|
|
En 2019, presentamos Amazon SageMaker Studio, el primer entorno de desarrollo (IDE) totalmente integrado para ciencia de datos y aprendizaje automático (ML). SageMaker Studio le brinda acceso a servicios totalmente administrados Jupyter Notebooks que se integran con herramientas especialmente diseñadas para realizar todos los pasos de ML, desde la preparación de datos hasta el entrenamiento y la depuración de modelos, el seguimiento de experimentos, la implementación y el seguimiento de modelos y la gestión de canalizaciones.
Hoy, estoy emocionado de anunciar la próxima generación de portátiles Amazon SageMaker para aumentar la eficiencia en todo el flujo de trabajo de desarrollo de ML. Ahora puede mejorar la calidad de los datos en minutos con la capacidad de preparación de datos integrada, editar los mismos cuadernos con sus equipos en tiempo real y convertir automáticamente el código del cuaderno en trabajos listos para la producción.
¡Déjame mostrarte lo nuevo!
Nueva capacidad de notebook para preparación de datos simplificada
La nueva capacidad de preparación de datos integrada cuenta con la tecnología de Amazon SageMaker Data Wrangler y está disponible en las notebooks de SageMaker Studio. Los cuadernos de SageMaker Studio generan automáticamente visualizaciones clave además de Marcos de datos de pandas para ayudarlo a comprender la distribución de datos e identificar problemas de calidad de datos, como valores faltantes, datos no válidos y valores atípicos. También puede seleccionar la columna de destino para los modelos de ML y generar información específica de ML, como columnas de clase desequilibrada o alta correlación. A continuación, recibe recomendaciones de transformaciones de datos para resolver los problemas. Puede aplicar las transformaciones de datos directamente en la interfaz de usuario y los cuadernos de SageMaker Studio generan automáticamente el código de transformación correspondiente en las celdas del cuaderno que puede usar para reproducir su proceso de preparación de datos.
Uso de la capacidad de preparación de datos incorporada
Para comenzar, instala e importa pip sagemaker_datawrangler junto con pandas Paquete Python. Luego, descargue el conjunto de datos que desea analizar en el directorio de trabajo del cuaderno y lea el conjunto de datos con pandas.
import pandas as pd
import sagemaker_datawrangler
!aws s3 cp s3://<YOUR_S3_BUCKET>/data.csv .
df = pd.read_csv("data.csv")
Ahora, cuando muestra el marco de datos, automáticamente muestra visualizaciones de datos clave en la parte superior de cada columna, muestra información de los datos, detecta problemas de calidad de los datos y sugiere soluciones para mejorar la calidad de los datos. Cuando selecciona una columna como la columna de destino para las predicciones de ML, obtiene información y advertencias específicas del destino, como tipos de datos mixtos en el destino (para casos de uso de regresión) o muy pocas instancias por clase (para casos de uso de clasificación).
En este ejemplo, estoy usando el Reseñas de ropa de comercio electrónico para mujeres Conjunto de datos que contiene reseñas y valoraciones de clientes sobre ropa de mujer. Este conjunto de datos se obtuvo de Kaggle y ha sido modificado por Amazon para agregar problemas de calidad de datos sintéticos.

Puede revisar las transformaciones de datos sugeridas para mejorar la calidad de los datos y aplicarlas directamente en la interfaz de usuario. Para obtener una lista de todas las transformaciones de datos admitidas, consulte la documentación. Una vez que aplica una transformación de datos, los cuadernos de SageMaker Studio generan automáticamente el código para reproducir esos pasos de preparación de datos en otra celda del cuaderno.
Para mi ejemplo, selecciono Rating como mi columna objetivo. La información de la columna de destino me dice en una advertencia de alta prioridad que esta columna tiene muy pocas instancias por clase y con una advertencia de prioridad media que las clases están demasiado desequilibradas. Sigamos las sugerencias y eliminemos los valores objetivo raros y los valores faltantes. También seguiré las sugerencias para algunas de las columnas de funciones y eliminaré los valores faltantes en el Review Text columna y suelte el Division Name columna.
