
|
|
Hoy, me complace anunciar que Amazon S3 Vectors ya está disponible de forma generalizada con capacidades de rendimiento de nivel de producción y escala significativamente mayores. S3 Vectors es el primer almacenamiento de objetos en la nube con soporte nativo para almacenar y consultar datos vectoriales. Puede usarlo para ayudarlo a reducir el costo total de almacenar y consultar vectores hasta en un 90% en comparación con soluciones de bases de datos vectoriales especializadas.
Desde que anunciamos la vista previa de S3 Vectors en julio, me ha impresionado la rapidez con la que adoptaron esta nueva capacidad para almacenar y consultar datos vectoriales. En poco más de cuatro meses, creó más de 250 000 índices vectoriales e ingirió más de 40 mil millones de vectores, realizando más de mil millones de consultas (al 28 de noviembre).
Ahora puede almacenar y buscar hasta 2 mil millones de vectores en un solo índice, es decir, hasta 20 billones de vectores en un grupo de vectores y un aumento de 40 veces desde los 50 millones por índice durante la vista previa. Esto significa que puede consolidar todo su conjunto de datos vectoriales en un solo índice, eliminando la necesidad de fragmentarlo en varios índices más pequeños o implementar una lógica de federación de consultas compleja.
Se ha optimizado el rendimiento de las consultas. Las consultas poco frecuentes siguen arrojando resultados en menos de un segundo, y las consultas más frecuentes ahora generan latencias de alrededor de 100 ms o menos, lo que lo hace muy adecuado para aplicaciones interactivas como la IA conversacional y los flujos de trabajo de múltiples agentes. También puede recuperar hasta 100 resultados de búsqueda por consulta, en comparación con los 30 anteriores, lo que proporciona un contexto más completo para aplicaciones de recuperación de generación aumentada (RAG).
El rendimiento de escritura también ha mejorado sustancialmente, con soporte para hasta 1000 transacciones PUT por segundo cuando se transmiten actualizaciones de un solo vector a sus índices, lo que ofrece un rendimiento de escritura significativamente mayor para lotes pequeños. Este mayor rendimiento admite cargas de trabajo en las que se deben poder buscar nuevos datos de inmediato, lo que le ayuda a ingerir pequeños corpus de datos rápidamente o manejar muchas fuentes simultáneas que escriben simultáneamente en el mismo índice.
La arquitectura totalmente sin servidor elimina la sobrecarga de infraestructura: no hay infraestructura que configurar ni recursos que aprovisionar. Paga por lo que usa mientras almacena y consulta vectores. Este almacenamiento preparado para IA le brinda acceso rápido a cualquier cantidad de datos vectoriales para respaldar su ciclo de vida completo de desarrollo de IA, desde la experimentación inicial y la creación de prototipos hasta implementaciones de producción a gran escala. S3 Vectors ahora proporciona la escala y el rendimiento necesarios para cargas de trabajo de producción en agentes de IA, inferencia, búsqueda semántica y aplicaciones RAG.
Dos integraciones clave que se lanzaron en la versión preliminar ahora están disponibles de forma generalizada. Puede utilizar S3 Vectors como motor de almacenamiento de vectores para la base de conocimientos de Amazon Bedrock. En particular, puede usarlo para crear aplicaciones RAG con escala y rendimiento de nivel de producción. Además, la integración de S3 Vectors con Amazon OpenSearch ahora está disponible de forma generalizada, por lo que puede utilizar S3 Vectors como capa de almacenamiento de vectores mientras utiliza OpenSearch para capacidades de búsqueda y análisis.
Ahora puede usar S3 Vectors en 14 regiones de AWS, expandiéndose desde cinco regiones de AWS durante la vista previa.
Veamos cómo funciona.
En esta publicación, demuestro cómo usar S3 Vectors a través de la consola y la CLI de AWS.
