
|
|
Me complace anunciar la disponibilidad de un mapa distribuido para las funciones de pasos de AWS. Este flujo amplía el soporte para orquestar cargas de trabajo paralelas a gran escala, como el procesamiento bajo demanda de datos semiestructurados.
El estado del mapa de Step Function ejecuta los mismos pasos de procesamiento para múltiples entradas en un conjunto de datos. El estado del mapa existente está limitado a 40 iteraciones paralelas a la vez. Este límite dificulta escalar las cargas de trabajo de procesamiento de datos para procesar miles de elementos (o incluso más) en paralelo. Para lograr un mayor procesamiento paralelo antes de hoy, tenía que implementar soluciones alternativas complejas para el componente de estado del mapa existente.
El nuevo estado de mapa distribuido le permite escribir funciones de pasos para coordinar cargas de trabajo paralelas a gran escala dentro de sus aplicaciones sin servidor. Ahora puede iterar sobre millones de objetos como registros, imágenes o archivos .csv almacenados en Amazon Simple Storage Service (Amazon S3). El nuevo estado de mapa distribuido puede lanzar hasta diez mil flujos de trabajo paralelos para procesar datos.
Puede procesar datos al componer cualquier API de servicio compatible con Step Functions, pero normalmente invocará funciones de Lambda para procesar los datos con código escrito en su lenguaje de programación favorito.
El mapa distribuido de Step Functions admite una simultaneidad máxima de hasta 10 000 ejecuciones en paralelo, muy por encima de la simultaneidad admitida por muchos otros servicios de AWS. Puede usar la función de simultaneidad máxima del mapa distribuido para asegurarse de no exceder la simultaneidad de un servicio descendente. Hay dos factores a considerar cuando se trabaja con otros servicios. Primero, la concurrencia máxima admitida por el servicio para su cuenta. En segundo lugar, las tasas de ráfaga y rampa, que determinan la rapidez con la que puede lograr la máxima simultaneidad.
Usemos Lambda como ejemplo. La concurrencia de sus funciones es la cantidad de instancias que atienden solicitudes en un momento dado. La cuota de simultaneidad máxima predeterminada para Lambda es 1000 por región de AWS. Puedes pedir un aumento en cualquier momento. Para una ráfaga inicial de tráfico, la simultaneidad acumulativa de sus funciones en una región puede alcanzar un nivel inicial de entre 500 y 3000, que varía según la región. La cuota de simultaneidad en ráfagas se aplica a todas sus funciones en la región.
Cuando utilice un mapa distribuido, asegúrese de verificar la cuota en los servicios de bajada. Limite la simultaneidad máxima del mapa distribuido durante su desarrollo y planifique los aumentos de cuota de servicio en consecuencia.
Para comparar el nuevo mapa distribuido con el flujo de estado del mapa original, creé esta tabla.
| Flujo de estado del mapa original | Nuevo flujo de mapa distribuido | |
| Subflujos de trabajo |
|
|
| Ramas paralelas | Las iteraciones de mapas se ejecutan en paralelo, con una simultaneidad máxima efectiva de alrededor de 40 a la vez. | Puede pasar millones de elementos a varias ejecuciones secundarias, con una simultaneidad de hasta 10 000 ejecuciones a la vez. |
| Fuente de entrada | Acepta solo una matriz JSON como entrada. | Acepta entradas como lista de objetos de Amazon S3, arreglos o archivos JSON, archivos csv o inventario de Amazon S3. |
| Carga útil | 256 KB | Cada iteración recibe una referencia a un archivo (Amazon S3) o un solo registro de un archivo (entrada de estado). La capacidad real de procesamiento de archivos está limitada por el almacenamiento y la memoria de Lambda. |
| Historial de ejecución | 25.000 eventos | Cada iteración del estado del mapa es una ejecución secundaria, con hasta 25 000 eventos cada una (el modo rápido no tiene límite en el historial de ejecución). |
Los subflujos de trabajo dentro de un mapa distribuido funcionan tanto con los flujos de trabajo estándar como con los flujos de trabajo exprés de baja latencia y corta duración.
