¿Qué haría falta para que los robots humanoides y bípedos bailaran como Mick Jagger? De hecho, para algo más mundano, ¿qué se necesita para que simplemente se queden quietos? ¿Siéntate? ¿Caminar? ¿Se mueve en miles de otras formas que muchas personas dan por sentadas? El bipedalismo proporciona una versatilidad sin precedentes en un entorno diseñado por y para los seres humanos. Al mezclar y combinar una amplia gama de habilidades motoras básicas, desde caminar hasta saltar y mantener el equilibrio sobre un pie, las personas bailan, juegan fútbol, cargan objetos pesados y realizan otros movimientos complejos de alto nivel. Si los robots han de alcanzar su máximo potencial como tecnología de asistencia, el dominio de diversos movimientos bípedos es un requisito, no un lujo. Sin embargo, incluso la más simple de estas habilidades puede requerir una fina orquestación de docenas de articulaciones. La ingeniería sofisticada puede controlar parte de esta complejidad, pero dotar a los robots bípedos de la generalidad para hacer frente a nuestro mundo desordenado y débilmente estructurado, o un metaverso que se parece a él, requiere aprendizaje. Entrenar agentes de IA con morfología humanoide para igualar el desempeño humano en toda la diversidad del movimiento humano es uno de los mayores desafíos de la inteligencia física artificial. Debido a los caprichos de la experimentación con robots físicos, la investigación en esta dirección actualmente se realiza principalmente en simulación.
Desafortunadamente, involucra métodos computacionalmente intensivos, restringiendo efectivamente la participación a instituciones de investigación con grandes presupuestos de cómputo. En un esfuerzo por nivelar el campo de juego y hacer que esta área crítica de investigación sea más inclusiva, el grupo Robot Learning de Microsoft Research está lanzando MoCapAct, una gran biblioteca de modelos de control humanoides preentrenados junto con datos enriquecidos para entrenar nuevos. Esto permitirá la investigación avanzada sobre el control humanoide artificial con una fracción de los recursos informáticos que se requieren actualmente.
La razón por la que la investigación del control humanoide ha sido tan exigente desde el punto de vista computacional es sutil y, a primera vista, paradójica. La avenida destacada de aprender habilidades locomotoras se basa en usar captura de movimiento (MoCap) datos. MoCap es una técnica de animación ampliamente utilizada en la industria del entretenimiento durante décadas. Implica registrar el movimiento de varios puntos clave en el cuerpo de un actor humano, como los codos, los hombros y las rodillas, mientras el actor realiza una tarea de interés, como trotar. Por lo tanto, un clip de MoCap se puede considerar como un resumen muy conciso y preciso del videoclip de una actividad. Gracias a esto, se puede extraer información útil de los clips de MoCap con mucho menos cómputo que de los datos de entrenamiento ambiguos y de muchas más dimensiones en otras áreas importantes del aprendizaje automático, que se presenta en forma de videos, imágenes y texto. Además de esto, los datos de MoCap están ampliamente disponibles. repositorios como Conjunto de datos de captura de movimiento de CMU contiene horas de clips para casi cualquier movimiento común de un cuerpo humano, con visualizaciones de varios ejemplos que se muestran a continuación. ¿Por qué, entonces, es tan difícil hacer que los robots humanoides físicos y simulados imiten los movimientos de una persona?
La advertencia es que los clips MoCap no contienen todos la información necesaria para imitar los movimientos demostrados en un robot físico o en una simulación que modela fuerzas físicas. Solo nos muestran qué habilidad de movimiento. parece, no los movimientos musculares subyacentes que hicieron que los músculos del actor produjeran ese movimiento. Incluso si los sistemas MoCap registraran estas señales, no sería de mucha ayuda: los humanoides simulados y los robots reales suelen usar motores en lugar de músculos, que es una forma de articulación radicalmente diferente. No obstante, la actuación en humanoides artificiales también está impulsada por un tipo de señal de control. Los clips de MoCap son una valiosa ayuda para calcular estas señales de control, si se combinan con métodos adicionales de aprendizaje y optimización que utilizan los datos de MoCap como guía. El cuello de botella computacional que nuestro lanzamiento de MoCapAct pretende eliminar es creado exactamente por estos métodos, conocidos colectivamente como aprendizaje reforzado (RL). En la simulación, donde actualmente se centra gran parte de la investigación de locomoción de IA, RL puede recuperar la secuencia de entradas de control que lleva a un agente humanoide a través de la secuencia de poses de un clip de MoCap dado. Lo que resulta es un comportamiento de locomoción que es indistinguible del del clip. La disponibilidad de políticas de control para comportamientos básicos individuales aprendidos de clips de MoCap separados puede abrir las puertas para investigaciones de locomoción fascinantes, por ejemplo, en métodos para combinar estos comportamientos en una única red neuronal de «habilidades múltiples» y entrenar capacidades de locomoción de nivel superior cambiando entre ellos. Sin embargo, con miles de habilidades básicas de locomoción para aprender, el costoso enfoque de prueba y error de RL crea una enorme barrera de entrada en este camino de investigación. Es este problema de escalabilidad el que nuestro lanzamiento de conjunto de datos pretende abordar.