Primero, creo un depósito de vectores S3 y un índice.
echo "Creating S3 Vector bucket..."
aws s3vectors create-vector-bucket \
--vector-bucket-name "$BUCKET_NAME"
echo "Creating vector index..."
aws s3vectors create-index \
--vector-bucket-name "$BUCKET_NAME" \
--index-name "$INDEX_NAME" \
--data-type "float32" \
--dimension "$DIMENSIONS" \
--distance-metric "$DISTANCE_METRIC" \
--metadata-configuration "nonFilterableMetadataKeys=AMAZON_BEDROCK_TEXT,AMAZON_BEDROCK_METADATA"La métrica de dimensión debe coincidir con la dimensión del modelo utilizado para calcular los vectores. La métrica de distancia le indica al algoritmo que calcule la distancia entre vectores. Soporte de Vectores S3 coseno y euclidiano distancias.
También puedo usar la consola para crear el depósito. Hemos agregado la capacidad de configurar parámetros de cifrado en el momento de la creación. De forma predeterminada, los índices utilizan el cifrado a nivel de depósito, pero puedo anular el cifrado a nivel de depósito en el nivel de índice con una clave personalizada de AWS Key Management Service (AWS KMS).
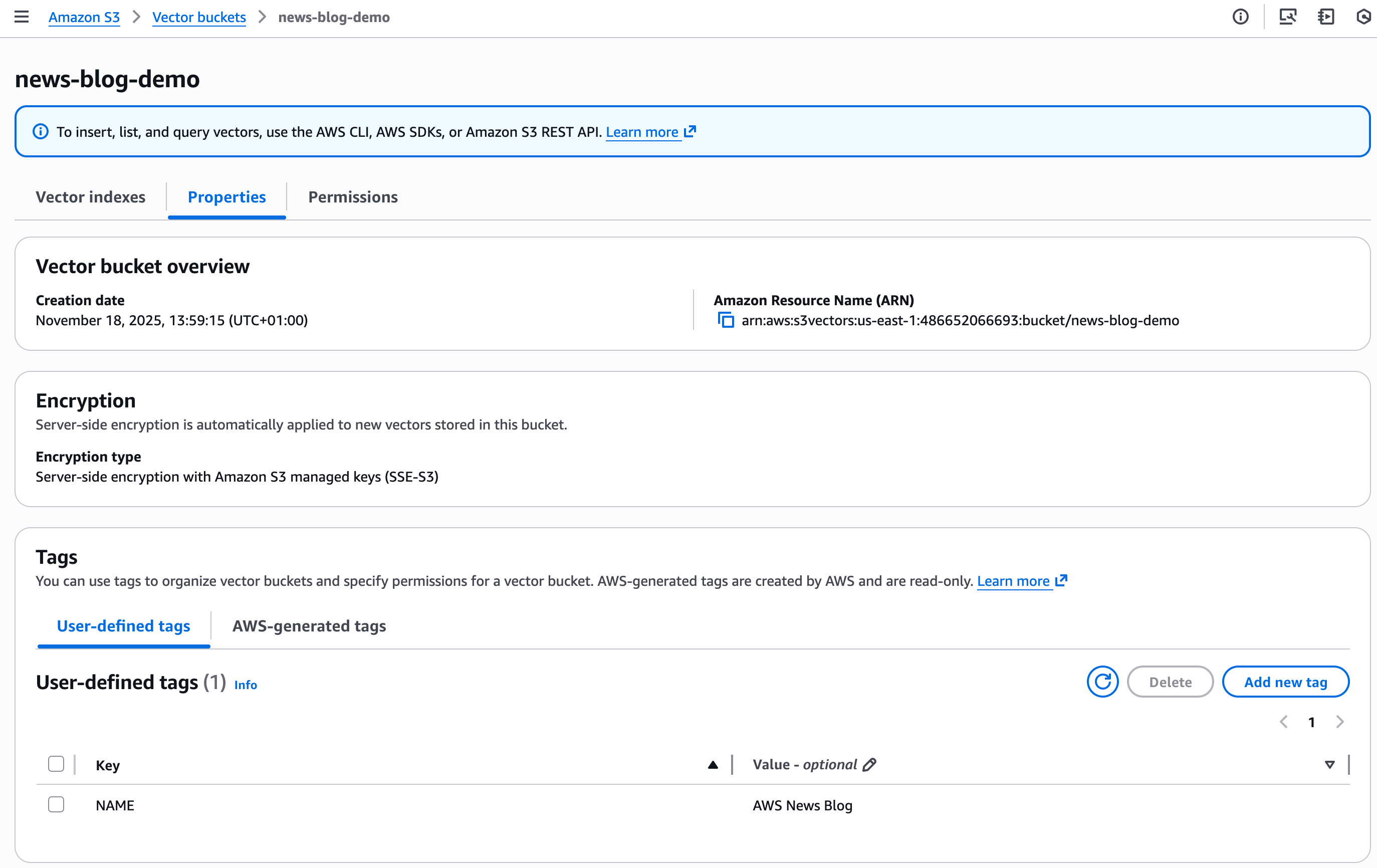
También puedo agregar etiquetas para el depósito de vectores y el índice de vectores. Las etiquetas en el índice de vectores ayudan con el control de acceso y la asignación de costos.
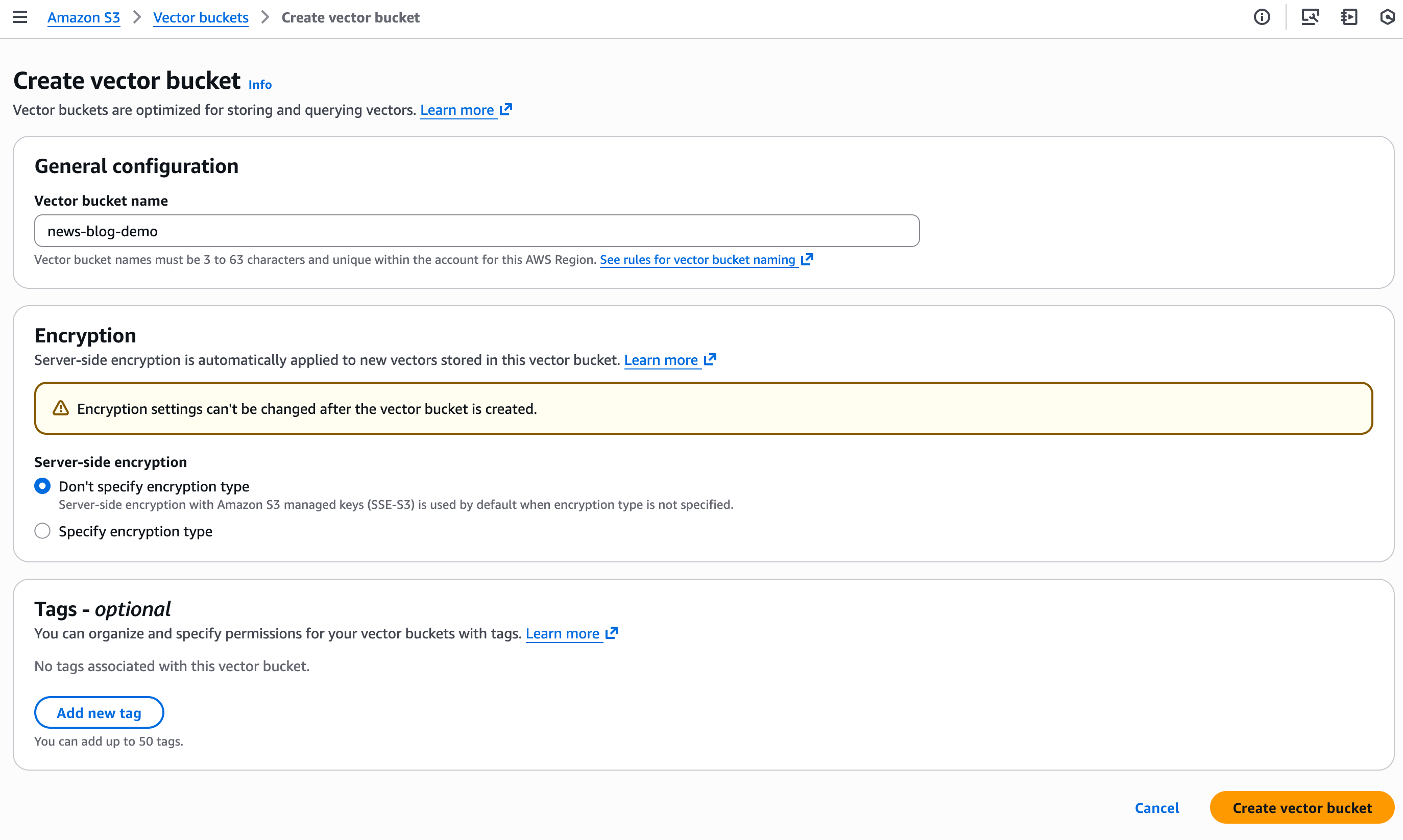
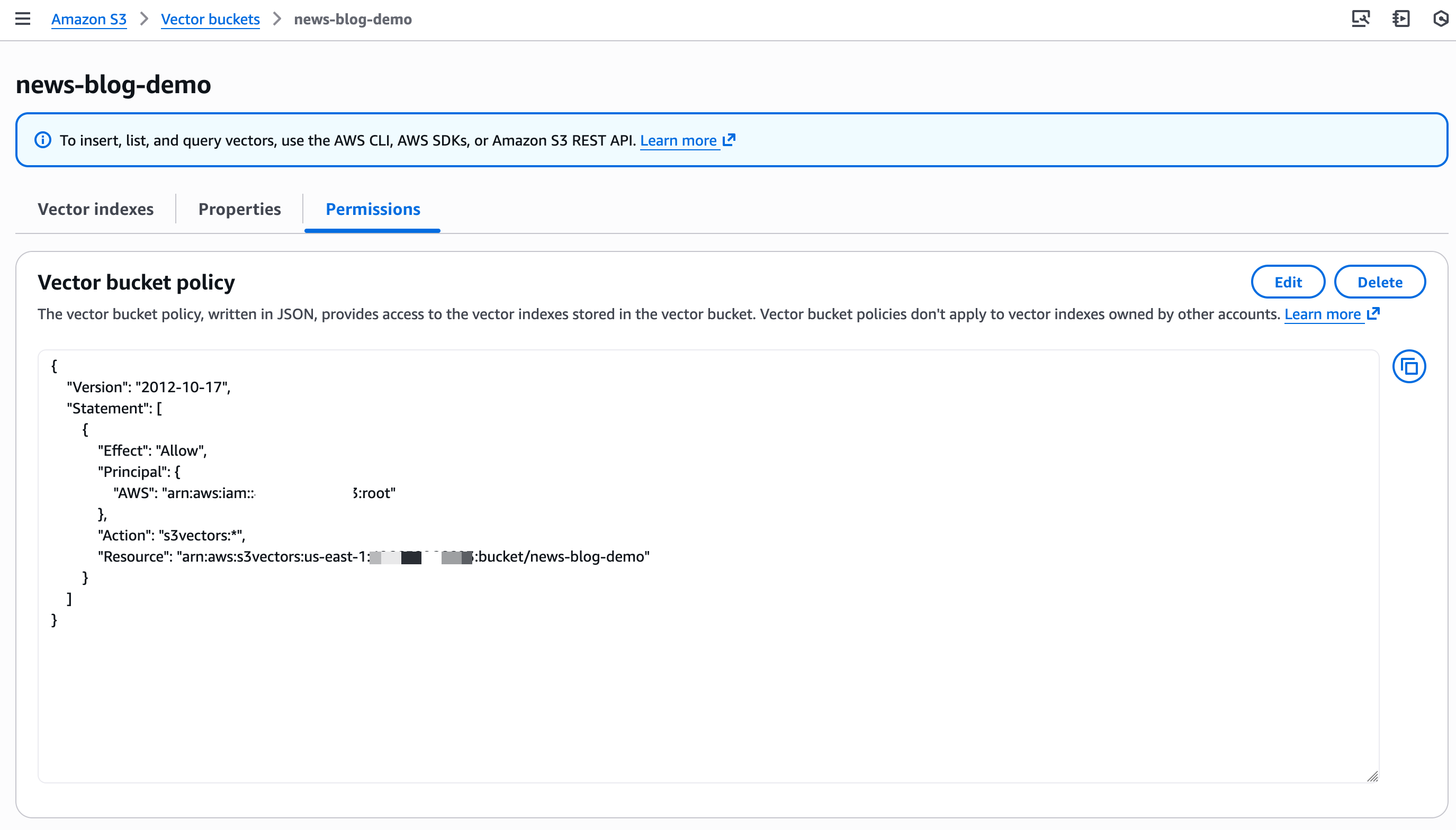
Y ahora puedo manejar Propiedades y Permisos directamente en la consola.