Esta nueva capacidad está optimizada para funcionar con S3. Puedo configurar el depósito y el prefijo donde se almacenan mis datos directamente desde la configuración del mapa distribuido. El mapa distribuido deja de leer después de 100 millones de elementos y admite archivos JSON o csv de hasta 10 GB.
Cuando procese archivos de gran tamaño, piense en las capacidades del servicio posterior. Tomemos Lambda nuevamente como ejemplo. Cada entrada, un archivo en S3, por ejemplo, debe caber dentro del entorno de ejecución de la función Lambda en términos de memoria y almacenamiento temporal. Para facilitar el manejo de archivos grandes, Herramientas eléctricas de Lambda para Python introducido una nueva función de transmisión para obtener, transformar y procesar objetos de S3 con un consumo de memoria mínimo. Esto permite que sus funciones de Lambda manejen archivos más grandes que el tamaño de su entorno de ejecución. Para obtener más información sobre esta nueva capacidad, consulte la documentación de Lambda Powertools.
Veámoslo en acción
Para esta demostración, crearé un flujo de trabajo que procese mil imágenes de perros almacenadas en S3. Las imágenes ya están almacenadas en S3.
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/
2022-11-08 15:03:36 27034 n02085620_10074.jpg
2022-11-08 15:03:36 34458 n02085620_10131.jpg
2022-11-08 15:03:36 12883 n02085620_10621.jpg
2022-11-08 15:03:36 34910 n02085620_1073.jpg
...
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/ | wc -l
1000El flujo de trabajo y el depósito de S3 deben estar en la misma región.
Para comenzar, navego a la página Step Functions de la consola de administración de AWS y selecciono Crear máquina de estado. En la página siguiente, elijo diseñar mi flujo de trabajo usando el editor visual. El mapa distribuido funciona con Estándar flujos de trabajo, y mantengo la selección predeterminada como está. Yo selecciono próximo para entrar en el editor visual.
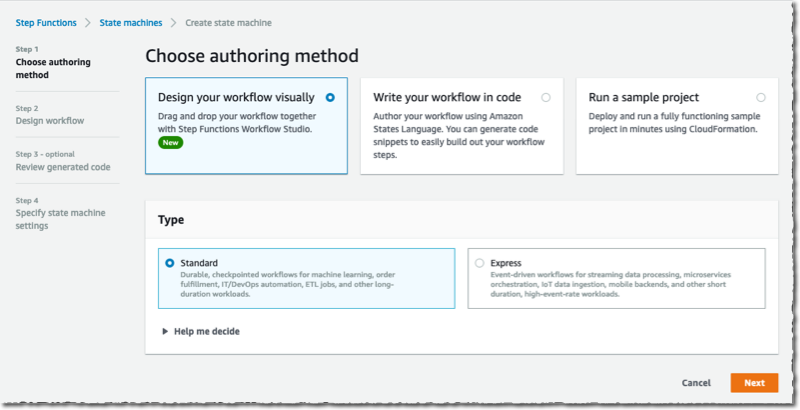 En el editor visual, busco y selecciono el Mapa componente en el panel del lado izquierdo y lo arrastro al área de flujo de trabajo. En el lado derecho, configuro el componente. yo elijo Repartido como modo de procesamiento y Amazonas S3 como Origen del artículo.
En el editor visual, busco y selecciono el Mapa componente en el panel del lado izquierdo y lo arrastro al área de flujo de trabajo. En el lado derecho, configuro el componente. yo elijo Repartido como modo de procesamiento y Amazonas S3 como Origen del artículo.
Los mapas distribuidos se integran de forma nativa con S3. Ingreso el nombre del cubo (awsnewsblog-distributed-map) y el prefijo (images) donde se almacenan mis imágenes.
 Sobre el Configuración de tiempo de ejecución sección, elijo Expresar por Tipo de flujo de trabajo secundario. También puedo decidir restringir la límite de concurrenciat. Ayuda a garantizar que operamos dentro de las cuotas de simultaneidad de los servicios posteriores (Lambda en esta demostración) para una cuenta o región en particular.