Una vez que aplico las transformaciones, el cuaderno genera este código para mí:
# Pandas code generated by sagemaker_datawrangler
output_df = df.copy(deep=True)
# Code to Drop rare target values for column: Rating to resolve warning: Too few instances per class
rare_target_labels_to_drop = ['-100', '100']
output_df = output_df[~output_df['Rating'].isin(rare_target_labels_to_drop)]
# Code to Drop missing for column: Rating to resolve warning: Missing values
output_df = output_df[output_df['Rating'].notnull()]
# Code to Drop missing for column: Review Text to resolve warning: Missing values
output_df = output_df[output_df['Review Text'].notnull()]
# Code to Drop column for column: Division Name to resolve warning: Missing values
output_df=output_df.drop(columns=['Division Name'])Ahora puedo revisar y modificar el código si es necesario o comenzar a integrar las transformaciones de datos como parte de mi flujo de trabajo de desarrollo de ML.
Presentación de espacios compartidos para compartir en equipo y colaboración en tiempo real
SageMaker Studio ahora ofrece espacios compartidos que brindan a los equipos de ciencia de datos y ML un espacio de trabajo donde pueden leer, editar y ejecutar cuadernos juntos en tiempo real para optimizar la colaboración y la comunicación durante el proceso de desarrollo. Los espacios compartidos proporcionan un directorio compartido de Amazon EFS que puede utilizar para compartir archivos dentro de un espacio compartido. Todos los recursos de SageMaker que se pueden etiquetar que crea en un espacio compartido se etiquetan automáticamente para ayudarlo a organizar y tener una vista filtrada de sus recursos de ML, como trabajos de capacitación, experimentos y modelos, que son relevantes para el problema comercial en el que trabaja en el espacio. Esto también lo ayuda a controlar los costos y planificar presupuestos mediante herramientas como AWS Budgets y AWS Cost Explorer.
Y eso no es todo. Ahora también puede crear varios dominios de SageMaker dentro de la misma cuenta de AWS para limitar el acceso y aislar recursos para diferentes equipos o unidades comerciales en su organización. Ahora, permítame mostrarle cómo crear un espacio compartido para usuarios dentro de un dominio de SageMaker.
Uso de espacios compartidos
