|
|
Amazon Neptune es un servicio de base de datos de gráficos completamente administrado que facilita la creación y ejecución de aplicaciones que funcionan con conjuntos de datos altamente conectados. Con Neptune, puede usar lenguajes de consulta de gráficos abiertos y populares para ejecutar consultas potentes que son fáciles de escribir y funcionan bien en datos conectados. Puede usar Neptune para casos de uso de gráficos, como motores de recomendación, detección de fraudes, gráficos de conocimiento, descubrimiento de fármacos y seguridad de red.
Neptune siempre se ha administrado por completo y maneja tareas que requieren mucho tiempo, como el aprovisionamiento, la aplicación de parches, la copia de seguridad, la recuperación, la detección de fallas y la reparación. Sin embargo, la administración de la capacidad de la base de datos para obtener un costo y rendimiento óptimos requiere que usted supervise y reconfigure la capacidad a medida que cambian las características de la carga de trabajo. Además, muchas aplicaciones tienen cargas de trabajo variables o impredecibles donde el volumen y la complejidad de las consultas de la base de datos pueden cambiar significativamente. Por ejemplo, una aplicación de gráficos de conocimiento para las redes sociales puede ver un aumento repentino en las consultas debido a la repentina popularidad.
Presentación de Amazon Neptune sin servidor
Hoy lo hacemos más fácil con el lanzamiento de Amazon Neptune Serverless. Neptune Serverless escala automáticamente a medida que cambian sus consultas y sus cargas de trabajo, ajustando la capacidad en incrementos detallados para proporcionar la cantidad justa de recursos de base de datos que su aplicación necesita. De esta forma, solo paga por la capacidad que utiliza. Puede usar Neptune Serverless para cargas de trabajo de desarrollo, prueba y producción y optimizar los costos de su base de datos en comparación con el aprovisionamiento para la capacidad máxima.
Con Neptune Serverless, puede implementar gráficos de forma rápida y rentable para sus aplicaciones modernas. Puede comenzar con un gráfico pequeño y, a medida que crece su carga de trabajo, Neptune Serverless escalará automáticamente y sin problemas sus bases de datos de gráficos para proporcionar el rendimiento que necesita. Ya no necesita administrar la capacidad de la base de datos y ahora puede ejecutar aplicaciones gráficas sin el riesgo de costos más altos por sobreaprovisionamiento o capacidad insuficiente por aprovisionamiento insuficiente.
Con Neptune Serverless, puede continuar usando los mismos lenguajes de consulta (Apache TinkerPop Gremlin, abrirCyphery RDF/SPARQL) y funciones (como instantáneas, secuencias, alta disponibilidad y clonación de bases de datos) ya disponibles en Neptune.
Veamos cómo funciona esto en la práctica.
Creación de una base de datos sin servidor de Amazon Neptune
En la consola de Neptune, elijo bases de datos en el panel de navegación y luego Crear base de datos. Para Tipo de motorYo selecciono sin servidor y entrar my-database como el Identificador de clúster de base de datos.

Ahora puedo configurar el rango de capacidad, expresado en Unidades de capacidad Neptune (NCU), que Neptune Serverless puede usar en función de mi carga de trabajo. Ahora puedo elegir una plantilla que configurará algunas de las siguientes opciones para mí. elijo el Producción plantilla que, de forma predeterminada, crea una réplica de lectura en una zona de disponibilidad diferente. los Desarrollo y Pruebas La plantilla optimizaría mis costos al no tener una réplica de lectura y brindar acceso a instancias de base de datos que brindan capacidad ampliable.

Para Conectividadutilizo mi VPC predeterminada y su grupo de seguridad predeterminado.

