajo para cada elemento en un conjunto de datos. Las iteraciones se ejecutan en paralelo. Debido a que el estado del mapa de Step Functions ofrece 40 ejecuciones simultáneas y CyberGRX necesitaba más paralelización, crearon una solución que lanzó varias máquinas de estado en paralelo; de esta manera, pudieron iterar rápidamente en todas las empresas. La creación de esta solución compleja requería un preprocesador que manejara la heurística de la concurrencia del sistema y dividiera los datos de entrada en varias máquinas de estado.
Esta segunda iteración ya era mejor que la primera, ya que ahora podía terminar la ejecución sin problemas, y podía iterar sobre 200.000 empresas en 90 minutos. Sin embargo, el preprocesador era una parte muy compleja del sistema y estaba alcanzando los límites de las API de Lambda y Step Functions debido a la cantidad de paralelización.

Tercera y última iteración
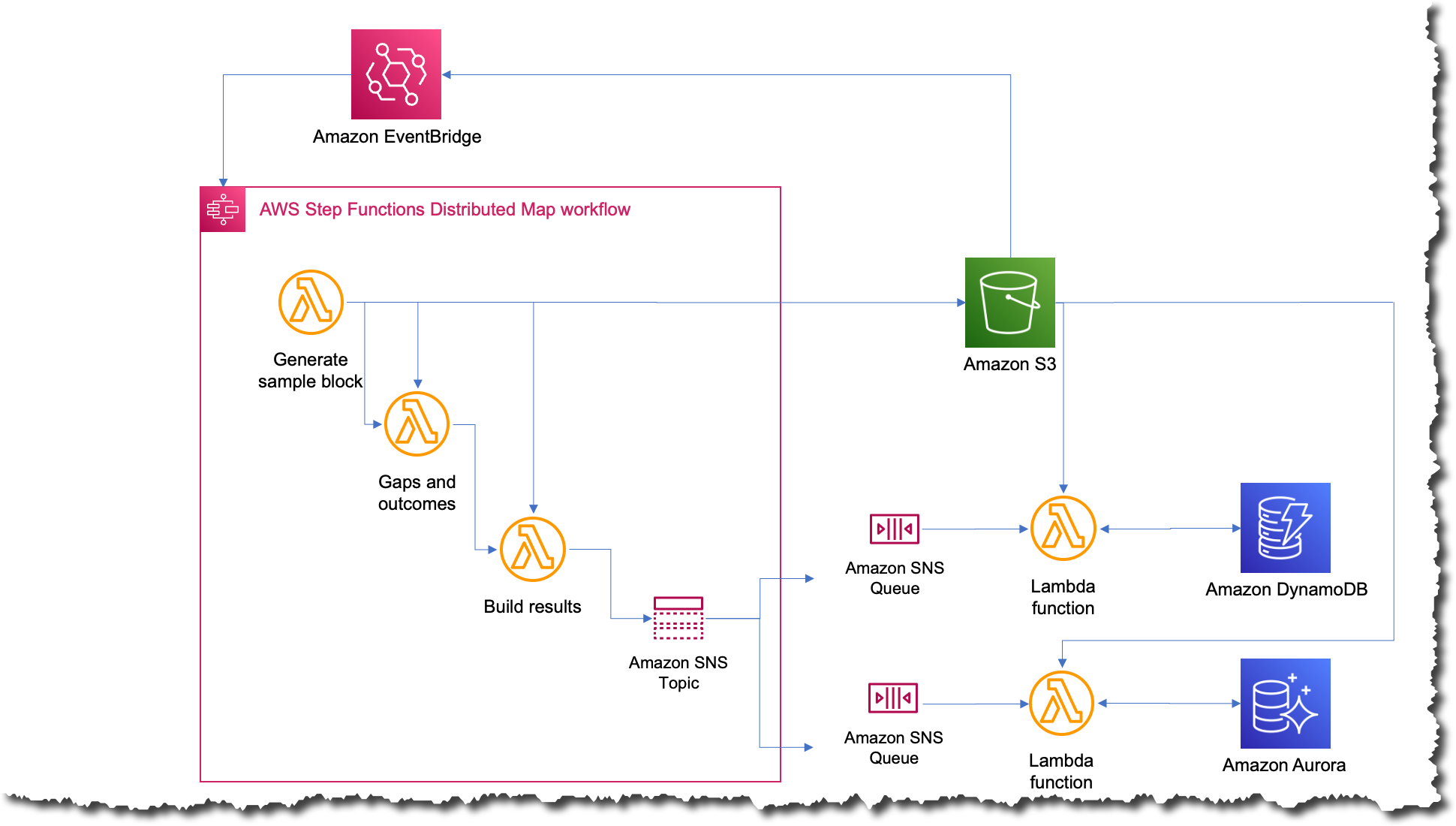
Luego, durante AWS re: inventar 2022, AWS anunció un mapa distribuido para Step Functions, un nuevo tipo de estado de mapa que le permite escribir Step Functions para coordinar cargas de trabajo paralelas a gran escala. Con esta nueva característica, puede iterar fácilmente sobre millones de objetos almacenados en Amazon Simple Storage Service (Amazon S3), y luego el mapa distribuido puede iniciar hasta 10 000 subflujos de trabajo paralelos para procesar los datos.
Cuando Charles leyó en el artículo del blog de noticias sobre las 10 000 ejecuciones de flujo de trabajo en paralelo, inmediatamente pensó en probar este nuevo estado. En un par de semanas, Charles creó la nueva iteración del flujo de trabajo.
Debido a que el estado del mapa distribuido dividió la entrada en diferentes procesadores y manejó la concurrencia de las diferentes ejecuciones, Charles pudo descartar el complejo código del preprocesador.
El nuevo proceso fue el más simple que jamás haya existido; ahora, cada vez que quieren ejecutar el trabajo, simplemente cargan un archivo en Amazon S3 con los datos de entrada. Esta acción desencadena una regla de Amazon EventBridge que apunta a la máquina de estado con el mapa distribuido. Luego, la máquina de estado se ejecuta con ese archivo como entrada y publica los resultados en un tema de Amazon Simple Notification Service (Amazon SNS).
¿Cuál fue el impacto?
Unas semanas después de completar la tercera iteración, tuvieron que ejecutar el trabajo en las 227 000 empresas de su plataforma. Cuando terminó el trabajo, el equipo de Charles quedó impresionado; todo el proceso tardó solo 56 minutos en completarse. Estimaron que durante esos 56 minutos, el trabajo ejecutó más de 57 mil millones de cálculos.

La siguiente imagen muestra un gráfico de Amazon CloudWatch de las ejecuciones simultáneas de una función de Lambda durante el tiempo en que se ejecutó el flujo de trabajo. Hay casi 10.000 funciones ejecutándose en paralelo durante este tiempo.

Simplificar y acortar el tiempo para ejecutar el trabajo abre muchas posibilidades para CyberGRX y el equipo de ciencia de datos. Los beneficios comenzaron de inmediato en el momento en que uno de los científicos de datos quiso ejecutar el trabajo para probar algunas mejoras que habían realizado para el modelo. Pudieron ejecutarlo de forma independiente sin necesidad de que un ingeniero los ayudara.
Y, debido a que el modelo predictivo en sí mismo es una de las ofertas clave de CyberGRX, la empresa ahora tiene un producto más competitivo ya que el análisis predictivo se puede refinar a diario.
Obtenga más información sobre el uso de AWS Step Functions:
También puede consultar el Colección Serverless Workflows que tenemos disponible en Serverless Land para que pruebe y aprenda más sobre esta nueva capacidad.
— Marcia