Puede utilizar la consola de SageMaker o la CLI de AWS para crear espacios compartidos para un dominio de SageMaker. Para comenzar en la consola de SageMaker, vaya a Dominiosseleccione o cree un nuevo dominio y seleccione Administracion del espacio sobre el Detalles del dominio página. Luego, seleccione Crear y asigne un nombre al espacio compartido.
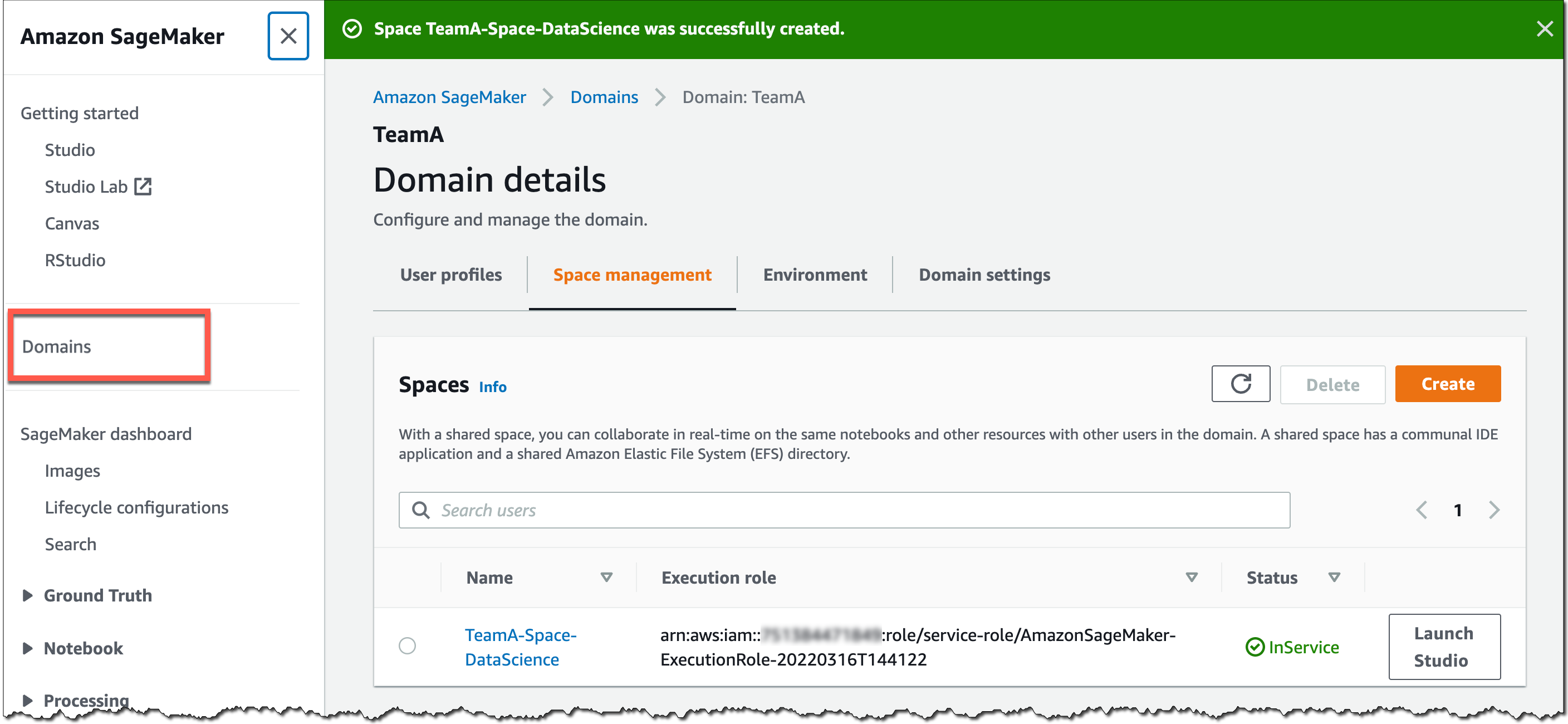
Los usuarios de este dominio de SageMaker ahora pueden iniciar y unirse al espacio compartido a través de sus perfiles de usuario de dominio de SageMaker.
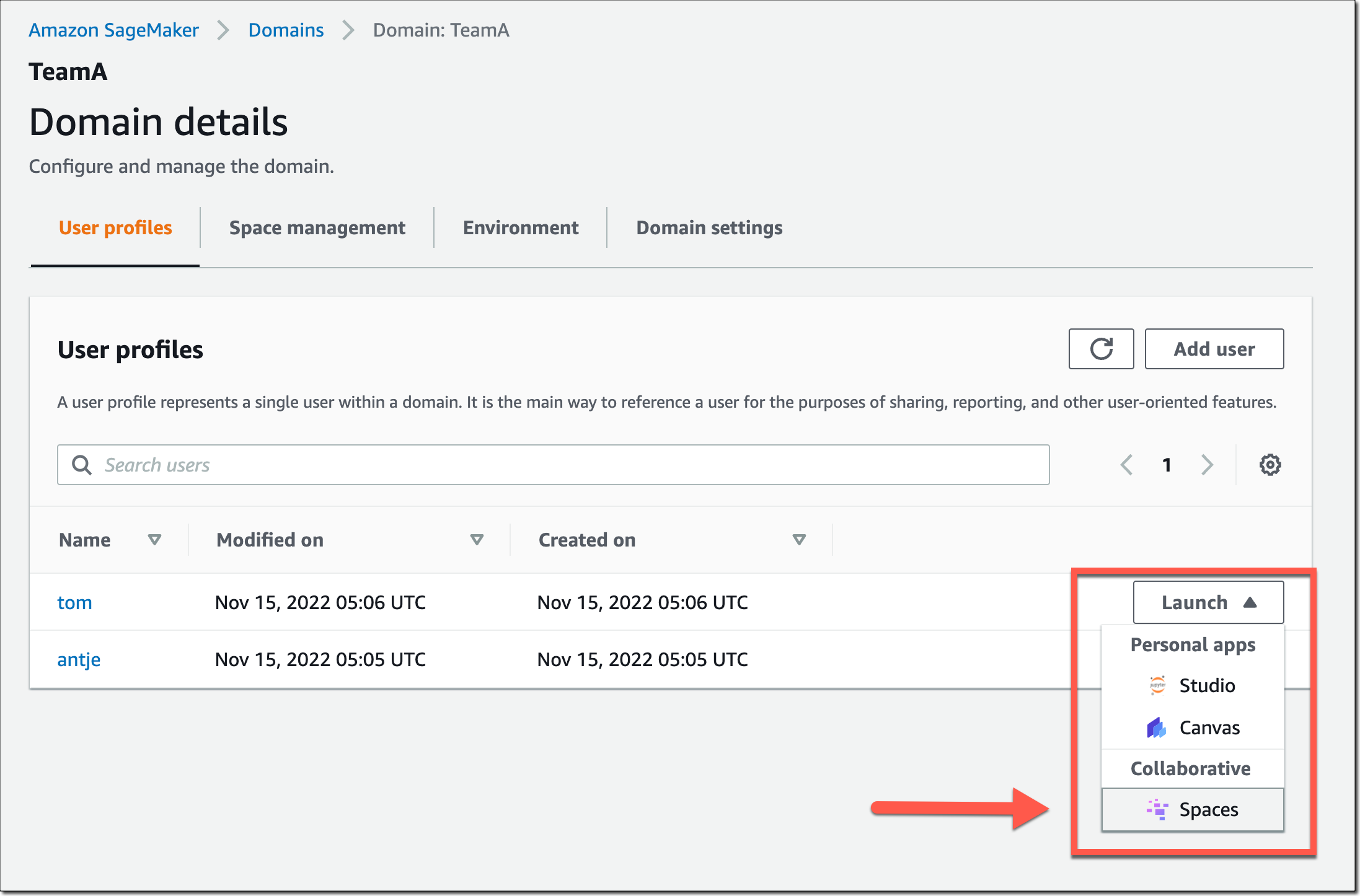
En un espacio compartido, seleccione el nuevo Colaboradores icono en el menú de navegación izquierdo. Ahora puede ver quién más está actualmente activo en este espacio. La siguiente captura de pantalla muestra al usuario Tomás a la izquierda, editando un archivo de bloc de notas. A la derecha, usuario antje ve las ediciones en tiempo real, junto con una anotación del nombre de usuario que actualmente edita esa celda del cuaderno.

Nueva capacidad de notebook para convertir automáticamente el código de notebook en trabajos listos para producción
Ahora puede seleccionar un cuaderno y automatizarlo como un trabajo que puede ejecutarse en un entorno de producción sin necesidad de administrar la infraestructura subyacente. Cuando