Sobre el Configuración de tiempo de ejecución sección, elijo Expresar por Tipo de flujo de trabajo secundario. También puedo decidir restringir la límite de concurrenciat. Ayuda a garantizar que operamos dentro de las cuotas de simultaneidad de los servicios posteriores (Lambda en esta demostración) para una cuenta o región en particular.
De forma predeterminada, la salida de mis subflujos de trabajo se agregará como salida de estado, hasta 256 KB. Para procesar resultados más grandes, puedo optar por Exporte los resultados del estado del mapa a Amazon S3.

Finalmente, defino qué hacer para cada archivo. En esta demostración, quiero invocar una función Lambda para cada archivo en el depósito S3. La función ya existe. Busco y selecciono la acción de invocación de Lambda en el panel del lado izquierdo. Lo arrastro al componente de mapa distribuido. Luego, uso el panel de configuración del lado derecho para seleccionar la función Lambda real para invocar: AWSNewsBlogDistributedMap en este ejemplo.
Cuando termino, selecciono próximo. Yo selecciono próximo de nuevo en el Revisar el código generado página (no se muestra aquí).
Sobre el Especificar la configuración de la máquina de estado página, ingreso un Nombre para mi máquina de estado y el IAM permisos correr. Luego, selecciono Crear máquina de estado.
 Ahora estoy listo para comenzar la ejecución. En la página Máquina de estado, selecciono el nuevo flujo de trabajo y selecciono Iniciar ejecución. Opcionalmente, puedo ingresar un documento JSON para pasar al flujo de trabajo. En esta demostración, el flujo de trabajo no maneja los datos de entrada. Lo dejo como está y selecciono Iniciar ejecución.
Ahora estoy listo para comenzar la ejecución. En la página Máquina de estado, selecciono el nuevo flujo de trabajo y selecciono Iniciar ejecución. Opcionalmente, puedo ingresar un documento JSON para pasar al flujo de trabajo. En esta demostración, el flujo de trabajo no maneja los datos de entrada. Lo dejo como está y selecciono Iniciar ejecución.
 |
 |
Durante la ejecución del flujo de trabajo, puedo monitorear el progreso. Observo el número de iteraciones y el número de elementos procesados con éxito o con error.
 Puedo profundizar en una ejecución específica para ver los detalles.
Puedo profundizar en una ejecución específica para ver los detalles.
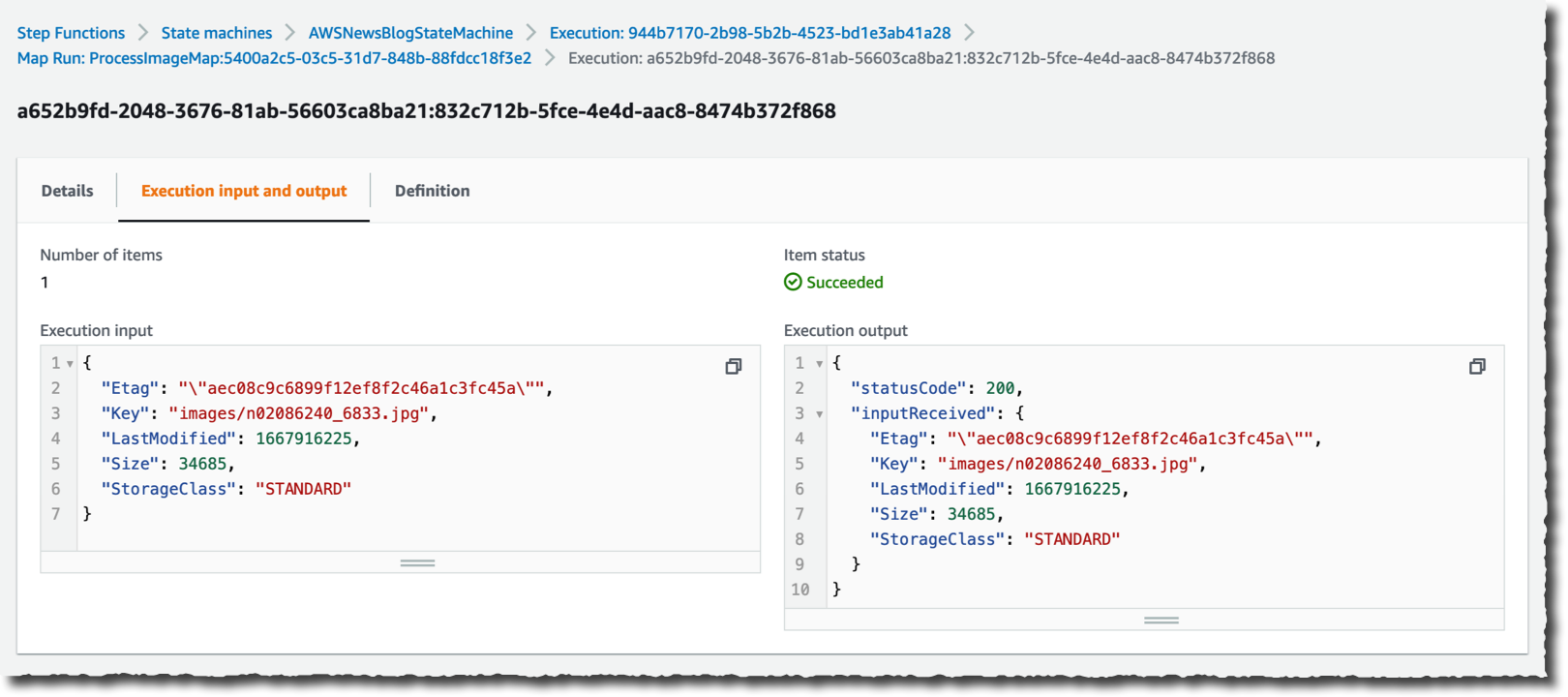
Con solo unos pocos clics, creé un flujo de trabajo a gran escala y muy paralelo capaz de manejar una gran cantidad de datos.