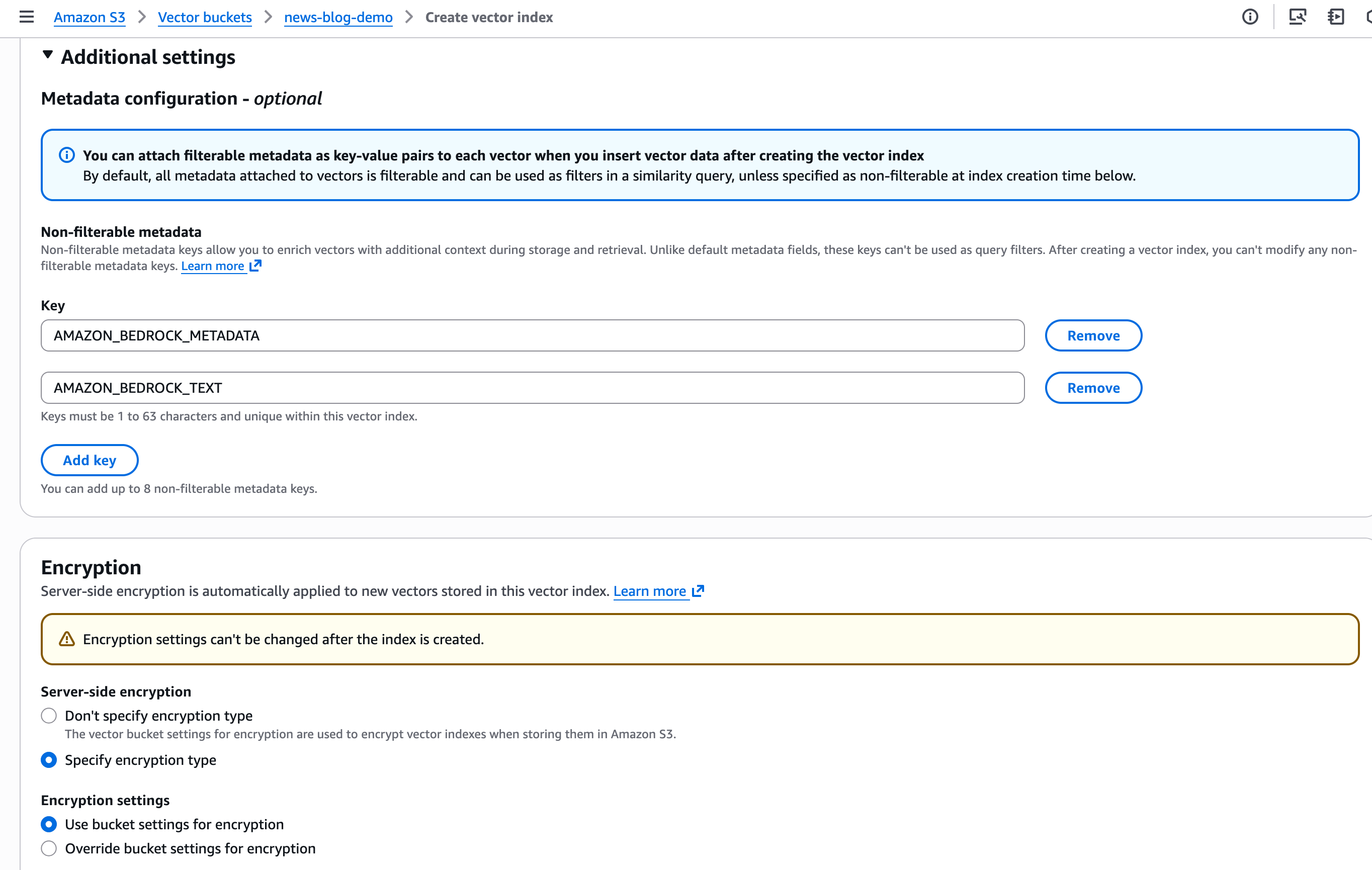
Del mismo modo, defino Metadatos no filtrables y lo configuro Cifrado parámetros para el índice vectorial.
A continuación, creo y almaceno las incrustaciones (vectores). Para esta demostración, utilizo mi compañero constante: la Guía de estilo de AWS. Este es un documento de 800 páginas que describe cómo escribir publicaciones, documentación técnica y artículos en AWS.
Utilizo Amazon Bedrock Knowledge Bases para ingerir el documento PDF almacenado en un depósito S3 de uso general. Amazon Bedrock Knowledge Bases lee el documento y lo divide en partes llamadas fragmentos. Luego, calcula las incrustaciones para cada fragmento con el modelo Amazon Titan Text Embeddings y almacena los vectores y sus metadatos en mi