creas un Trabajo de cuaderno de SageMaker, SageMaker Studio toma una instantánea de todo el bloc de notas, empaqueta sus dependencias en un contenedor, crea la infraestructura, ejecuta el bloc de notas como un trabajo automatizado según una programación que defina y desaprovisiona la infraestructura al finalizar el trabajo. Esta capacidad de notebook ahora también está disponible en Laboratorio de SageMaker Studionuestro entorno de desarrollo de ML gratuito que proporciona la computación, el almacenamiento y la seguridad para aprender y experimentar con ML.
Uso de la capacidad de notebook para automatizar notebooks
Para comenzar, abra un archivo de bloc de notas en SageMaker Studio. Luego, haga clic con el botón derecho en el archivo de su cuaderno y seleccione Crear trabajo de cuaderno o seleccione el Crear trabajo de cuaderno icono, como se destaca en la siguiente captura de pantalla.
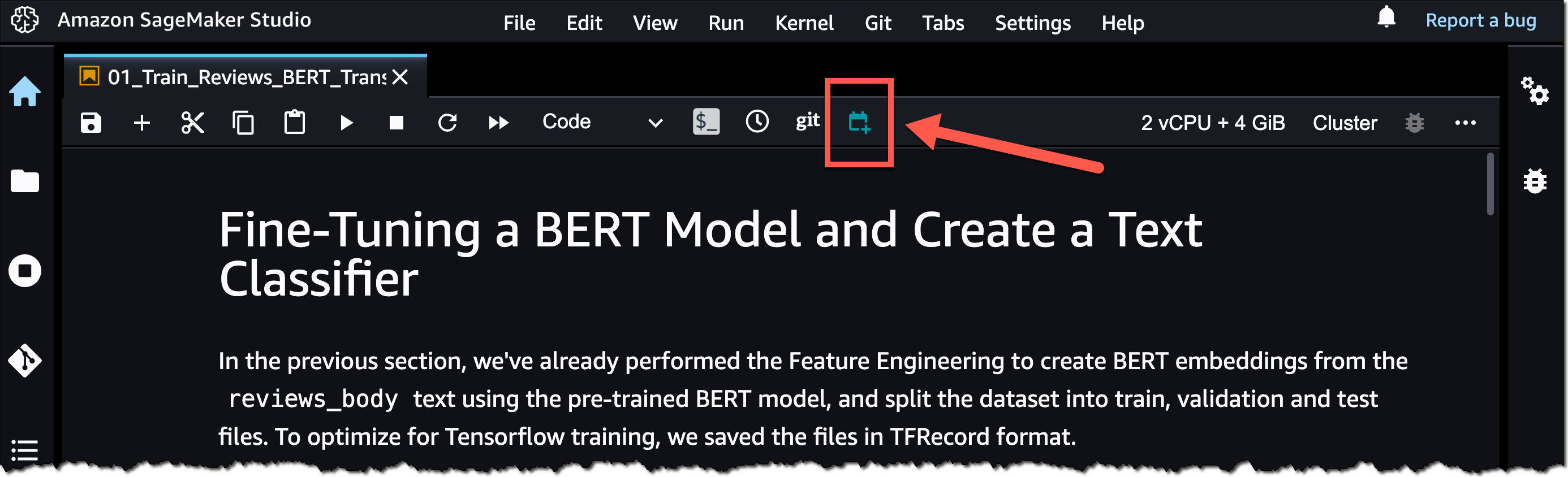
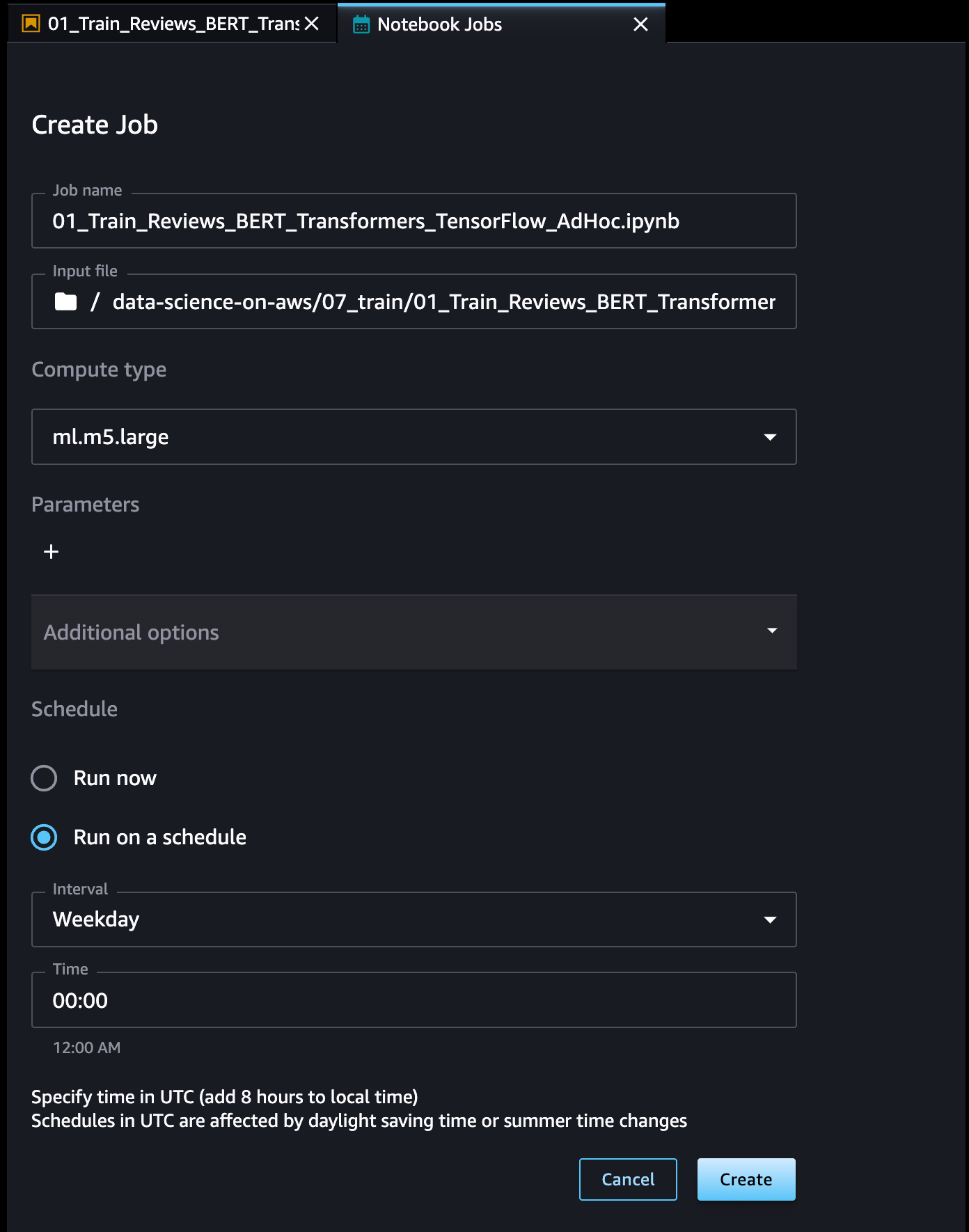
Defina un nombre para el Trabajo de cuaderno, revise la ubicación del archivo de entrada, especifique el tipo de cómputo que se usará y si ejecutará el trabajo inmediatamente o según un cronograma. Luego, seleccione Crear.