¿Qué servicio de AWS debo usar?
Como sucede a menudo en AWS, es posible que observe una superposición entre esta nueva capacidad y los servicios existentes, como AWS Glue, Amazon EMR o Amazon S3 Batch Operations. Tratemos de diferenciar los casos de uso.
En mi modelo mental, los científicos de datos y los ingenieros de datos usan AWS Glue y EMR para procesar grandes cantidades de datos. Por otro lado, los desarrolladores de aplicaciones usarán Step Functions para agregar procesamiento de datos sin servidor a sus aplicaciones. Step Functions puede escalar desde cero rápidamente, lo que lo convierte en una buena opción para cargas de trabajo interactivas donde los clientes pueden estar esperando los resultados. Por último, es probable que los administradores de sistemas y los equipos de operaciones de TI utilicen las operaciones por lotes de Amazon S3 para operaciones de automatización de TI de un solo paso, como copiar, etiquetar o cambiar permisos en miles de millones de objetos de S3.
Precios y disponibilidad
El mapa distribuido de AWS Step Functions está generalmente disponible en las siguientes diez regiones de AWS: EE. UU. Este (Ohio, N. Virginia), EE. UU. Oeste (Oregón), Asia Pacífico (Singapur, Sídney, Tokio), Canadá (Central) y Europa ( Fráncfort, Irlanda, Estocolmo).
El modelo de precios para el estado del mapa en línea existente no cambia. Para el nuevo estado del mapa distribuido, cobramos una transición de estado por iteración. El precio varía según las regiones y comienza en $0,025 por cada 1000 transiciones de estado. Cuando procesa sus datos utilizando flujos de trabajo rápidos, también se le cobra en función de la cantidad de solicitudes de su flujo de trabajo y su duración. Una vez más, los precios varían entre regiones, pero comienzan en $1,00 por 1 millón de solicitudes y $0,06 por GB-hora (prorrateado a 100 ms).
Para la misma cantidad de iteraciones, observará una reducción de costos al usar la combinación del mapa distribuido y los flujos de trabajo estándar en comparación con el mapa en línea existente. Cuando utilice flujos de trabajo rápidos, espere que los costos se mantengan iguales para obtener más valor con el mapa distribuido.
Estoy realmente emocionado de descubrir lo que construirá utilizando esta nueva capacidad y cómo desbloqueará la innovación. ¡Comience hoy mismo a crear flujos de trabajo de procesamiento de datos sin servidor altamente paralelos!