depósito de vectores recién creado. Los pasos detallados para ese proceso están fuera del alcance de esta publicación, pero puedes leer las instrucciones en la documentación.
Al consultar vectores, puede almacenar hasta 50 claves de metadatos por vector, con hasta 10 marcadas como no filtrables. Puede utilizar las claves de metadatos filtrables para filtrar los resultados de la consulta en función de atributos específicos. Por lo tanto, puede combinar la búsqueda de similitud de vectores con condiciones de metadatos para limitar los resultados. También puede almacenar más metadatos no filtrables para obtener información contextual más amplia. Amazon Bedrock Knowledge Bases calcula y almacena los vectores. También agrega metadatos de gran tamaño (la parte del texto original). Excluyo estos metadatos del índice de búsqueda.
Existen otros métodos para ingerir sus vectores. Puedes probar el CLI de inserción de vectores S3una herramienta de línea de comandos que le ayuda a generar incrustaciones utilizando Amazon Bedrock y almacenarlas en S3 Vectors mediante comandos directos. También puede utilizar S3 Vectors como motor de almacenamiento de vectores para OpenSearch.
Ahora estoy listo para consultar mi índice de vectores. Imaginemos que me pregunto cómo escribir «código abierto». ¿Es “código abierto”, con un guión, o “código abierto” sin guión? ¿Debo usar mayúsculas o no? Quiero buscar en las secciones relevantes de la Guía de estilo de AWS relativas al «código abierto».