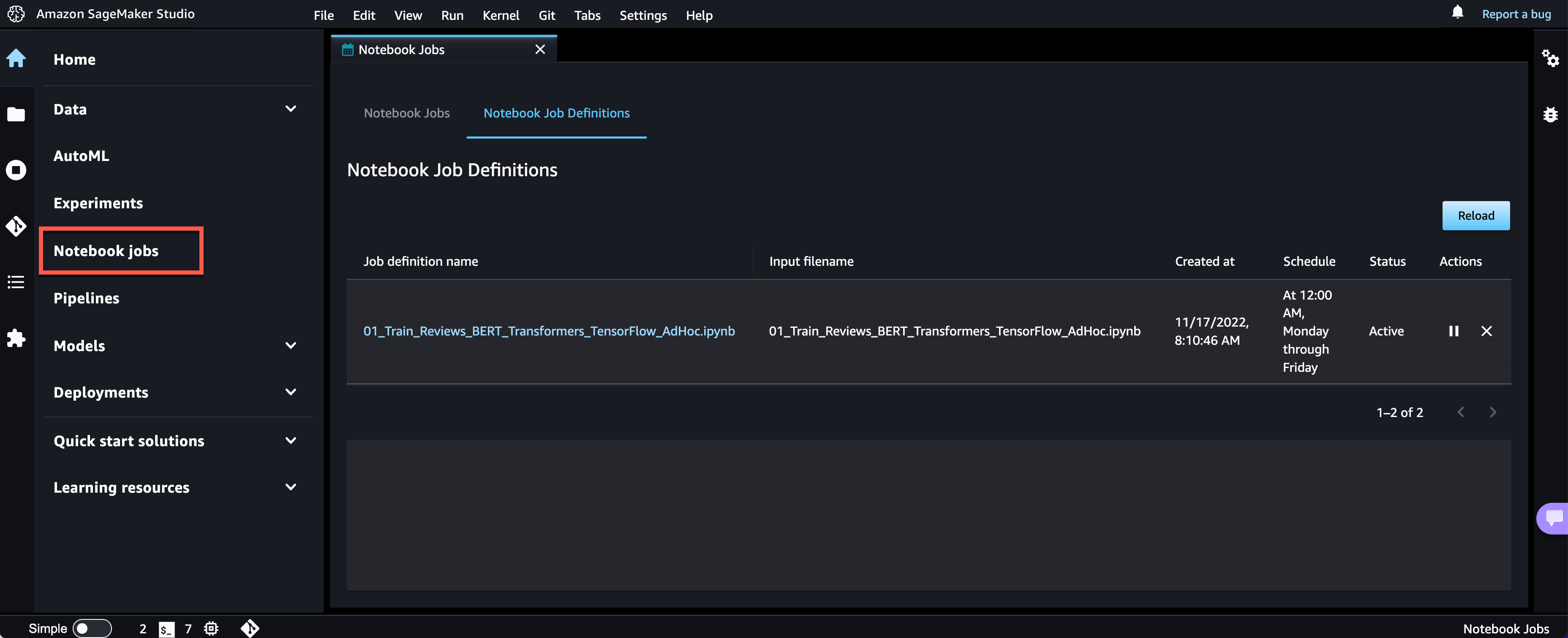
Se ha creado el trabajo de Notebook y puede revisar todas las definiciones de trabajo de Notebook en la interfaz de usuario.
Ya disponible
Las nuevas capacidades de notebook de Amazon SageMaker Studio ahora están disponibles en todas las regiones de AWS donde está disponible Amazon SageMaker Studio, excepto en las regiones de China de AWS.
En el momento del lanzamiento, la capacidad de preparación de datos integrada con tecnología de SageMaker Data Wrangler es compatible con las notebooks SageMaker Studio y las siguientes imágenes de kernel de notebook:
- Python 3 (Ciencia de datos) con Python 3.7
- Python 3 (Ciencia de datos 2.0) con Python 3.8
- Python 3 (Ciencia de datos 3.0) con Python 3.10
- Spark Analytics 1.0 y 2.0
Para obtener más información, visite Cuadernos de Amazon SageMaker.
¡Empiece a crear sus proyectos de aprendizaje automático con la próxima generación de portátiles de Amazon SageMaker hoy mismo!
— Antje