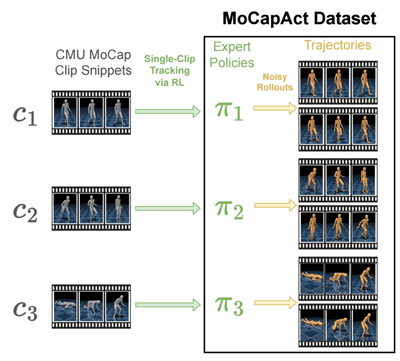
Nuestro conjunto de datos MoCapAct, diseñado para ser compatible con el muy popular dm_control entorno de simulación humanoide y la extensa Conjunto de datos de captura de movimiento de CMUsirve a la comunidad investigadora de dos maneras:
- Para cada uno de los más de 2500 fragmentos de clip MoCap de la Conjunto de datos de captura de movimiento de CMUproporciona una política de control «experta» entrenada por RL (representada como un modelo PyTorch) que permite dm_controlhumanoide simulado para recrear fielmente la habilidad representada en ese fragmento de clip, como se muestra en estos videos de los comportamientos de los expertos:
El entrenamiento de este zoológico modelo ha llevado el equivalente a 50 años en muchos equipos equipados con GPU. Azure NC6v2 máquinas virtuales (excluyendo el ajuste de hiperparámetros y otros experimentos necesarios): un testimonio del obstáculo computacional que MoCapAct elimina para otros investigadores.
- Para cada una de las políticas de habilidades entrenadas anteriores, MoCapAct proporciona un conjunto de trayectorias registradas generadas al ejecutar la política de control de esa habilidad en el agente humanoide de dm_control. Estas trayectorias se pueden considerar como clips MoCap de los expertos capacitados pero, a diferencia de los datos MoCap originales, contienen mediciones sensoriales de bajo nivel (p. ej., mediciones táctiles) y señales de control para el agente humanoide. A diferencia de los datos típicos de MoCap, estas trayectorias son adecuadas para aprender a igualar y mejorar las habilidades de los expertos a través de la imitación directa, una clase de técnicas mucho más eficiente que RL.
Damos dos ejemplos de cómo usamos el conjunto de datos MoCapAct.
Primero, entrenamos un jerárquico política basada en la primitivo motor neural probabilístico. Para lograr esto, combinamos las miles de políticas especializadas en clips de MoCapAct en una sola política que es capaz de ejecutar muchas habilidades diferentes. Este agente tiene un componente de alto nivel que toma tramas MoCap como entrada y genera una habilidad aprendida. El componente de bajo nivel toma la habilidad aprendida y la medición sensorial del humanoide como entrada y genera la acción motora.
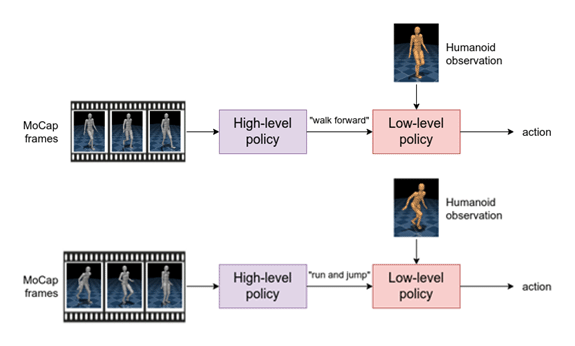
Esta estructura jerárquica ofrece un atractivo beneficio. Si mantenemos el componente de bajo nivel, podemos controlar al humanoide ingresando diferentes habilidades a la política de bajo nivel (por ejemplo, «caminar» en lugar de las acciones motoras correspondientes). Por lo tanto, podemos reutilizar la política de bajo nivel para aprender nuevas tareas de manera eficiente.
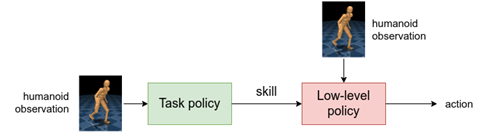
A la luz de eso, reemplazamos la política de alto nivel con una política de tarea que luego se entrena para dirigir la política de bajo nivel hacia el logro de alguna tarea. Como ejemplo, entrenamos una política de tareas para que el humanoide alcance un objetivo. Tenga en cuenta que el humanoide usa muchas habilidades de bajo nivel, como correr, girar y esquivar.
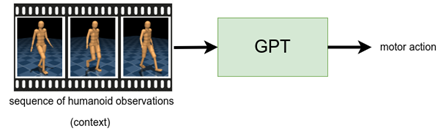
Nuestro segundo ejemplo se centra en finalización de movimientoque se inspira en la tarea de completar oraciones. Aquí, usamos el arquitectura GPT, que acepta una secuencia de mediciones sensoriales (el «contexto») y genera una acción motora. Entrenamos una política de control para tomar un segundo de mediciones sensoriales del conjunto de datos y generar las acciones motoras correspondientes del experto especializado. Luego, antes de ejecutar la política en nuestro humanoide, primero generamos un «prompt» (humanoide rojo en los videos) ejecutando un experto especializado durante un segundo. Luego, dejamos que la política controle al humanoide (humanoide de bronce en los videos), en cada paso de tiempo, donde constantemente toma el segundo anterior de mediciones sensoriales y predice las acciones motoras. Encontramos que esta política puede repetir de manera confiable el movimiento subyacente del clip, que se demuestra en los primeros dos videos. En otros clips de MoCap, encontramos que la política puede desviarse del clip subyacente de una manera plausible, como en el tercer video, donde el humanoide pasa de dar un paso al costado a caminar hacia atrás.
Además del conjunto de datos, también liberamos el código utilizados para generar las políticas y los resultados. Esperamos que la comunidad pueda aprovechar nuestro conjunto de datos y trabajar para realizar una investigación increíble sobre el control de los robots humanoides.
Nuestro papel está disponible aquí. Puedes leer más en nuestra página web.
Los datos utilizados en este proyecto se obtuvieron de mocap.cs.cmu.edu.
La base de datos se creó con fondos de NSF EIA-0196217.