# 1. Create embedding request
echo '{"inputText":"Should I write open source or open-source"}' | base64 | tr -d '\n' > body_encoded.txt
# 2. Compute the embeddings with Amazon Titan Embed model
aws bedrock-runtime invoke-model \
--model-id amazon.titan-embed-text-v2:0 \
--body "$(cat body_encoded.txt)" \
embedding.json
# Search the S3 Vectors index for similar chunks
vector_array=$(cat embedding.json | jq '.embedding') && \
aws s3vectors query-vectors \
--index-arn "$S3_VECTOR_INDEX_ARN" \
--query-vector "{\"float32\": $vector_array}" \
--top-k 3 \
--return-metadata \
--return-distance | jq -r '.vectors[] | "Distance: \(.distance) | Source: \(.metadata."x-amz-bedrock-kb-source-uri" | split("/")[-1]) | Text: \(.metadata.AMAZON_BEDROCK_TEXT[0:100])..."'El primer resultado muestra este JSON:
{
"key": "348e0113-4521-4982-aecd-0ee786fa4d1d",
"metadata": {
"x-amz-bedrock-kb-data-source-id": "0SZY6GYPVS",
"x-amz-bedrock-kb-source-uri": "s3://sst-aws-docs/awsstyleguide.pdf",
"AMAZON_BEDROCK_METADATA": "{\"createDate\":\"2025-10-21T07:49:38Z\",\"modifiedDate\":\"2025-10-23T17:41:58Z\",\"source\":{\"sourceLocation\":\"s3://sst-aws-docs/awsstyleguide.pdf\"",
"AMAZON_BEDROCK_TEXT": "[redacted] open source (adj., n.) Two words. Use open source as an adjective (for example, open source software), or as a noun (for example, the code throughout this tutorial is open source). Don't use open-source, opensource, or OpenSource. [redacted]",
"x-amz-bedrock-kb-document-page-number": 98.0
},
"distance": 0.63120436668396
}Encuentra la sección correspondiente en la Guía de estilo de AWS. Debo escribir “código abierto” sin guión. Incluso recuperó el número de página del documento original para ayudarme a cotejar la sugerencia con el párrafo relevante del documento fuente.
una cosa mas
S3 Vectors también ha ampliado sus capacidades de integración. Ahora puede utilizar AWS CloudFormation para implementar y administrar sus recursos vectoriales, AWS PrivateLink para conectividad de red privada y etiquetado de recursos para asignación de costos y control de acceso.
Precios y disponibilidad
S3 Vectors ahora está disponible en 14 regiones de AWS, agregando Asia Pacífico (Mumbai, Seúl, Singapur, Tokio), Canadá (Central) y Europa (Irlanda, Londres, París, Estocolmo) a las cinco regiones existentes desde la versión preliminar (EE.UU. Este (Ohio, N. Virginia), EE.UU. Oeste (Oregón), Asia Pacífico (Sídney) y Europa (Frankfurt)).
El precio de Amazon S3 Vectors se basa en tres dimensiones. precio de venta se calcula en función de los GB lógicos de vectores que carga, donde cada vector incluye sus datos, metadatos y clave del vector lógico. Costos de almacenamiento están determinados por el almacenamiento lógico total en sus índices. Cargos de consulta incluya un cargo por API más un cargo de $/TB según el tamaño de su índice (excluidos los metadatos no filtrables). A medida que su índice supera los 100.000 vectores, se beneficia de un precio más bajo de $/TB. Como de costumbre, la página de precios de Amazon S3 tiene los detalles.
Para comenzar con S3 Vectors, visite la consola de Amazon S3. Puede crear índices vectoriales, comenzar a almacenar sus incrustaciones y comenzar a crear aplicaciones de IA escalables. Para obtener más información, consulte la Guía del usuario de Amazon S3 o la Referencia de comandos de la AWS CLI.
Espero ver lo que construye con estas nuevas capacidades. Por favor comparta sus comentarios a través de AWS re: Publicar o sus contactos habituales de AWS Support.
