. DOI: 10.34133/2022/9820424")
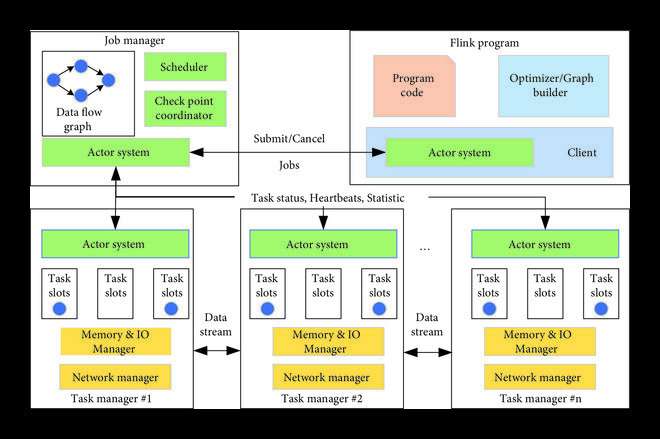
Descripción general de la arquitectura de Apache Flink. Crédito: Computación Inteligente (2022). DOI: 10.34133/2022/9820424
Los datos se pueden comparar con una corriente de agua cuando se genera una gran cantidad de datos de forma continua. Una variedad de datos que incluyen aplicaciones, dispositivos en red, archivos de registro del servidor, diversas actividades en línea y datos basados en la ubicación pueden formar un flujo continuo. A esta forma de procesamiento de datos la llamamos flujo de datos.
En la transmisión de datos, se pueden recopilar, administrar, almacenar, analizar en tiempo real y proporcionar información varios tipos de fuentes de datos. Para la mayoría de los escenarios donde se generan continuamente nuevos datos dinámicos, es beneficioso adoptar el procesamiento de datos de transmisión, que es adecuado para la mayoría de las industrias y casos de uso de big data.
Los sistemas de procesamiento de datos de flujo se utilizan para analizar datos de flujo. Ya existen muchos sistemas de procesamiento de datos de transmisión que las empresas utilizan ampliamente, como Apache Flink, Apache Storm, Spark Streaming y Apache Heron. Estas aplicaciones de procesamiento de flujo de datos se caracterizan por grandes implementaciones y largos tiempos de ejecución (meses o incluso años) en las aplicaciones, y cada aplicación se ejecuta con datos diferentes, por lo que incluso las pequeñas mejoras en el rendimiento pueden tener importantes beneficios financieros para las empresas.
Para mejorar el rendimiento del sistema, los parámetros de configuración de recursos deben ajustarse para especificar la cantidad de recursos, como núcleos de CPU y memoria, utilizados en las tareas. Pero seleccionar parámetros de configuración clave y encontrar sus valores óptimos para las aplicaciones de procesamiento de datos de flujo es un gran desafío, y el ajuste manual de estos parámetros requiere mucho tiempo.
Para una sola aplicación desconocida, un ingeniero de rendimiento, que tiene un conocimiento profundo del sistema de procesamiento de datos de transmisión, puede tardar varios días o incluso semanas en encontrar la configuración de recursos óptima.
Para resolver el problema anterior, los investigadores han comenzado a aplicar métodos de aprendizaje automático para realizar investigaciones. Se publicó un estudio en Computación Inteligente. Los autores utilizaron el programa Apache Flink como una aplicación de procesamiento de datos de transmisión experimental.
El enfoque de aprendizaje automático se utilizó para ajustar de manera automática y eficiente los parámetros de asignación de recursos para la aplicación de procesamiento de flujo de datos. Aplica un algoritmo Random Forest para crear un modelo de rendimiento de alta precisión para un programa de procesamiento de datos de flujo que genera la latencia de cola o el rendimiento de la aplicación, tomando como entrada la velocidad de los datos de entrada y los parámetros de configuración clave. Además, el enfoque de aprendizaje automático aprovecha el algoritmo de optimización bayesiano (BOA) para buscar iterativamente el espacio de configuración de recursos de alta dimensión para lograr un rendimiento óptimo.
Se ha demostrado experimentalmente que este enfoque mejora significativamente la latencia de cola y el rendimiento del percentil 99. El método propuesto en este estudio es una herramienta de ajuste de parámetros independiente del sistema Flink y puede integrarse en otros sistemas de procesamiento de flujo, como Spark Streaming y Apache Storm.
Shixin Huang et al, Ajuste de configuración de recursos para sistemas de procesamiento de datos de flujo a través de la optimización bayesiana, Computación inteligente (2022). DOI: 10.34133/2022/9820424
Proporcionado por Computación Inteligente
Citación: Ajuste automático de las configuraciones de recursos para la transmisión de sistemas de procesamiento de datos mediante aprendizaje automático (2023, 10 de enero) obtenido el 10 de enero de 2023 de https://techxplore.com/news/2023-01-automatically-tuning-resource-configurations-streaming.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.