Finalmente, elijo Crear base de datos. Después de unos minutos, la base de datos está lista para usar. En la lista de bases de datos, elijo la identificador de base de datos para obtener el Escritor y Lector puntos finales que voy a usar más adelante para acceder a la base de datos.
Uso de Amazon Neptune sin servidor
No hay diferencia en la forma en que usa Neptune Serverless en comparación con una base de datos Neptune aprovisionada. Puedo usar cualquiera de los lenguajes de consulta admitidos por Neptune. Para este tutorial, elijo usar abrirCypherun lenguaje de consulta declarativo para gráficos de propiedades desarrollado originalmente por neo4j que fue de código abierto en 2015 y contribuyó a la proyecto openCypher.
Para conectarme a la base de datos, inicio una instancia Amazon Linux Amazon Elastic Compute Cloud (Amazon EC2) en la misma región de AWS y asocio el grupo de seguridad predeterminado y un segundo grupo de seguridad que me otorga acceso SSH.
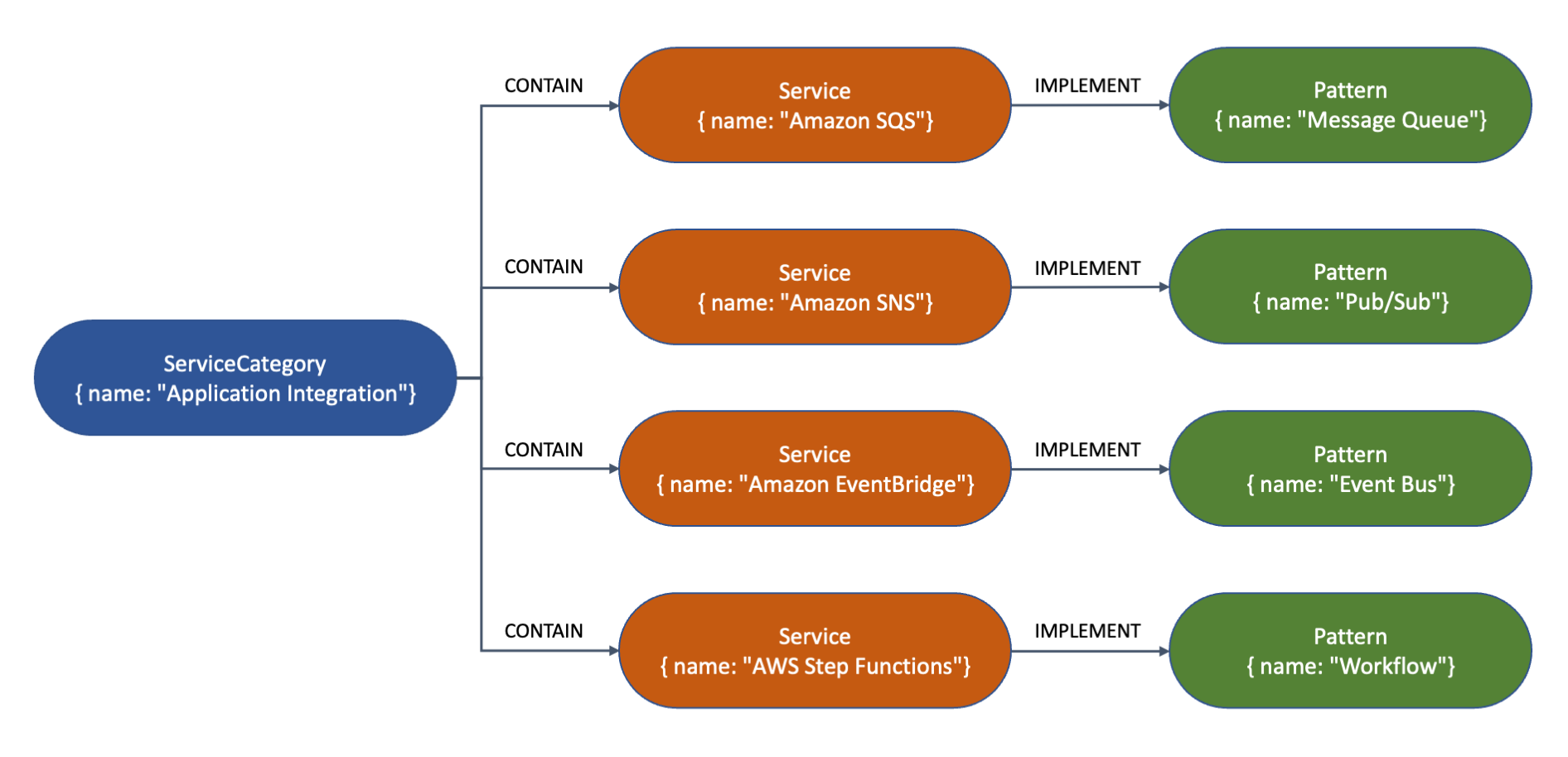
Con un gráfico de propiedades puedo representar datos conectados. En este caso, quiero crear un gráfico simple que muestre cómo algunos servicios de AWS forman parte de una categoría de servicio e implementan patrones de integración empresarial comunes.
yo suelo rizo para acceder a la Escritor openCypher punto final HTTPS y cree algunos nodos que representen patrones, servicios y categorías de servicios. Los siguientes comandos se dividen en varias líneas para mejorar la legibilidad.
Esta es una representación visual de los nodos y sus relaciones para el gráfico creado por el comando anterior. El tipo (como Service o Pattern) y propiedades (como name) se muestran dentro de cada nodo. Las flechas representan las relaciones (como CONTAIN o IMPLEMENT) entre los nodos.
Ahora, consulto la base de datos para obtener algunas ideas. Para consultar la base de datos, puedo usar un Escritor o un Lector punto final Primero, quiero saber el nombre del servicio que implementa el patrón «Message Queue». Observe cómo la sintaxis de openCypher se parece a la de SQL con MATCH en vez de SELECT.
{
"results" : [ {
"s.name" : "Amazon SQS"
} ]
}Utilizo la siguiente consulta para ver cuántos servicios hay en la categoría «Integración de aplicaciones». Esta vez uso el WHERE Cláusula para filtrar resultados.
{
"results" : [ {
"count(s)" : 4
} ]
}Hay muchas opciones ahora que tengo esta base de datos de gráficos en funcionamiento. Puedo agregar más datos (servicios, categorías, patrones) y más relaciones entre los nodos. Puedo concentrarme en mi aplicación y dejar que Neptune Serverless administre la capacidad y la infraestructura por mí.
Disponibilidad y precios
Amazon Neptune Serverless ya está disponible en las siguientes regiones de AWS: EE. UU. Este (Ohio, N. Virginia), EE. UU. Oeste (Norte de California, Oregón), Asia Pacífico (Tokio) y Europa (Irlanda, Londres).
Con Neptune Serverless, solo paga por lo que usa. La capacidad de la base de datos se ajusta para proporcionar la cantidad correcta de recursos que necesita en términos de unidades de capacidad de Neptune (NCU). Cada NCU es una combinación de aproximadamente 2 gibibytes (GiB) de memoria con la CPU y la red correspondientes. El uso de las NCU se factura por segundo. Para obtener más información, consulte la página de precios de Neptune.
Tener una base de datos de gráficos sin servidor abre muchas posibilidades nuevas. Para obtener más información, consulte la documentación de Neptune Serverless. ¡Háganos saber lo que construye con esta nueva capacidad!
Simplifique la forma en que trabaja con datos altamente conectados mediante Neptune Serverless.
— Danilo